传统的DQN有两点局限性: 1. 经验数据存储的内存有限。 2. 需要完整的观测信息。为了解决上述两个问题,设计了DRQN算法,将DQN中的全连接层替换为LSTM网络。当时用部分观测数据训练模型,使用完全观测数据评估模型时,模型的效果与观测数据的完整性有关。如果反过来,当使用完全观测数据进行训练,使用部分观测数据进行评估时,DRQN的效果下降小于DQN。循环网络在观测质量变化的情况下,具有更强的适应性。
摘要
深度强化学习产生了复杂任务的熟练控制器。然而,这些控制器的内存有限,并且依赖于能够在每个决策点感知整个游戏屏幕。为了解决这些缺点,本文研究了通过使用递归 LSTM 替换第一个卷积后完全连接层来增加深Q网络(DQN)的递归性的效果。由此产生的深度循环Q网络(DRQN)虽然在每个时间步只能看到一个帧,但它成功地通过时间整合了信息,并在标准Atari游戏和部分观察到的具有闪烁游戏屏幕的等价物上复制了DQN的性能。此外,当使用部分观察值进行培训并使用增量更完整的观察值进行评估时,DRQN的性能根据可观察性进行衡量。相反,当使用完全观察进行培训并使用部分观察进行评估时,DRQN的性能下降幅度小于DQN。因此,考虑到相同的历史长度,重现性是在DQN的输入层中叠加帧历史的一种可行的替代方法,虽然重现性在学习玩游戏时没有系统优势,但如果观察质量发生变化,重现性网络可以更好地适应评估时间。
算法
作者采用Hochreiter 和 Schmidhuber 1997年提出来的Long Short Term Memory (LSTM)结合DQN来解决这个部分可观测的问题。
其网络结构如下所示: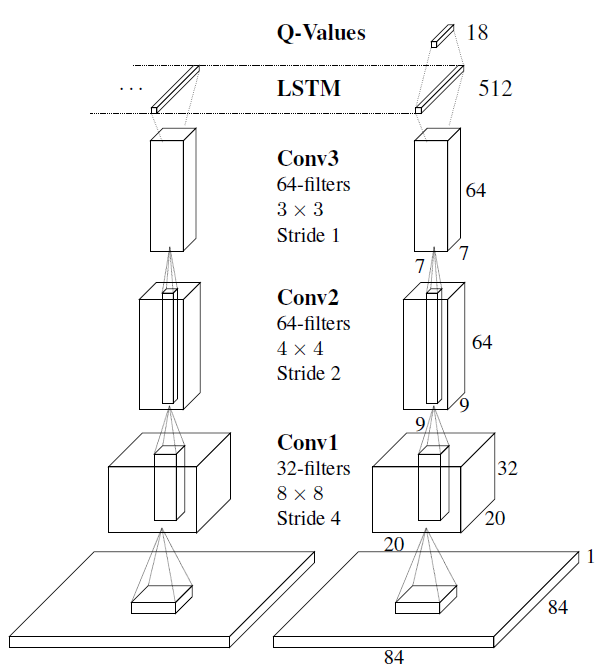
由于网络里面有LSTM,作者主要考虑了两种更新方式:Bootstrapped Sequential Updates和Bootstrapped Random Updates。
- Bootstrapped Sequential Updates:每次更新一个Episode,从头到尾,整个序列LSTM走完。
- Bootstrapped Random Updates:从Episode中随机抽取一个片段出来更新。
这两种更新方式的区别在于隐含状态是否清零。每个Episode更新的话能学到更多的东西,而随机的话更符合DQN中随机采样的思想。这两种方法的实验结果是非常相似的。作者文中采用的是随机采样的方式,期望它具有更强的泛化能力。
总结
在部分可观情况下MDP变为POMDP(部分可观马尔可夫决策过程)。在POMDP中,如果对DQN引入RNN(循环神经网络)来处理不完全观测将会取得较好的效果。DQRN相对于DQN能够更好的处理缺失的信息。
keypoints:
- DQN+LSTM
- Bootstrapped Random Updates
- Flickering Atari Games
参考
- 附:强化学习——DRQN分析详解
- 【5分钟 Paper】DRQN
- DRQN—笔记
- [强化学习论文笔记(3)]:DRQN
- 论文阅读(DRQN):Deep Recurrent Q-Learning for Partially Observable MDPs
About

若有收获,就点个赞吧
0 人点赞
