一、原理介绍
Kubernetes中的调度器是kube-scheduler,每次我们在创建Pod的时候都是通过kube-scheduler的调度算法将其调度到合适的Node上。
其工作流程主要如下:
- 在集群中所有Node中,根据调度算法挑选出可以运行该Pod的所有Node;
- 在上一步的基础上,再根据调度算法给筛选出的Node进行打分,筛选出分数最高的Node进行调度;
- 将Pod的spec.nodeName填上调度结果的Node名字;
其工作原理如下图: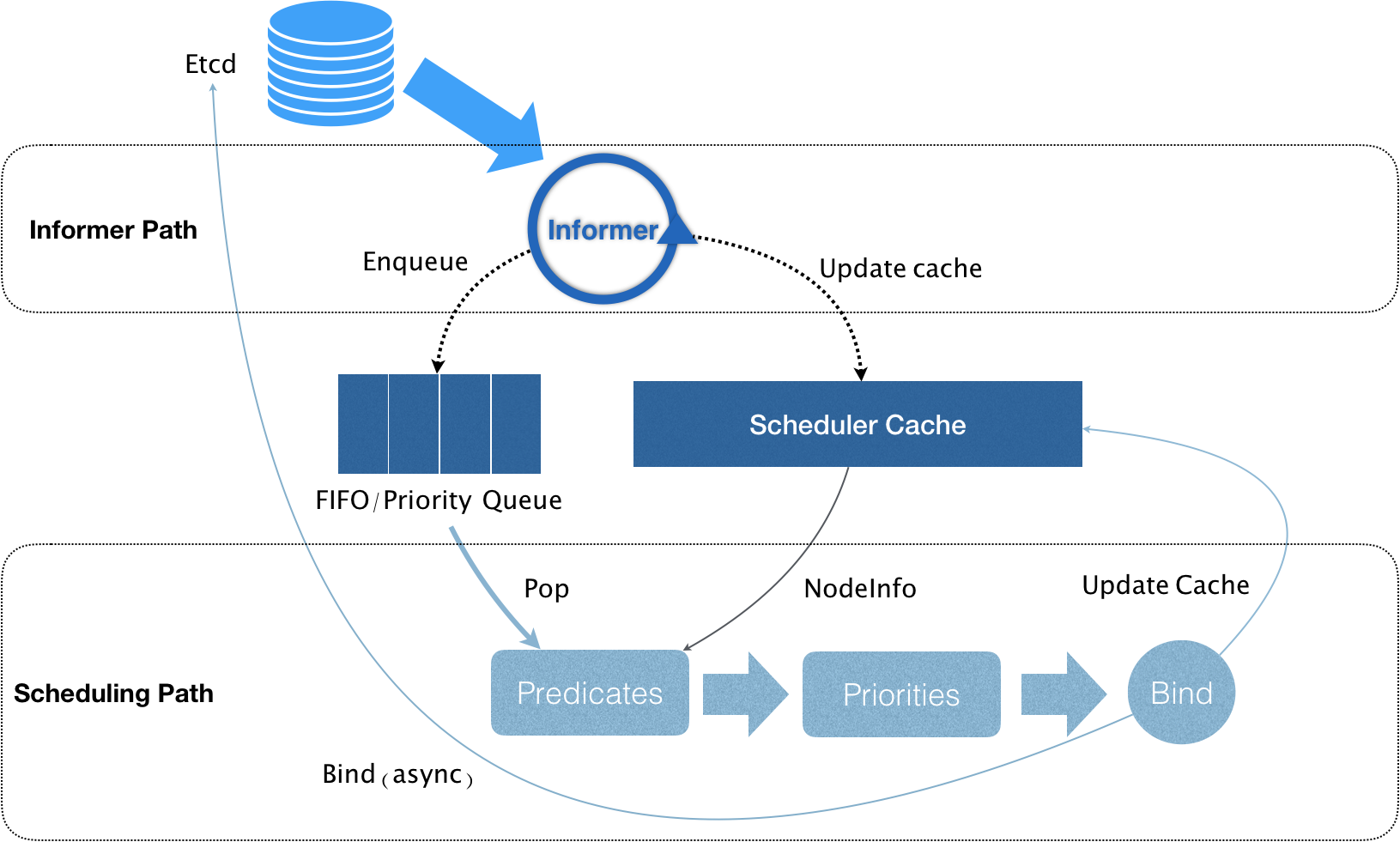
由上图可知,Kubernetes的调度器核心是两个相互独立的控制循环。
1、Informer Path
其主要作用是启动一个Informer来监听Etcd中Pod,Node,Service等与调度器相关的API对象的变化。当一个Pod被创建出来后,就被通过Informer Handler将待调度的Pod放入调度队列中,默认情况下,Kubernetes的调度策略是一个优先级队列,并且当集群信息发生变化的时候,调度器还会对调度队列里的内容进行一些特殊操作。而且Kubernetes的默认调度器还负责对调度器缓存(scheduler cache)进行更新,以执行调度算法的执行效率。
2、Scheduler Parh
其主要逻辑是不断从队列中出一个Pod,然后调用Predicates进行过滤,然后得到一组Node(也就是可运行Pod的所有Node信息,这些信息都是来自scheduler cache),接下来调用Priorities对筛选出的Node进行打分,然后分数最高的Node会作为本次调度选择的对象。调度完成后,调度器需要将Pod的spec.nodeName的值修改为调度的Node名字,这个步骤称为Bind。
但是在Bind阶段,Kubernetes默认调度器只会更新scheduler cache中的信息,这种基于乐观假设的API对象更新方式被称为Assume。在Assume之后,调度器才会向API Server发起更新Pod的请求,来真正完成Bind操作。如果本次Bind失败,等到scheduler cache更新之后又会恢复正常。
正是由于有Assume的原因,当一个Pod完成调度需要在某个Node节点运行之前,kubelet还会进行一部Admit操作来验证该Pod是否能够运行在该Node上,作为kubelet的二次验证。
常用的预算策略有:
- CheckNodeCondition
- GeneralPredication:
HostName,
PodFitsHostPort,
MatchNodeSelector,
PodFitsResources
- NoDiskConflict
二、优先级和抢占机制
正常情况下,当一个Pod调度失败后,它会被搁置起来,直到Pod被更新,或者集群状态发生变化,调度器才会对这个Pod进行重新调度。但是有的时候我们不希望一个高优先级的Pod在调度失败就被搁置,而是会把某个Node上的一些低优先级的Pod删除,来保证高优先级的Pod可以调度成功。
Kubernetes中优先级是通过ProrityClass来定义,如下:
apiVersion: scheduling.k8s.io/v1beta1kind: PriorityClassmetadata:name: high-priorityvalue: 1000000globalDefault: falsedescription: "This priority class should be used for high priority service pods only."
其中的value就是优先级数值,数值越大,优先级越高。优先级是一个32bit的整数,最大值不超过10亿,超过10亿的值是被Kubernetes保留下来作为系统Pod使用的,就是为了保证系统Pod不会被抢占。另外如果globalDefault的值设置为 true的话表明这个PriorityClass的值会成为系统默认值,如果是false就表示只有在申明这个PriorityClass的Pod才会拥有这个优先级,而对于其他没有申明的,其优先级为0。
如下就是一个Pod使用PriotityClass:
apiVersion: v1kind: Podmetadata:name: nginxlabels:env: testspec:containers:- name: nginximage: nginximagePullPolicy: IfNotPresentpriorityClassName: high-priority
上面的PriotiryClassName就是定义我们的PriorityClass,当这个Pod提交给Kubernetes之后,Kubernetes的PriorityAdmissionController会自动将这个Pod的spec.priority字段设置为我们定义的值。而当这个Pod拥有这个优先级之后,高优先级的Pod就可能比低优先级的Pod先出队,从而尽早完成调度。
而当一个高优先级的Pod调度失败后,其抢占机制就会被触发,这时候调度器就会试图从当前的集群中寻找一个节点,使得这个节点上的一个或多个低优先级的Pod被删除,然后这个高优先级的Pod就可以被调度到这个节点上。
当抢占发生时,这个高优先级Pod并不会立即调度到即将抢占的节点上,调度器只会将这个Pod的spec.nominatedNodeName的值设置为被抢占节点的Node名字,然后这个Pod会重新进入下一个调度周期,然后会在这个周期内决定这个Pod被调度到哪个节点上。在这个重新调度期间,如果有一个更高的优先级Pod也要抢占这个节点,那么调度器就会清空原Pod的nominatedNodeName的值,而更高优先级的Pod将会抢占这个值。
实现原理:
Kubernetes用两个队列来实现抢占算法:ActiveQ和unschedulableQ。
- ActiveQ:凡是在ActiveQ里的Pod,都是下一个周期需要调度的对象,所以当Kubernetes创建一个新的Pod,这个Pod就会被放入ActiveQ里;
- unschedulableQ:专门用来存放调度失败的Pod;
那么如果一个Pod调度失败,调度器就会将其放入unschedulableQ里,然后调度器会检查这个调度失败的原因,分析并确认是否可以通过抢占来解决此次调度问题,如果确定抢占可以发生,那么调度器就会把自己缓存的所有信息都重新复制一份,然后使用这个副本来模拟抢占过程。如果模拟通过,调度器就会真正开始抢占操作了:
- 调度器会检查牺牲者列表,清空这些Pod所携带的nominatedNodeName字段;
- 调度器会把抢占者的nominatedNodeName的字段设置为被抢占的Node名字;
- 调度器会开启Goroutine,同步的删除牺牲者;
接下来调度器就会通过正常的调度流程,把抢占者调度成功。在这个过程中,调度器会对这个Node,进行两次Predicates算法:
- 假设上述抢占者已经运行在这个节点上,然后运行Predicates算法;
- 调度器正常执行Predicates算法;
只有上述者两个都通过的情况下,这个Node和Pod才会被 绑定。

若有收获,就点个赞吧
0 人点赞
