一、Pod
pod是一组紧密关联的容器组合,他们共享PID,IPC,NETWORK,UTS namespace,一个Pod里可以运行多个容器,一个Pod里的多个容器共享网络和文件系统,它们可以直接俄通过lo口进行通信。
1.1、Pod的实现原理
首先需要明白的是pod只是一个逻辑上的概念。实际上,kubernetes真正处理的还是宿主机操作系统上的namespace和Cgroups,而不存在一个Pod边界或者隔离环境。
具体的说pod里的所有容器,共享的是同一个Network NameSpace,并且也可以申明共享同一个volume。
但是这并不是简单的像启动docker那样用—net和—volumes-from这样的命令实现,因为这样的命令有一个强依赖性,必须是被共享的容器先启动,这种强依赖关系是不可取的。
所以,在kubernetes项目里需要一个中间容器,这个容器叫Infra容器,在这个pod里,Infra容器永远是第一个被创建的容器,而其他的用户定义的容器则是通过join Network Namespace方式与Infra容器建立关联,如下图: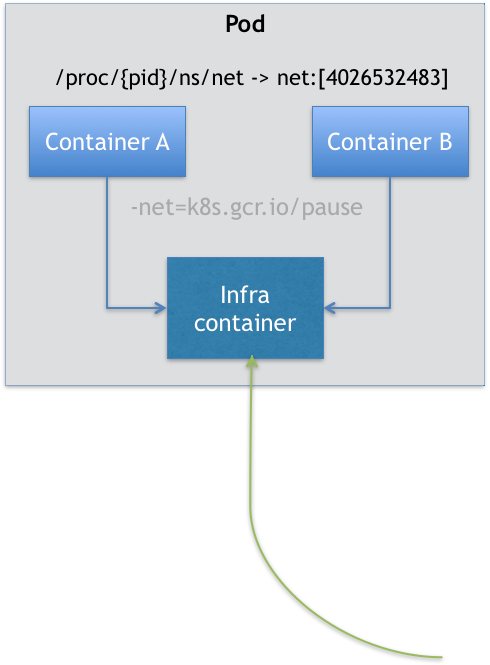
如上所示,pod里有两个容器A和B,还有一个Infra容器,在kubernetes里,Infra容器一定要占用很小的资源,所以它使用的是一个非常特殊的镜像,叫:k8s.gcr.io/pause。这个镜像会永远处于一个暂停的状态。在Infra容器hold住Network Namespace后,用户容器就可以加入到Infra容器的Network Namespace中,所以如果查看这些容器的namespace信息,它们指向的值是完全一样的。
这就说明,对于Pod里的容器A和B来说:
(1)、它们可以直接通过local host进行通信;
(2)、它们看到的网络设备跟Infra看到的是一样的;
(3)、一个Pod只有一个IP地址,也就是Pod的Network Namespace对应的IP地址;
(4)、Pod的生命周期跟Infra一致,和容器A,B无关;
(5)、其他所有的网络资源都是Pod的一份,并且被该Pod中的所有容器共享;
例如:声明一个pod,yaml文件如下:
[root@master k8s]# cat pod-test.yamlapiVersion: v1kind: Podmetadata:name: pod-testlabels:name: redis-masterspec:containers:- name: master01image: redisports:- containerPort: 6379hostPort: 6388- name: master02image: panubo/sshdports:- containerPort: 22hostPort: 8888
然后通过kubectl apply -f pod-test.yaml来创建pod.
我们通过如下命令查看这个pod在那个机器上被创建:
我们到172.16.1.130上通过docker ps查看
可以看到有一个mirrorgooglecontainers/pause-amd64:3.1的镜像,命令是/pause,和我们上面介绍的一样。
对于同一个Pod里的所有容器,它们进出的流量可以认为都是通过Infra容器完成的。所以在配置网络的时候只需要关注pod的网络而不是容器的网络,也就是说我们只需要关注Infra的Network Namespace即可。同理,共享volume也只需要把volume定义在pod层。一个 volume对应的宿主机的目录对于Pod来说只有一个,Pod里的容器只需要声明挂载这个Volume,就可以共享这个volume对应的宿主机目录。比如:
apiVersion: v1kind: Podmetadata:name: two-containersspec:restartPolicy: Nevervolumes:- name: shared-datahostPath:path: /datacontainers:- name: nginx-containerimage: nginxvolumeMounts:- name: shared-datamountPath: /usr/share/nginx/html- name: debian-containerimage: debianvolumeMounts:- name: shared-datamountPath: /pod-datacommand: ["/bin/sh"]args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
如上这个Pod中有两个容器nginx-container和debian-container,它们都声明挂载同一个volume,而这个volume是一个hostPath类型,也就是宿主机上的目录/data,这样这两个容器都同时绑定挂载这个宿主机目录/data。
pod的这种设计模式就是希望如果用户希望在一个容器里跑多个不相关的应用时,就可以考虑是否可以将它们定义为一个pod里的多个容器。
例子1:我们想在一个容器里运行WAR包,它需要和tomcat一起运行。如果用docker来做这件事会有一下两个方案:
(1)、将war包和tomcat做成一个镜像;
(2)、不重做tomcat镜像,将war通过挂载的方式挂载到tomcat容器中运行起来;
这是两种常规的思想,现在有Pod,我们就可以在一个Pod里定义两个容器,一个用来专门管理war包,一个用来管理tomcat应用,只是这两个容器声明挂载同一个volume,如下:
apiVersion: v1kind: Podmetadata:name: javaweb-2spec:initContainers:- image: geektime/sample:v2name: warcommand: ["cp", "/sample.war", "/app"]volumeMounts:- mountPath: /appname: app-volumecontainers:- image: geektime/tomcat:7.0name: tomcatcommand: ["sh","-c","/root/apache-tomcat-7.0.42-v2/bin/start.sh"]volumeMounts:- mountPath: /root/apache-tomcat-7.0.42-v2/webappsname: app-volumeports:- containerPort: 8080hostPort: 8001volumes:- name: app-volumeemptyDir: {}
上面定义了两个容器,第一个容器只有一个war包放在根目录下,然后申明一个initContainers将war包拷贝到/app目录下,第二个容器的作用是启动一个tomcat,它和initContainers挂载了同一个volume,而且initContainers一定是比containers里的容器先启动,所以在启动tomcat的时候它的webapps下面一定会有一个war包,这样每次在发布新版本的时候就只需要制作那个最小的拷贝war包的镜像,而不需要制作包含tomcat和war包这个大的镜像,解决了tomcat和war的耦合性。
例子2:容器的日志收集
假如我们有一个应用会不断的输出日志到/var/log下,这个时候我们就可以借助上面的思想,把pod里的一个volume挂载到/var/log下,然后这个pod里再启动另外一个容器,它们挂载同一个volume,这个容器里运行的是日志收集应用,它可以不断收集/var/log下面的日志到日志平台或者日志存储服务器上。
由上,凡是调度、网络、存储已经安全相关的属性,都是Pod级别。这些属性的共同特征是描述整个“机器”的属性,而非“机器”里应用的属性。
1.2、Pod的重要字段
1.2.1、NodeSelector
它是提供一个Node和Pod绑定的字段,用法如下:
apiVersion: v1kind: Podspec:nodeSelector:disktype: ssd...
这样定义,意味着这个pod永远只能运行在disktype是ssd的Node上。
1.2.2、NodeName
如果Pod的这个字段被赋值,kubernetes就会认为这个Pod已经经过调度了,调度的结果就是赋值的节点名字,这个字段一般有调度器负责设置,但是也可以通过用户设置来骗过调度器,这种做法一般用在测试环境。
1.2.3、HostAliases
定义Pod的hosts文件里的内容,也就是/etc/hosts里的内容。用法如下:
apiVersion: v1kind: Podspec:hostAliases:- ip: "10.1.10.100"hostnames:- "foo.joker.com"
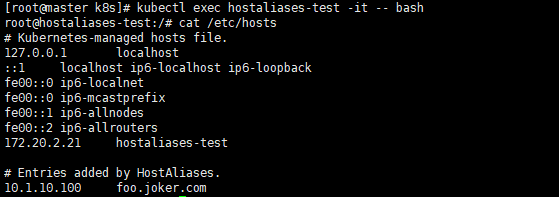
这样在pod启动后就会在/etc/hosts里看到如下内容。
cat /etc/hosts# Kubernetes-managed hosts file.127.0.0.1 localhost...10.244.135.10 hostaliases-pod10.1.10.100 foo.joker.com
例如:[root@master k8s]# cat pod-hostaliases.yaml
apiVersion: v1kind: Podmetadata:name: hostaliases-testlabels:name: hostaliases-nginxspec:hostAliases:- ip: "10.1.10.100"hostnames:- "foo.joker.com"containers:- image: nginxname: nginx-hostaliases
1.2.4、shareProcessNamespace
这个字段如果设置为True,就表示开启共享Pid NameSpace。
例如:cat pod-shareProcessNamespace.yaml
apiVersion: v1kind: Podmetadata:name: pod-pidlabels:name: pid-namespacespec:shareProcessNamespace: Truecontainers:- image: nginxname: nginx-container- image: busyboxname: busybox-containerstdin: truetty: true
我们通过kubectl apply -f pod-shareProcessNamespace.yaml启动Pod
然后通过kubectl attach -it pod-pid -c busybox-container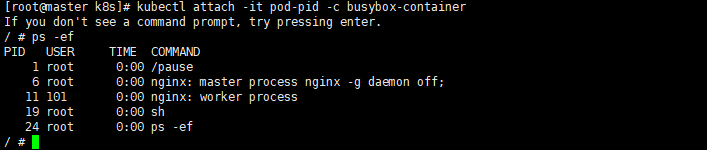
我们可以看到busybox-container这个容器中除了有自己的shell进程还有nginx的进程。这说明它们共享了同一个Pid NameSpace.
类似的,在Pod中的容器共享宿主机的namespace,也一定是Pod级别。例如:
apiVersion: v1kind: Podmetadata:name: nginxspec:hostNetwork: truehostIPC: truehostPID: truecontainers:- name: nginximage: nginx- name: shellimage: busyboxstdin: truetty: true
1.3、健康检查和恢复机制
在Kubernetes里,可以为Pod里的容器配置健康检查探针(Probe)。这样,kubelet就会根据这个Probe的返回值决定这个Pod的健康状态,而不是以容器是否运行作为依据(这种以容器是否运行并不能有效的判断应用是否正常)。
1.3.1、LivenessProbe
我们定义下面一个YAML文件:
apiVersion: v1kind: Podmetadata:name: pod-health-checklabels:name: pod-health-checknamespace: defaultspec:containers:- name: busybox-health-checkimage: busyboxcommand:- "/bin/sh"- "-c"- "touch /tmp/health; sleep 30; rm -f /tmp/health; sleep 600"livenessProbe:exec:command:- "/bin/sh"- "-c"- "cat /tmp/health"initialDelaySeconds: 5periodSeconds: 5
如上定义了一个livenessProbe健康检查机制,其健康检查方式为容器启动后exec进入容器执行cat /tmp/health命令,如果文件存在则返回0表示健康,如果返回值不为0,则表示异常。该健康检查是在initialDelaySeconds:5(容器启动5秒)后开始检查,并且每5秒检查一次(periodSeconds: 5)。
执行这个YAML文件,观察其结果:
我们从上可以发现在Pod启动后,会间隔一段时间然后事件里输出找到这个文件,然后就会重启Pod。
我们可以查看其重启次数:
可以从RESTARS次数看到其重启次数。值得一提的是Kubernetes其实没有RESTART这么一说,其实也就是重新创建一个Pod,然后删除老的Pod。
除了在容器里执行命令外,livenessProbe也可以定义发起HTTP和TCP请求,定义的格式如下:
(1)、HTTP请求
...livenessProbe:httpGet:path: /healthzport: 8080httpHeaders:- name: X-Custom-Headervalue: AwesomeinitialDelaySeconds: 3periodSeconds: 3
(2)、TCP请求
...livenessProbe:tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 20
1.3.2、restartPolicy
接上,这个就是容器的恢复机制,也叫restartPolicy。它是Pod的Spec部分的标准字段,默认是Always,就是任何时候这个容器发生异常,它就会被重新创建一次。
值得注意的是Pod的恢复过程,永远都是发生在当前节点,而不会跑到其他节点去,事实上,一旦一个Pod和Node板顶,它就会永远在这个Node上,除非这个绑定发生了变化,否则它永远不会离开这个节点。这就意味着,如果这个宿主机宕机了,这个Pod也不会迁移到其他节点上去,如果想要让这个Pod出现在其他Node上,就要用类似于Deployment这样的控制器来管理Pod。
作为用户,可以自定义restartPolicy的的恢复策略,它有如下几种恢复策略:
(1)、Always:任何情况下,只要容器不在运行状态,就会自动重启容器;
(2)、OnFailure:只在容器异常的情况下才会重启容器;
(3)、Never:从来不重启容器;
其restartPolicy和Pod里容器状态的对应关系的设计基本原理如下:
(1)、只要这个Pod的restartPolicy的策略允许重启容器(比如Always),那么这个Pod就会保持在running状态,并进行容器重启,否则就是Failed状态;
(2)、对于包含所有容器的Pod,只有其里面全部容器都进入异常状态后,Pod才会进入Failed状态,在此之前Pod都是running状态,此时Pod的READY的字段会显示正常的容器个数。
所以,假如一个Pod里只有一个容器,然后这个容器异常退出了,只有当restartPolicy=Nerver的时候,这个Pod才会进入Failed状态,而其他情况下,因为有这个重启策略存在,这个Pod会一直保持在running状态 。而如果这个Pod有多个容器,如果只有一个容器异常退出,哪怕restartPolicy=Never,只有当这个Pod里的所有容器都异常的情况下,这个Pod才会进入Failed状态。
1.3.3、ReadinessProbe
在Pod中,livenessProbe是做存活性检查,而ReadinessProbe是做就绪性检查,所谓的就绪性检查就是检查我们应用是否就绪,比如我们的tomcat服务,在启动tomcat服务的时候需要解压war包,然后将其加入JVM,然后启动,这个过程需要时间就不止10秒,在应用完整启动后,我们kubectl get pods的时候查看READY状态才变成可用,如果没有做就绪性检测,只要容器起来后READY状态就变为可用了,在这个时候实际上我们的应用是并不可用的。
在我们定义Pod的时候定义就绪性检测是很有必要的。
ReadinessProbe的健康检测和LivenessProbe一样,也有以下三种:
- TCPSocket
- httpGet
- exec
下面我们定义一个简单的YAML文件:
readlinesspprobe-pod.yaml
apiVersion: v1kind: Podmetadata:name: httpget-readinessprobenamespace: defaultspec:containers:- name: httpget-podimage: nginxports:- name: nginx-portcontainerPort: 80readinessProbe:httpGet:path: /index.htmlport: nginx-portinitialDelaySeconds: 3
然后我们创建这个YAML文件,观察起Pod状态:
[root@master pod]# kubectl apply -f readlinesspprobe-pod.yamlpod/httpget-readinessprobe created
[root@master ~]# kubectl get podsNAME READY STATUS RESTARTS AGEhttpget-readinessprobe 1/1 Running 0 4m43s
然后我们做一个测试,删除我们的index.html文件,操作如下:
[root@master ~]# kubectl exec -it httpget-readinessprobe -- /bin/bashroot@httpget-readinessprobe:/# ls /usr/share/nginx/html/50x.html index.htmlroot@httpget-readinessprobe:/# rm -f /usr/share/nginx/html/index.html
然后等一段时间,因为我们定义了检测时间,再查看Pod状态:
[root@master ~]# kubectl get podsNAME READY STATUS RESTARTS AGEhttpget-readinessprobe 0/1 Running 0 9m7s
我们可以看到READY状态变为0,但是STATUS还是running状态,这就是容器运行是正常的,但是应用是异常的。
现在我们再echo一个页面,再观察Pod状态:
[root@master ~]# kubectl exec -it httpget-readinessprobe -- /bin/bashroot@httpget-readinessprobe:/# echo "hello world" >> /usr/share/nginx/html/index.html
然后我们就可以看到Pod变为正常:
[root@master ~]# kubectl get podsNAME READY STATUS RESTARTS AGEhttpget-readinessprobe 1/1 Running 0 13m
1.3.4、 lifecycle
lifecycle用于容器启动后,停止前的操作,其主要对象有:
- postStart:容器启动后操作,在容器启动后会立即执行的操作
- preStop:容器停止前操作,在容器停止前会立即执行的操作
其内的对象和livenessProbe一样,我们定义一个YAML文件如下:
lifycycle.yaml
apiVersion: v1kind: Podmetadata:name: lifecycle-testnamespace: defaultspec:containers:- name: lifecycle-testimage: busyboxlifecycle:postStart:exec:command: ["/bin/sh", "-c", "mkdir -p /data/web/html; echo 'lifecycle test' >> /data/web/html/index.html "]command:- "/bin/sh"- "-c"- "sleep 3600"
然后创建这个YAML文件:
[root@master pod]# kubectl apply -f lifycycle.yamlpod/lifecycle-test created
然后登录容器查看:
[root@master ~]# kubectl exec -it lifecycle-test -- /bin/sh/ # cat /data/web/html/index.htmllifecycle test
可以发现我们echo进去的文件是存在的。
1.4、PodPreset
PodPreset叫做Pod预设值功能,它可以自动为Pod填充一些定义好的字段。
要使用PodPreset,需要满足一下几点:
(1)、确保已经开启了这个API对象:settings.k8s.io/v1alpha1/podpreset;
(2)、确保开启准入PodPreset;
比如定义了一下一个简单的YAML:
apiVersion: v1kind: Podmetadata:name: websitelabels:app: websiterole: frontendspec:containers:- name: websiteimage: nginxports:- containerPort: 80
然后顶一个PodPreset的YAML文件:
apiVersion: settings.k8s.io/v1alpha1kind: PodPresetmetadata:name: allow-databasespec:selector:matchLabels:role: frontendenv:- name: DB_PORTvalue: "6379"volumeMounts:- mountPath: /cachename: cache-volumevolumes:- name: cache-volumeemptyDir: {}
在这个Preset的YAML文件中,selector字段对应的标签表示这个Preset只会对该标签的Pod有效。其后面的spec字段就定义了一些环境变量和挂载等。
现在我们先执行preset.yaml,在执行pod.yaml。
kubectl create -f preset.yamlkubectl create -f pod.yaml
这是可以查看这个Pod的API:
kubectl get pod website -o yamlapiVersion: v1kind: Podmetadata:name: websitelabels:app: websiterole: frontendannotations:podpreset.admission.kubernetes.io/podpreset-allow-database: "resource version"spec:containers:- name: websiteimage: nginxvolumeMounts:- mountPath: /cachename: cache-volumeports:- containerPort: 80env:- name: DB_PORTvalue: "6379"volumes:- name: cache-volumeemptyDir: {}
从上可以看到这个Pod里面已经加了我们preset中定义的字段了。
需要注意的是:PodPreset中定义的内容,只会在这个Pod API创建之前追加到这个对象本身上,而不会影响这个Pod的任何的控制器的定义。比如我们创建一个nginx-deployment的Deployment对象,这个Deployment对象本身不会被PodPreset对象改变,只有通过这个Deployment创建出来的Pod并且标签是PodPreset中定义的才会被改变。

若有收获,就点个赞吧
0 人点赞
