这篇文章是将 DQN 扩展到分散式的多智能体强化学习环境中,使其能够去处理高维复杂的环境。
摘要
多智能体系统大多出现在社会、经济和政治情景下。本文将 google deepmind 提出的深度 Q 学习网络体系结构推广到多智能体环境,研究了经典视频游戏 pong 中由独立深度 Q 网络控制的两个智能体之间的相互作用。通过操作经典的乒乓奖励方案,我们展示了竞争和协作行为是如何出现的。有竞争力的代理人学会了高效率地玩耍和得分。根据协作奖励方案训练的智能体找到一个最佳策略,以保持球在游戏中尽可能长。我们还描述了从竞争到合作行为的过程。本文的工作表明,深度 Q 网络可以成为研究高度复杂环境下多代理系统分散学习的实用工具
算法
多智能体环境中,状态转移和奖励函数都是受到所有智能体的联合动作的影响的。对于多智能体中的某个智能体来说,它的动作值函数是依据其它智能体采取什么动作才能确定的。因此对于一个单智能体来说它需要去了解其它智能体的学习情况。这篇文章是将 DQN 扩展到分散式的多智能体强化学习环境中,使其能够去处理高维复杂的环境。
作者采用的环境是 Atari 的 Pong 环境。作者基于不同的奖励函数设计来实现不同的多智能体环境。在竞争环境下,智能体期望去获取比对方更多的奖励。在合作的环境下,智能体期望去寻找到一个最优的策略去保持上图中的白色小球一直在游戏中存在下去。
为了测试分散式 DQN 算法的性能,作者只通过奖励函数的设计就构建出来了不同的多智能体范式环境:
- 完全竞争式:胜利方奖励+1,失败方奖励-1,是一个零和博弈。
- 完全合作式:在这个环境设定下,我们期望这个白色小球在环境中存在的时间越长越好,如果一方失去了球,则两方的奖励都是-1。
- 非完全竞争式:在完全竞争和完全合作式中,失去小球的一方奖励都式-1,对于胜利一方,作者设置一个系数
![📃[IQL]Multiagent Cooperation and Competition with Deep Reinforcement Learning - 图1](/uploads/projects/crazyalltnt@rl-paper/85a40ad0c147b84b1a1a68d2ade3b2f8.svg) 来看参数的改变对实验结果的影响。
来看参数的改变对实验结果的影响。
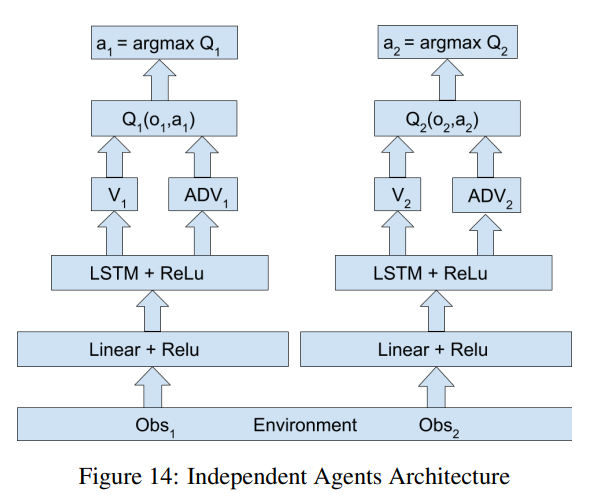
IQL(Independent Q-Learning) 算法中将其余智能体直接看作环境的一部分,也就是对于每个智能体都是在解决一个单智能体任务,很显然,由于环境中存在智能体,因此环境是一个非稳态的,这样就无法保证收敛性了,并且智能体会很容易陷入无止境的探索中,但是在工程实践上,效果还是比较可以的。
参考
About

若有收获,就点个赞吧
0 人点赞
