- 选举过程
- 数据一致性
- 1、数据到达Leader节点前,Leader挂了
- 2、Leader收到数据,但是未同步到Follower,Leader挂了
- 3、Leader收到数据,并同步到所有Follower,但Leader还未收到响应就挂了
- 4、数据到达 Leader 节点,成功复制到 Follower 部分节点,但还未向 Leader 响应接收
- 5、数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在 Leader 处于已提交状态,但在 Follower 处于未提交状态
- 6、数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在所有节点都处于已提交状态,但还未响应 Client
- 7、网络分区导致的脑裂情况,出现双 Leader
- 集群变化
Etcd是kubernetes集群中的重度组件,所有的状态信息等都保存在etcd中,而etcd内部就是采用raft来作为一致性的算法。
选举过程
在由raft协议组成的集群有三个角色:
- Leader(领袖)
- Follower(群众)
- Candidate(候选人)
一个集群由一个Leader和多个Follower组成,其中一个集群中有且仅有一个Leader,如果出现多个Leader,那么就会出现脑裂的想象(后文再介绍)。
既然一个集群只能有一个Leader,那么这个Leader是如何产生的呢?我们先通过一个通俗的例子来说说。
我们知道M国是一个”民主自由”的社会,他们的总统都是通过民众选举而来。假设M国现在没有总统,要进行大选了,参与者这时候就会从群众变为候选人,候选人就会去到处拉票,在选举结束后,票数最多者获胜,当有一位胜出后,其他人就会从候选人重新变为群众,如果某一天总统消失了,群龙不能无首,这时候就会重新进行下一轮选举。当然,如果总统一直存在并保持活跃,就不会换任。
raft的选举机制和上面的例子高度吻合,我们先看一副图: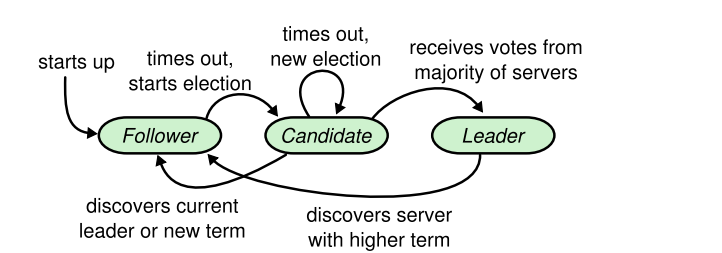
光看图并不那么清晰,结合下面具体步骤你就焕然大悟了。
- 在初始化阶段,集群内节点都是群众(Follower),在一段时间内没有收到Leader的心跳检测,就会从Follower变为Candidate。
- 假如先自己投一票,然后给其他节点发送消息进行拉票,等待它们回复。
在这个过程中就会有三种情况:
(1)、票数过半(包含自己的一票),就会成为Leader,其他节点重新成为Follower。
(2)、被告知已经有Leader了(也就是其他节点票数过半),自己主动降级为Follower。
(3)、票数未过半,也没有收到被告知已有Leader,那么就会进入下一轮投票。
注意:每个候选人(Candidate)只有1票。
我们以一组简单的组图再次说明,这里以A节点为第一人称介绍 :
(1)、A成为Candidate后,向B和C发送消息进行拉票,如下: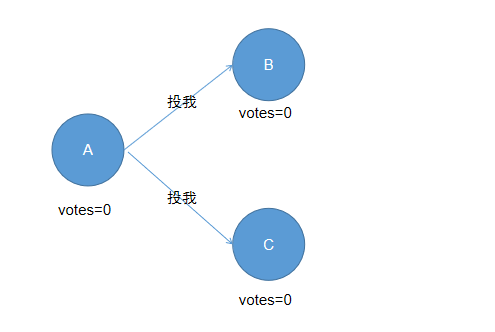
(2)、A收到的票数过半,成为Leader,有下面两种情况的票数: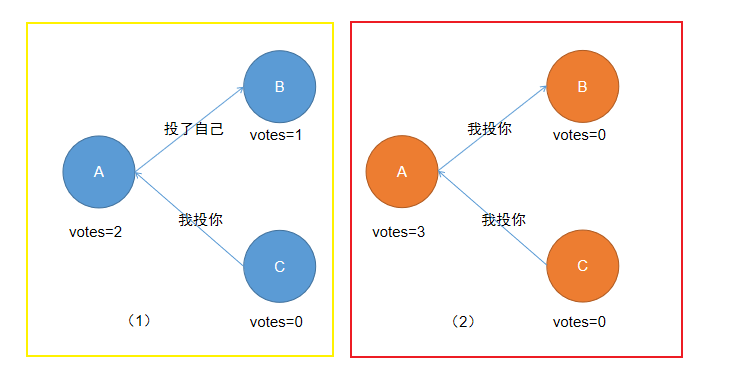
(3)、A收到已经有节点成为Leader,这里可能是B,也可能是C,我以B为例,如下: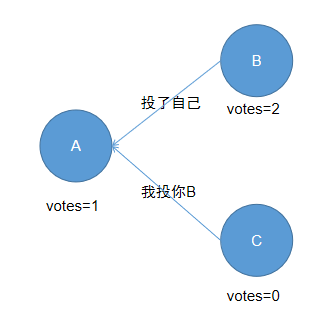
(4)、A未收到已经有节点成为Leader,票数也未过半,如下: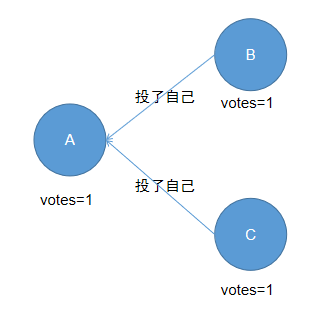
上面是站在候选人的角度来简单说明了一下选举的过程,那么站在投票者的角度,如何决定把票投给谁呢?这里有一下约束。
- 在一个任期内,单个节点只能投1票。
- 候选人所知道的信息不能比自己少。
- 先来先得。
当有一个节点成为Leader后,新的Leader就会立即向其他节点发送通知,宣布主权,避免其他节点触发新一轮的选举。之后,Leader会定期向Follower发送心跳检测以稳固自己的统治地位,如果Follower在一段时间之内未收到Leader的消息,则认为Leader已经挂了,就会触发进行下一轮的选举,前任Leader恢复后,会成为Follower。
数据一致性
以下内容摘自mindwind
Raft 协议强依赖 Leader 节点的可用性来确保集群数据的一致性。数据的流向只能从 Leader 节点向 Follower 节点转移。当 Client 向集群 Leader 节点提交数据后,Leader 节点接收到的数据处于未提交状态(Uncommitted),接着 Leader 节点会并发向所有 Follower 节点复制数据并等待接收响应,确保至少集群中超过半数节点已接收到数据后再向 Client 确认数据已接收。一旦向 Client 发出数据接收 Ack 响应后,表明此时数据状态进入已提交(Committed),Leader 节点再向 Follower 节点发通知告知该数据状态已提交。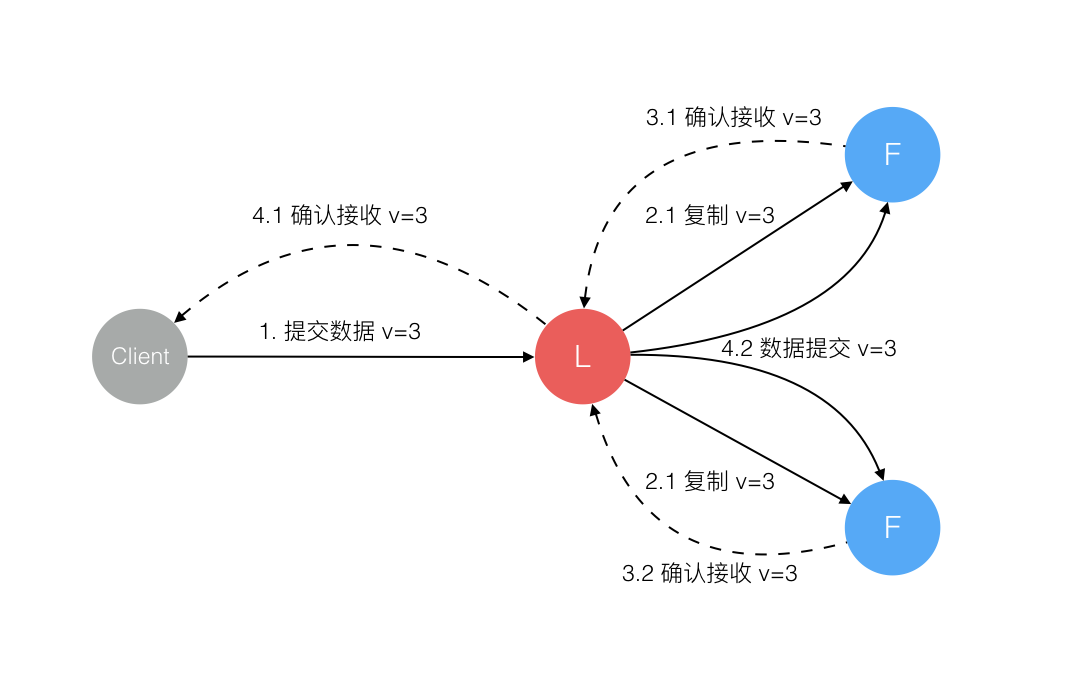
在这个过程中,主节点可能在任意阶段挂掉,看下 Raft 协议如何针对不同阶段保障数据一致性的。
1、数据到达Leader节点前,Leader挂了
这种情况,由于Leader并未收到数据,Client端会收到超时或者失败,可以选择重发或者放弃,如果重发,新Leader选举出来后,重发则会成功。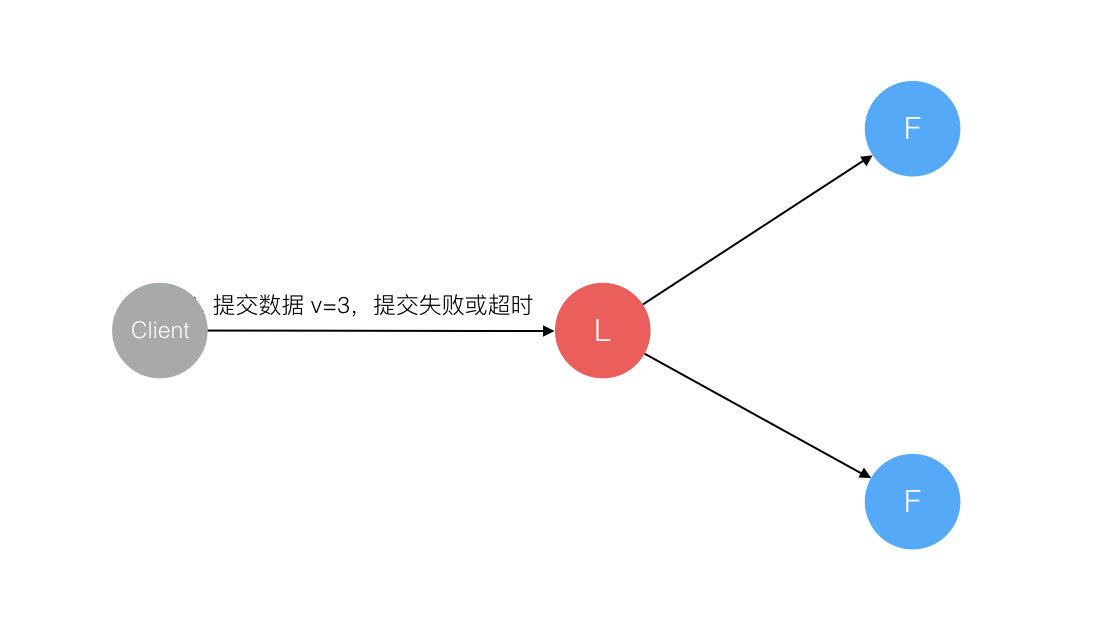
2、Leader收到数据,但是未同步到Follower,Leader挂了
这种情况下,Leader虽然接收到了数据,但是并未同步到Follower,此时数据会未提交状态。Client会因为收不到ACK而尝试安全重发,由于Follower上并没有上次的数据,所以在新Leader出来后可直接接收数据处理成功。上一任Leader在恢复后会成为Follower,强制同步新Leader数据,和Leader保持一致。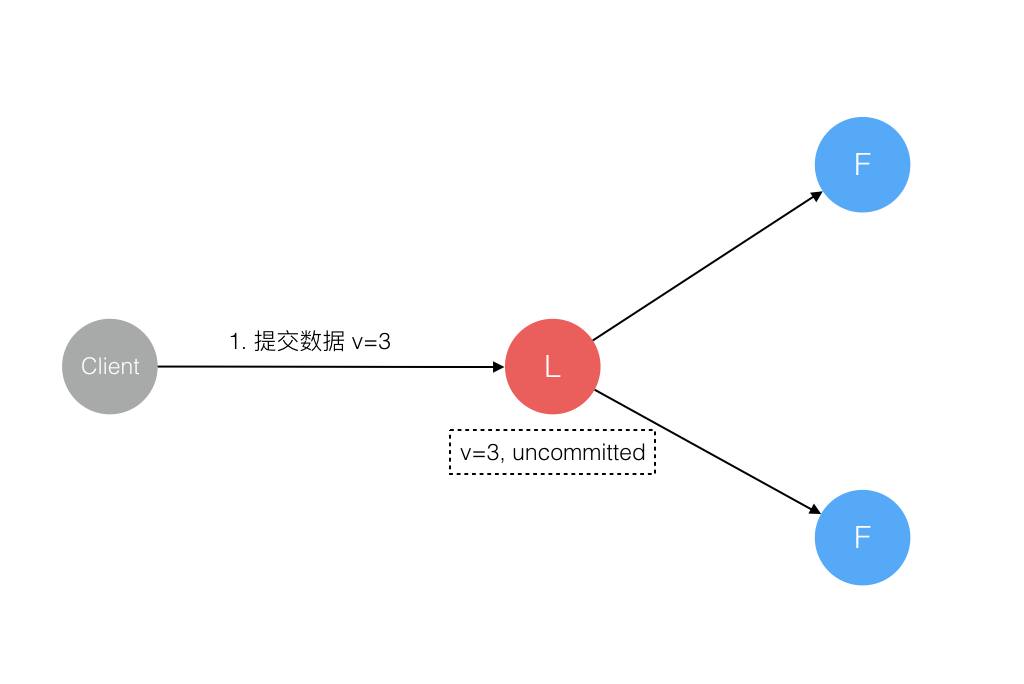
3、Leader收到数据,并同步到所有Follower,但Leader还未收到响应就挂了
这种情况下,虽然数据在Follower节点处于未提交状态,但是所有Follower节点的数据都是一致的,所以在重新选举Leader后,可以成功完成数据提交,Client重复提交的话,就会触发内部去重机制。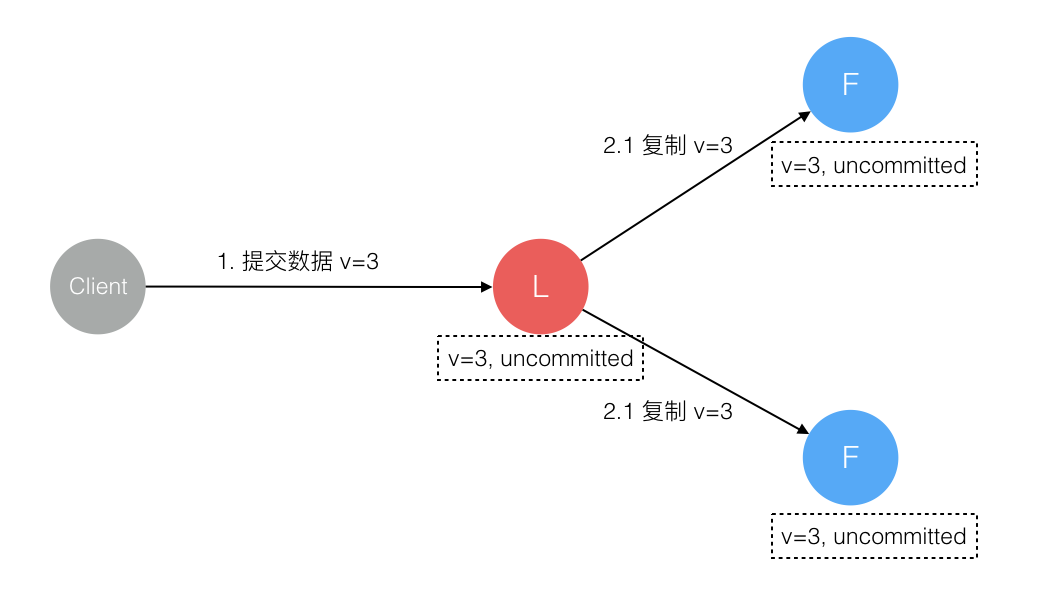
4、数据到达 Leader 节点,成功复制到 Follower 部分节点,但还未向 Leader 响应接收
这个阶段 Leader 挂掉,数据在 Follower 节点处于未提交状态(Uncommitted)且不一致,Raft 协议要求投票只能投给拥有最新数据的节点。所以拥有最新数据的节点会被选为 Leader 再强制同步数据到 Follower,数据不会丢失并最终一致。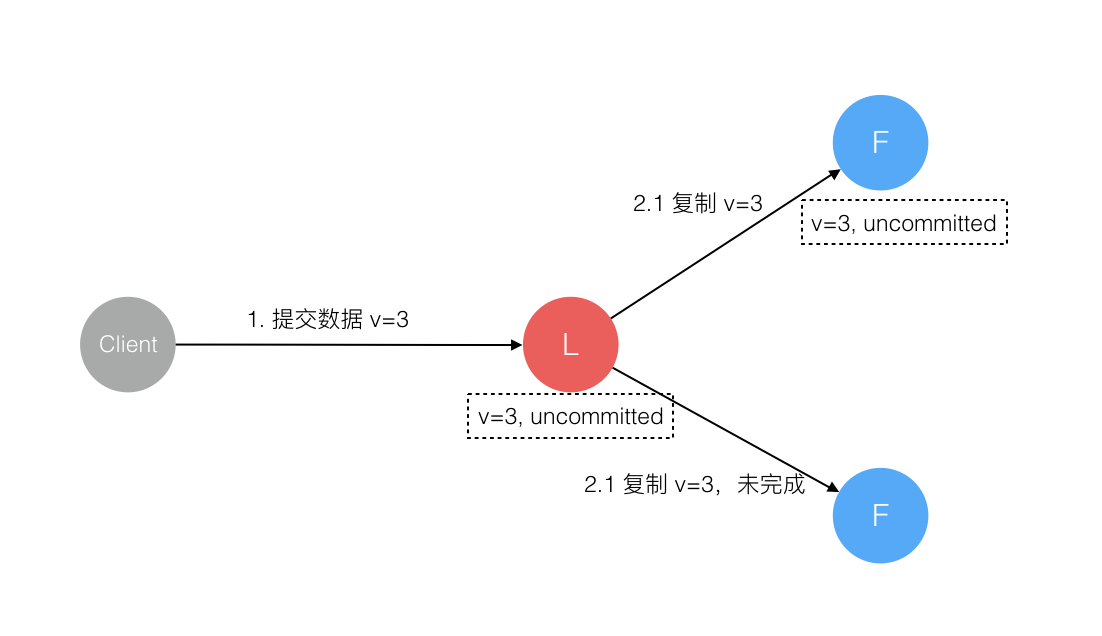
5、数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在 Leader 处于已提交状态,但在 Follower 处于未提交状态
这个阶段 Leader 挂掉,重新选出新 Leader 后的处理流程和阶段 3 一样。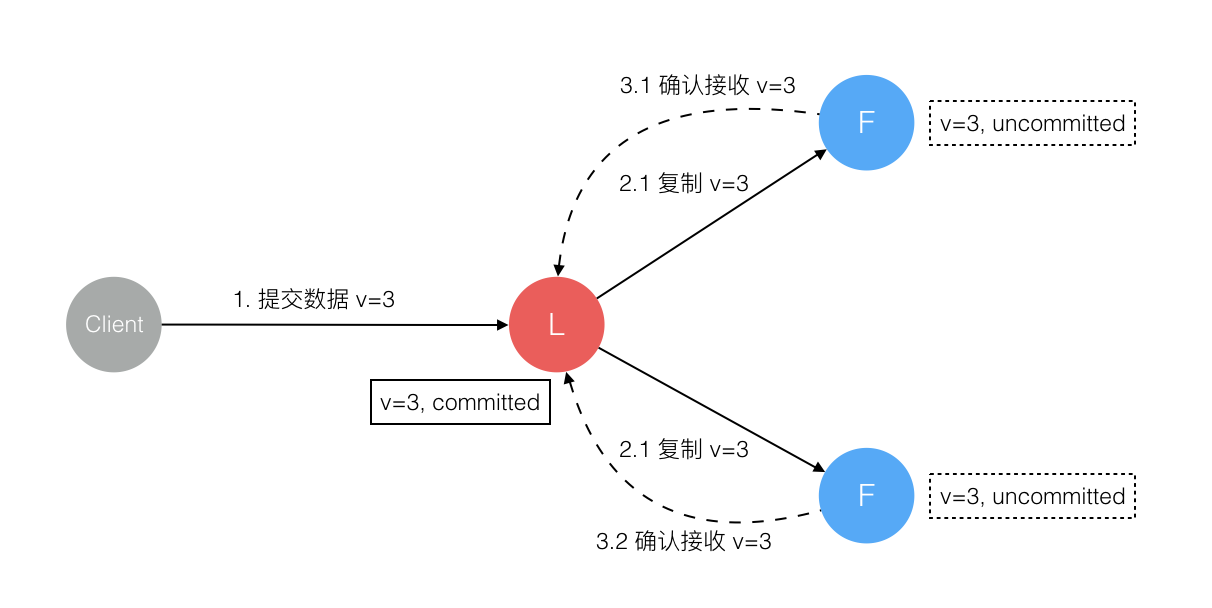
6、数据到达 Leader 节点,成功复制到 Follower 所有或多数节点,数据在所有节点都处于已提交状态,但还未响应 Client
这个阶段 Leader 挂掉,Cluster 内部数据其实已经是一致的,Client 重复重试基于幂等策略对一致性无影响。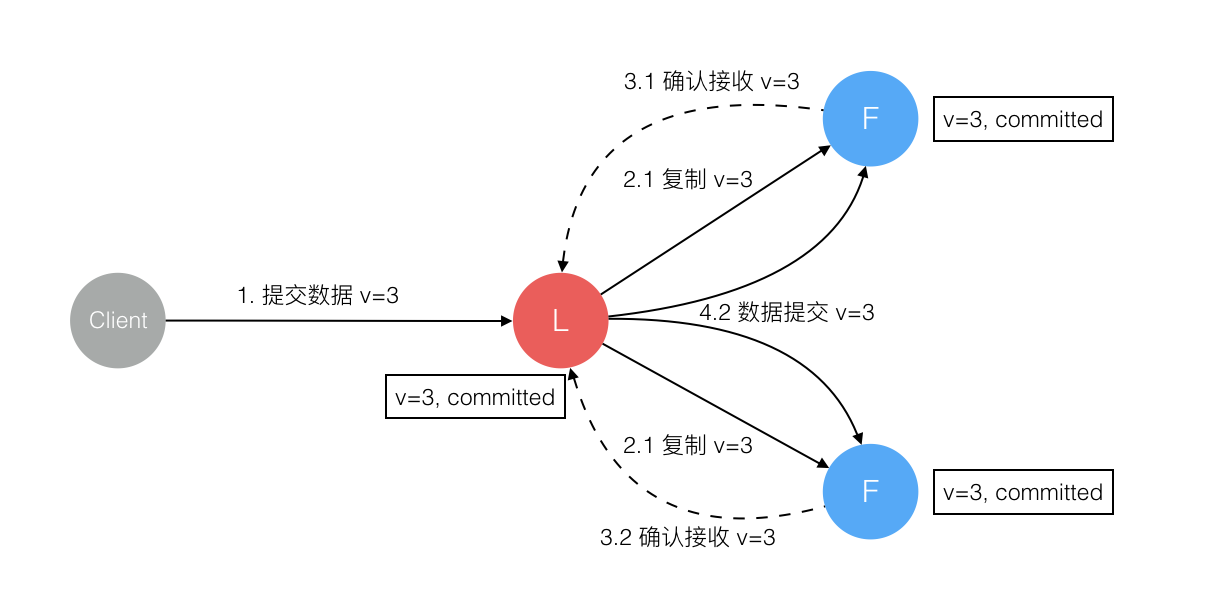
7、网络分区导致的脑裂情况,出现双 Leader
网络分区将原先的 Leader 节点和 Follower 节点分隔开,Follower 收不到 Leader 的心跳将发起选举产生新的 Leader。这时就产生了双 Leader,原先的 Leader 独自在一个区,向它提交数据不可能复制到多数节点所以永远提交不成功。向新的 Leader 提交数据可以提交成功,网络恢复后旧的 Leader 发现集群中有更新任期(Term)的新 Leader 则自动降级为 Follower 并从新 Leader 处同步数据达成集群数据一致。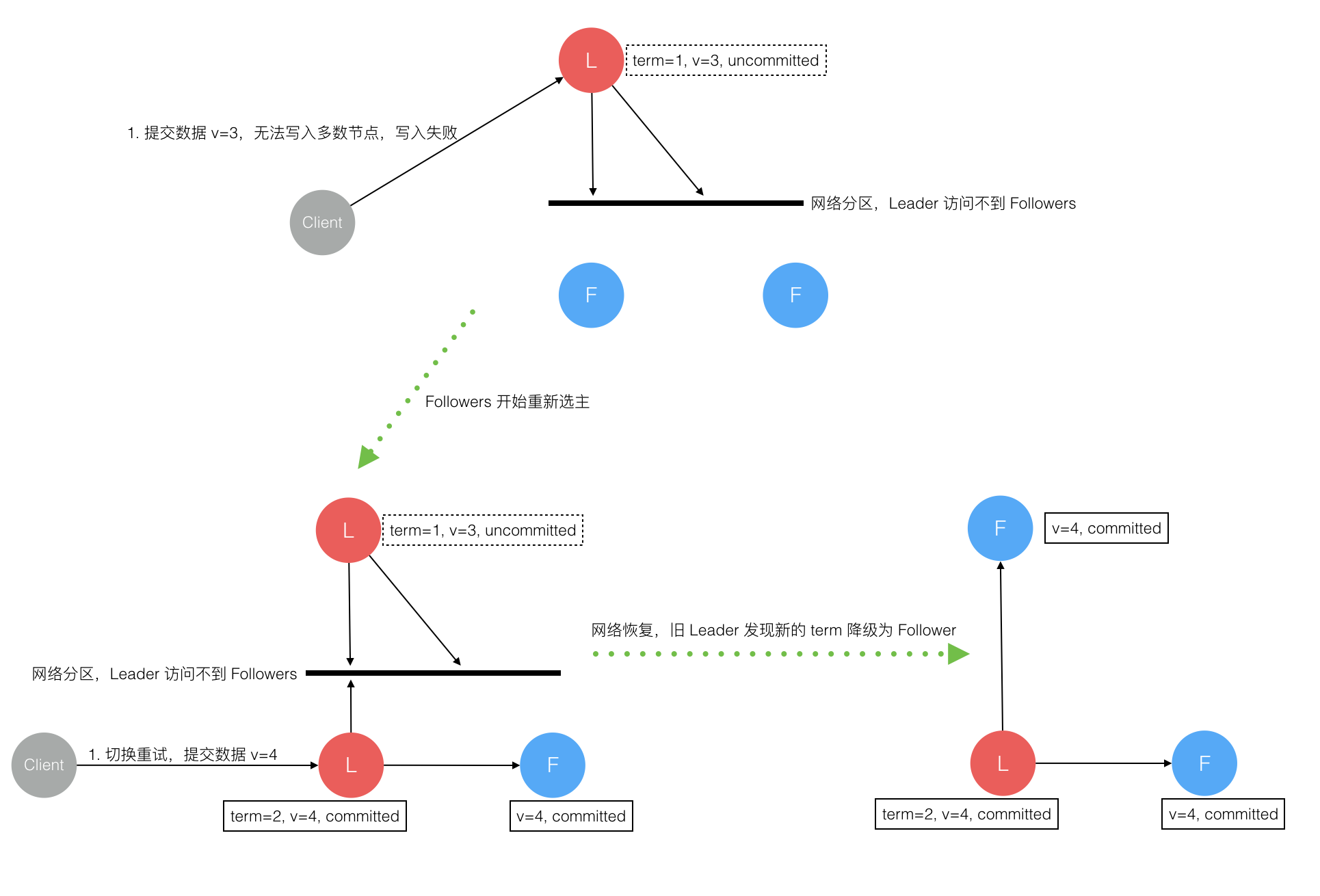
综上穷举分析了最小集群(3 节点)面临的所有情况,可以看出 Raft 协议都能很好的应对一致性问题,并且很容易理解。
集群变化
在整个集群的生命周期内,集群节点发生变化是常有的事情。当集群发生变化,整个集群是怎么工作的呢?
以下内容摘自老錢

分布式系统的一个非常头疼的问题就是同样的动作发生的时间却不一样。比如上图的集群从3个变成5个,集群的配置从OldConfig变成NewConfig,这些节点配置转变的时间并不完全一样,存在一定的偏差,于是就形成了新旧配置的叠加态。
在图中红色剪头的时间点,旧配置的集群下Server[1,2]可以选举Server1为Leader,Server3不同意没关系,过半就行。而同样的时间,新配置的集群下Server[3,4,5]则可以选举出Server5为另外一个Leader。这时候就存在多Leader并存问题。
为了避免这个问题,Raft使用单节点变更算法。一次只允许变动一个节点,并且要按顺序变更,不允许并行交叉,否则会出现混乱。如果你想从3个节点变成5个节点,那就先变成4节点,再变成5节点。变更单节点的好处是集群不会分裂,不会同时存在两个Leader。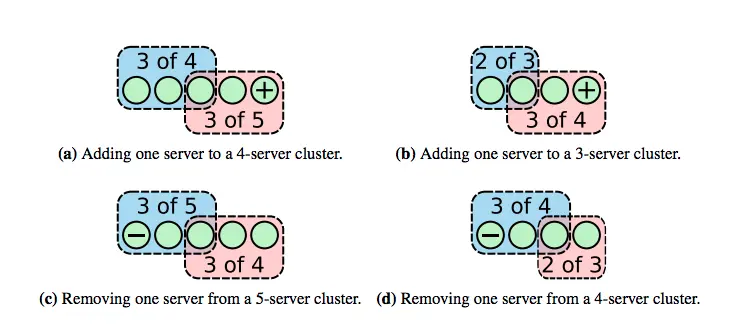
如图所示,蓝色圈圈代表旧配置的大多数(majority),红色圈圈代码新配置的带多数。新旧配置下两个集群的大多数必然会重叠(旧配置节点数2k的大多数是k+1,新配置节点数2k+1的大多数是k+1,两个集群的大多数之和是2k+2大于集群的节点数2k+1)。这两个集群的term肯定不一样,而同一个节点不可能有两个term。所以这个重叠的节点只会属于一个大多数,最终也就只会存在一个集群,也就只有一个Leader。
集群变更操作日志不同于普通日志。普通日志要等到commit之后才可以apply到状态机,而集群变更日志在leader将日志追加持久化后,就可以立即apply。
参考文档: [1] https://www.cnblogs.com/mindwind/p/5231986.html [2] https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14 [3] https://juejin.im/post/5aed9a7551882506a36c659e

若有收获,就点个赞吧
0 人点赞
