一、Mysql存储引擎原理拆解以及设计 深度剖析
1. MySQL底层是如何现实的?
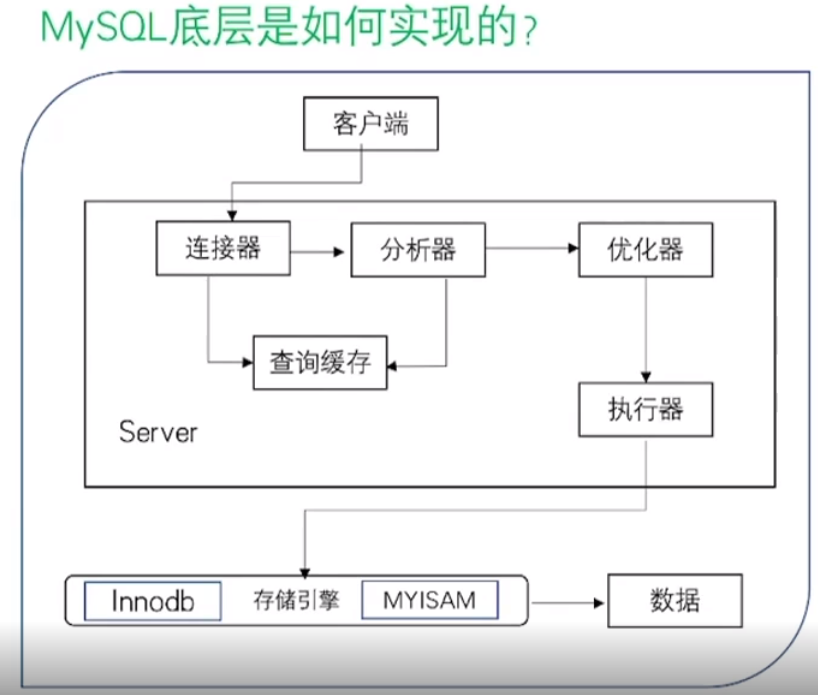
客户端: 写的sql语句 —-必备技能,不值钱
服务端:除了客户端外的所有,更值钱。
Server—存储引擎: 通过接口实现;
Server: 对SQL语句解析,到执行器的指令。
Innodb: 支持行锁和事物,是重中之重。 作用: 存储和检索查询。
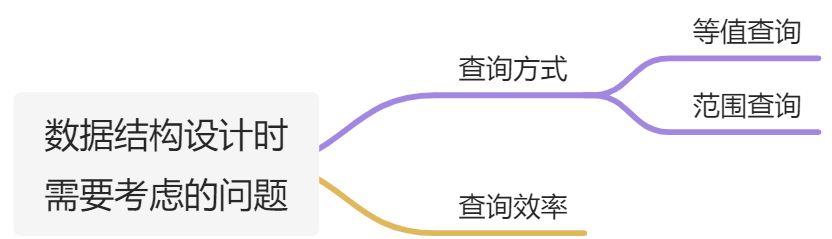
2. 存储结构
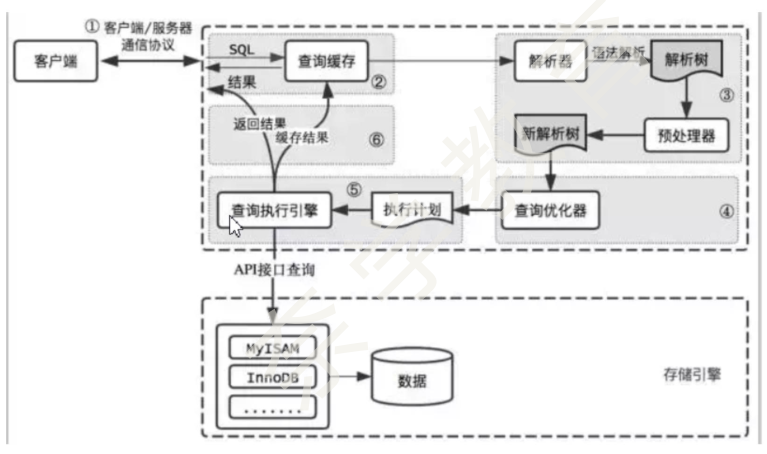
1. 页 page
1.1 page的重要性:
参考链接:https://www.cnblogs.com/bdsir/p/8745553.html
存储结构就是在ibd文件中(叫表空间, tablespace),一个表就是一个ibd,里面有众多 页(page).
- 是硬盘和内存的最小交互单位。 当查询where id=1时,就会按照page为单位进行加载到内存中进行查找。大小是16KB。
- 一个索引的节点,就是一页,
-
2. MySQL记录存储
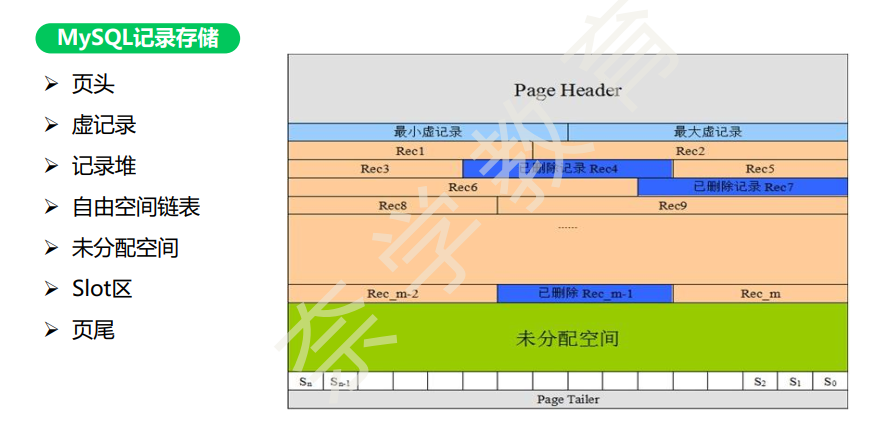
16K的页中,每页至少存储2行数据;如果一行数据超过16K了,该怎么办?
- 页头/页尾——页和页之间是双向链表
- 最大/最小虚记录
- 行记录: 纪录堆(存储的数据—-已存的、删除的),自由空间链表和未分配空间。
slot区:优化单页查询记录——-组长的作用。避免遍历查询浪费时间。
3. 页内记录维护
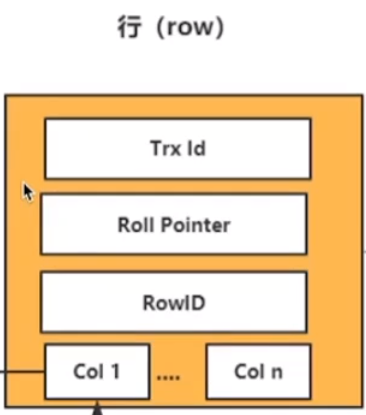
顺序保证: 为了范围查询。 如果是数组,其查询是按照下标的,并不能实现范围查询。
- 插入策略:行与行有序。 物理有序: 磁盘上物理有序,地址的移动; 逻辑有序:根据指针指向来排序。
- 
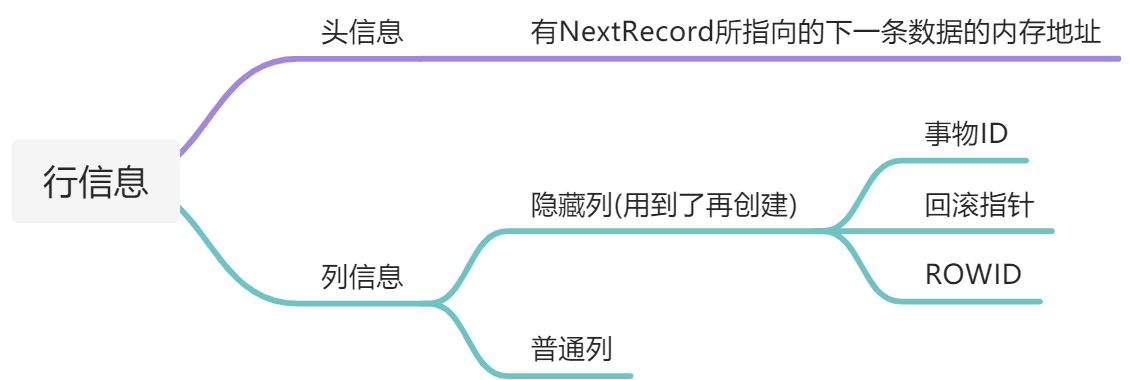
- 自由空间链表:已经使用过的磁盘区域,这个位置上的记录被删除掉了,这个已经被分配的磁盘空间不会被回收。
- 未使用空间: 没有被开发的。
业内查询: slot. where id=1 的查找链路: 硬盘—-》ibd文件—-》n个页文件(用到了索引)—-》一个页—-》一个行记录—-》该页加载到内存中。
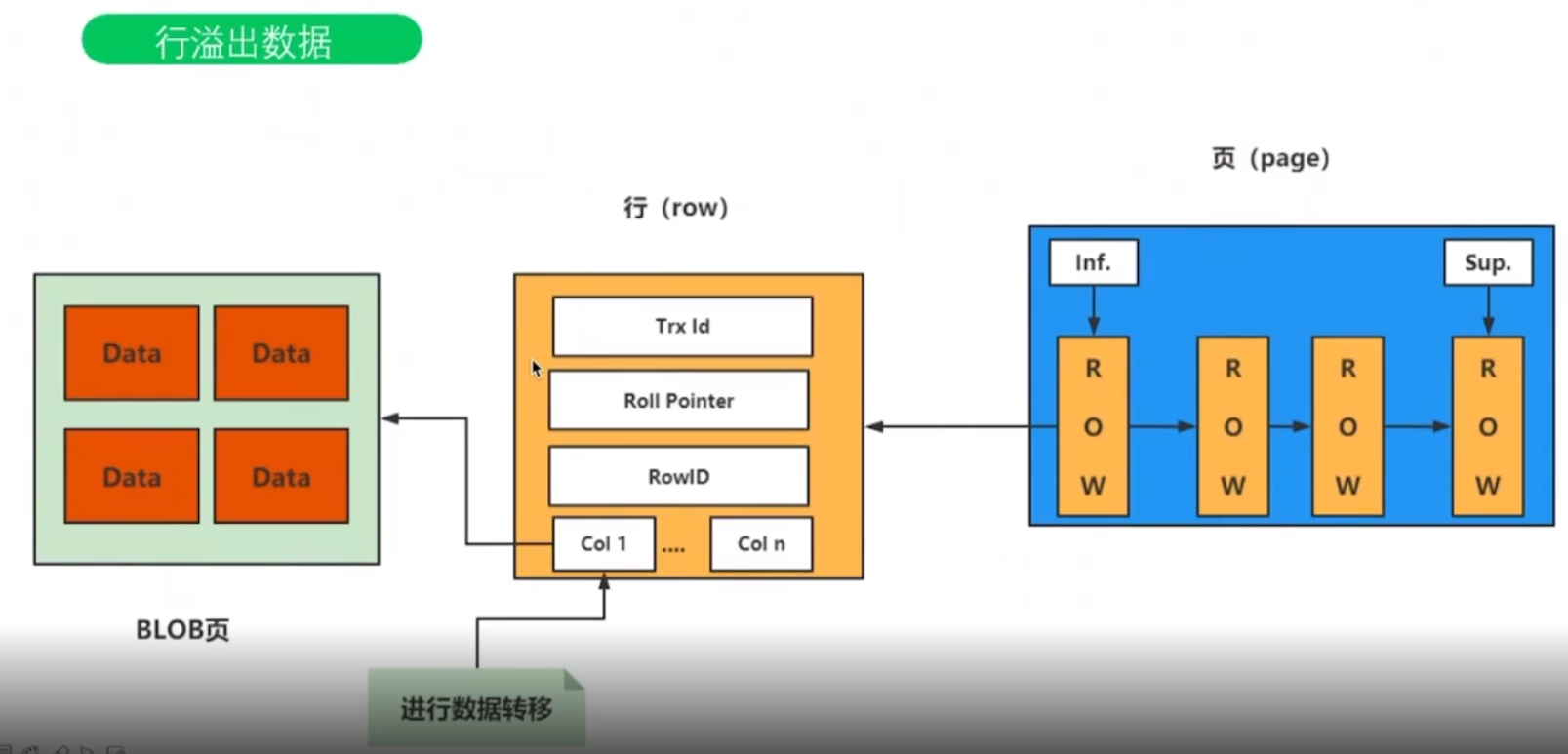
应用场景: 一页中至少有2行数据,如果行数据超过了页的大小,则需要写进其他页中,此时需要溢出页。 当前行的众多溢出页是连续的,而目前页中的行信息中只保留一个溢出页的地址信息。
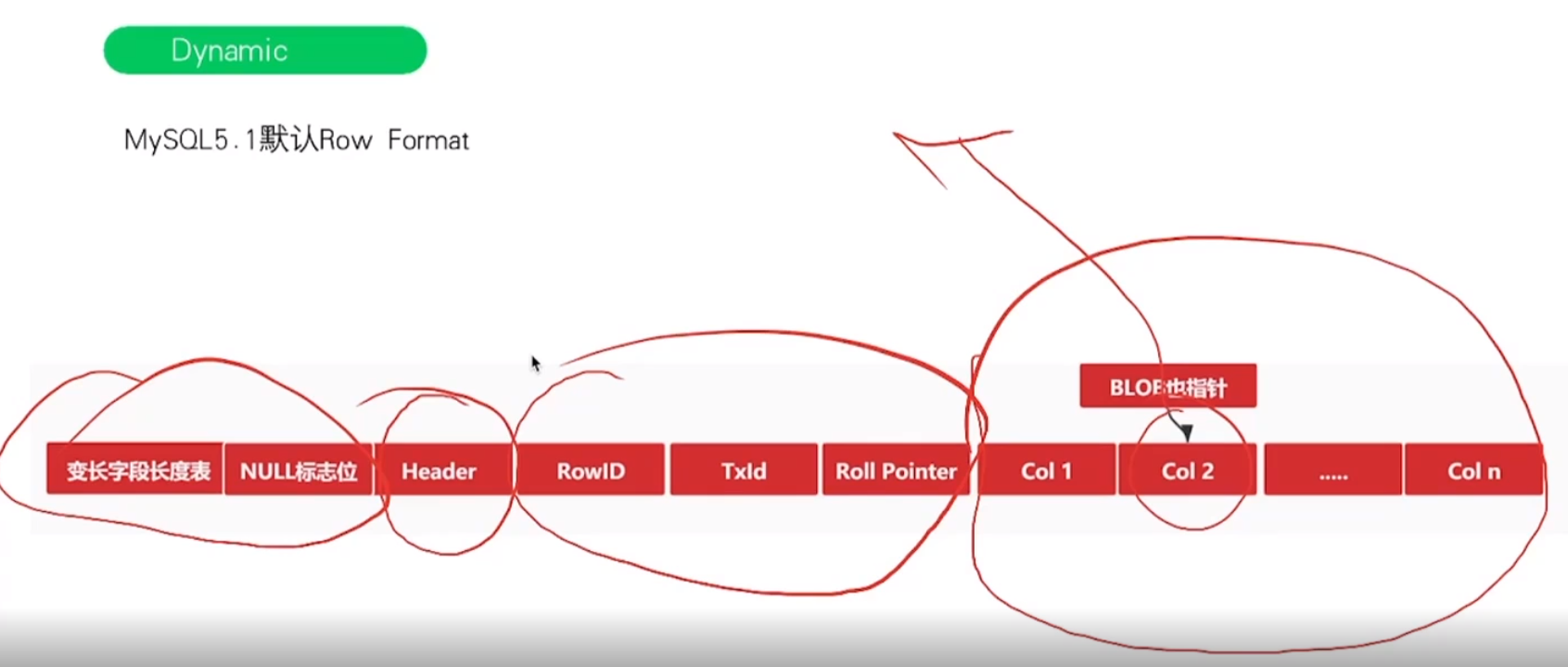
5. 页的详细拆解图
二、MySQL索引实现原理拆解以及涉及 深度剖析
1. InnoDB内存管理
1. 逻辑分析
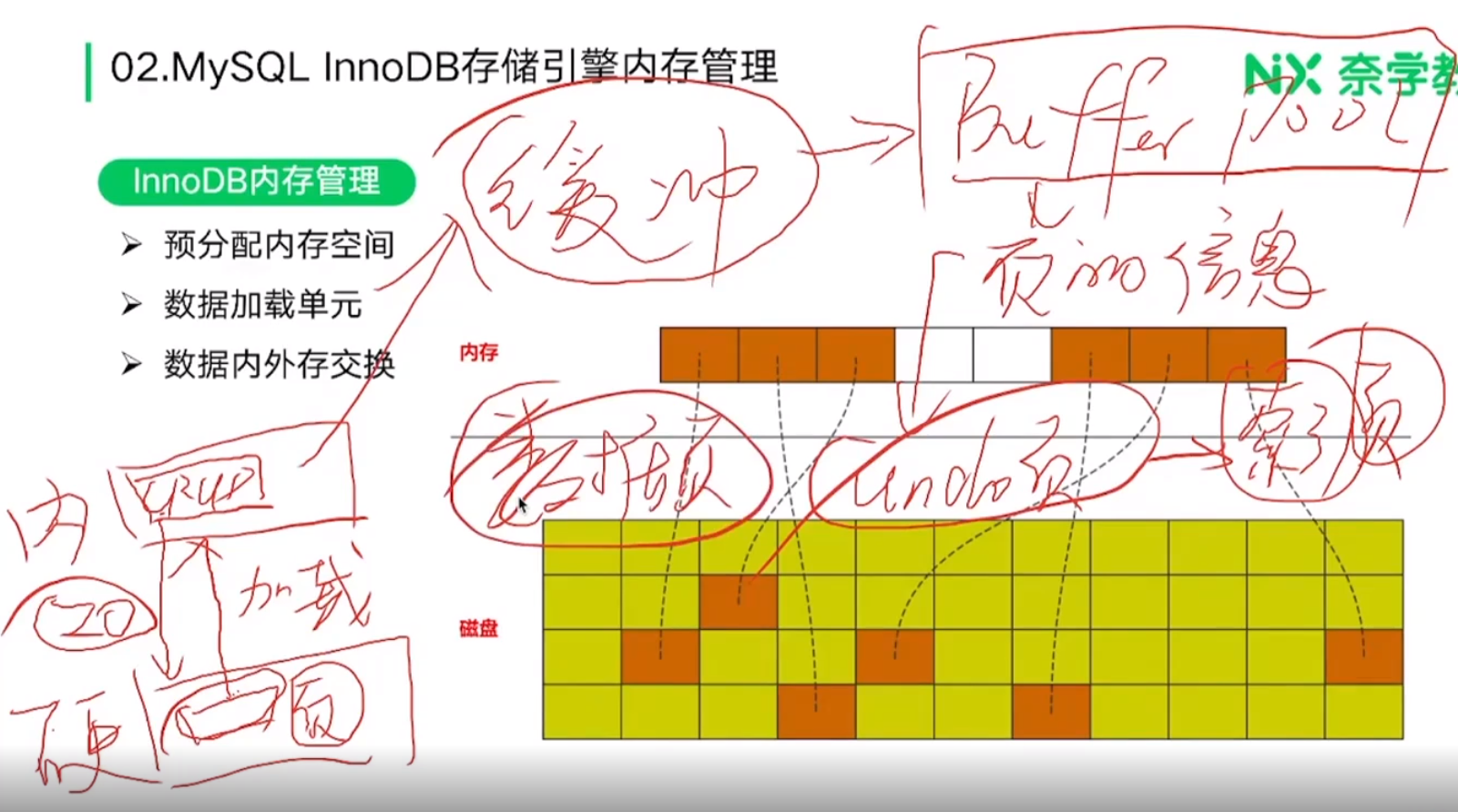
InnoDB中有buffer Pool Size 可以调整内存大小。 而内存中会有一些空闲页,其大小为 BP size/16K
- 加载到内存中的页的分类:
- 数据页
- undo页——和回滚有关
- 索引页
- 内存中页的管理:

3. 数据内外存交换
1. MySQL内存管理—页面淘汰
1. 用到的算法:LRU
- 内存淘汰: 最近最少使用原则。
- 原理: 内存中的数据依据链表排列(先进先出),数据从头部加入尾部出,当中间的数据被重新访问了,又再次从头部加入。此时,尾部的数据是比较老旧的数据,存在的价值比较低,所以优先淘汰。
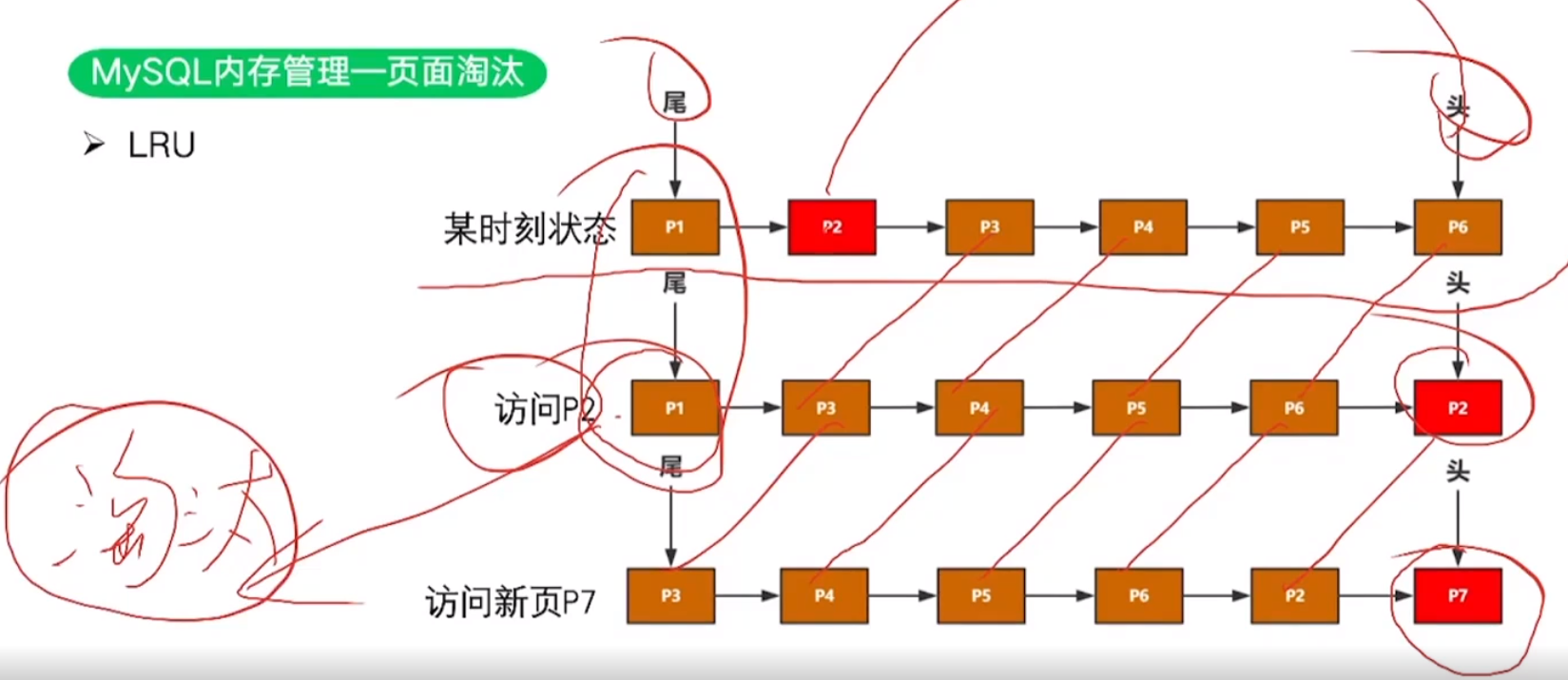
2. 实际问题应用:避免热数据被淘汰
用2个RLU列表进行管理
LRU_NEW(占列表总的5/8大小): 热点数据
LRU_old(占列表总的3/8大小): 全表扫描的数据。
从LRU_NEW区域淘汰到LRU_Old区域的逻辑:当数据长时间不用,而又有新数据加入时,自然就淘汰掉了;
从 LRU_old区域淘汰到LRU_new区域的逻辑: 存在old_blocks_time的参数,当两次页级别查询的时间间隔大于old_blocks_time时,才会进入到热点区域。
解析: 全表扫描时,查询 where id=1,2,3,4,5,6,7,8,9,10 时,会分10次查询该页,说明此时扫描的是全部数据,而不是重点数据(即热点数据)。
问题: 热点区域的数据频繁地移动,会浪费效率,该怎么办?
3. LRU_New中数据的lock
当数据处于LRU_New中的前1/4位置时,如果发生了重新访问,数据位置保持不变,不会再移动到头位置。
4. LRU_Old中数据处理
如果淘汰的数据是一个脏页,涉及到了落盘过程。<br /> 如果数据没有发生修改,此时直接清空;
5. 为了让目标页能被快速找到,该怎么设计数据结构和算法,使数据在磁盘上存储?B+树
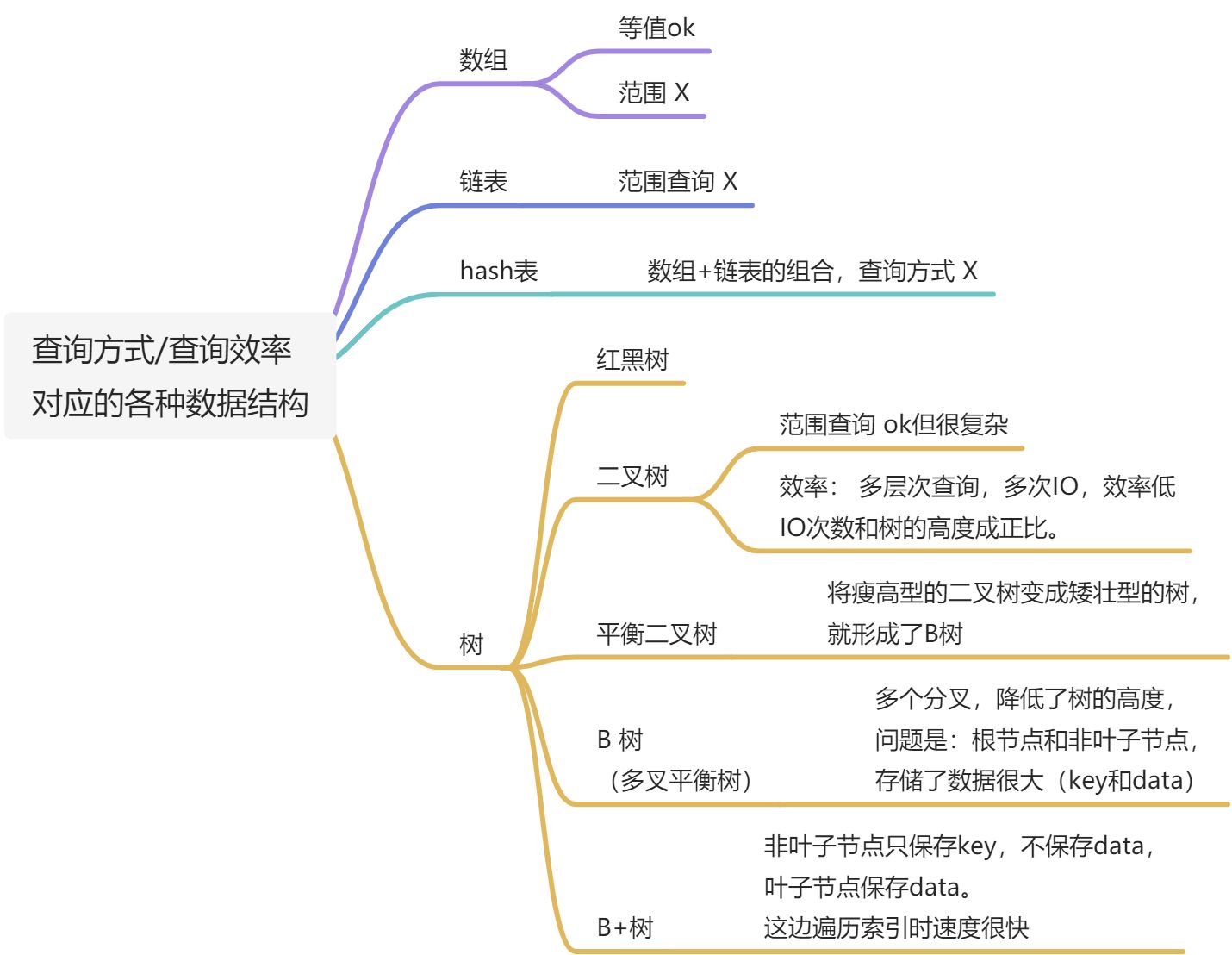
4. InnoDB的索引原理分析

索引覆盖: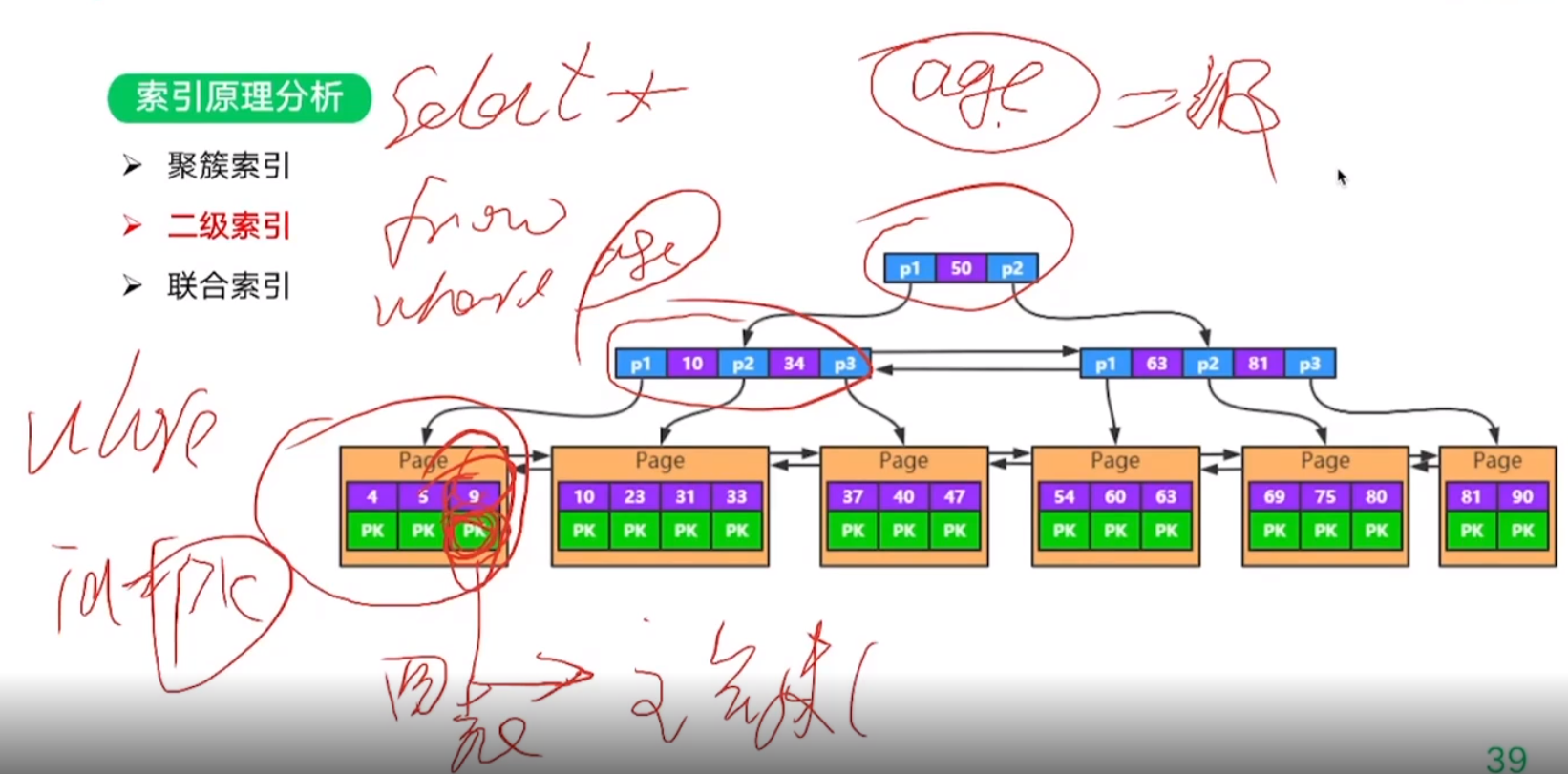
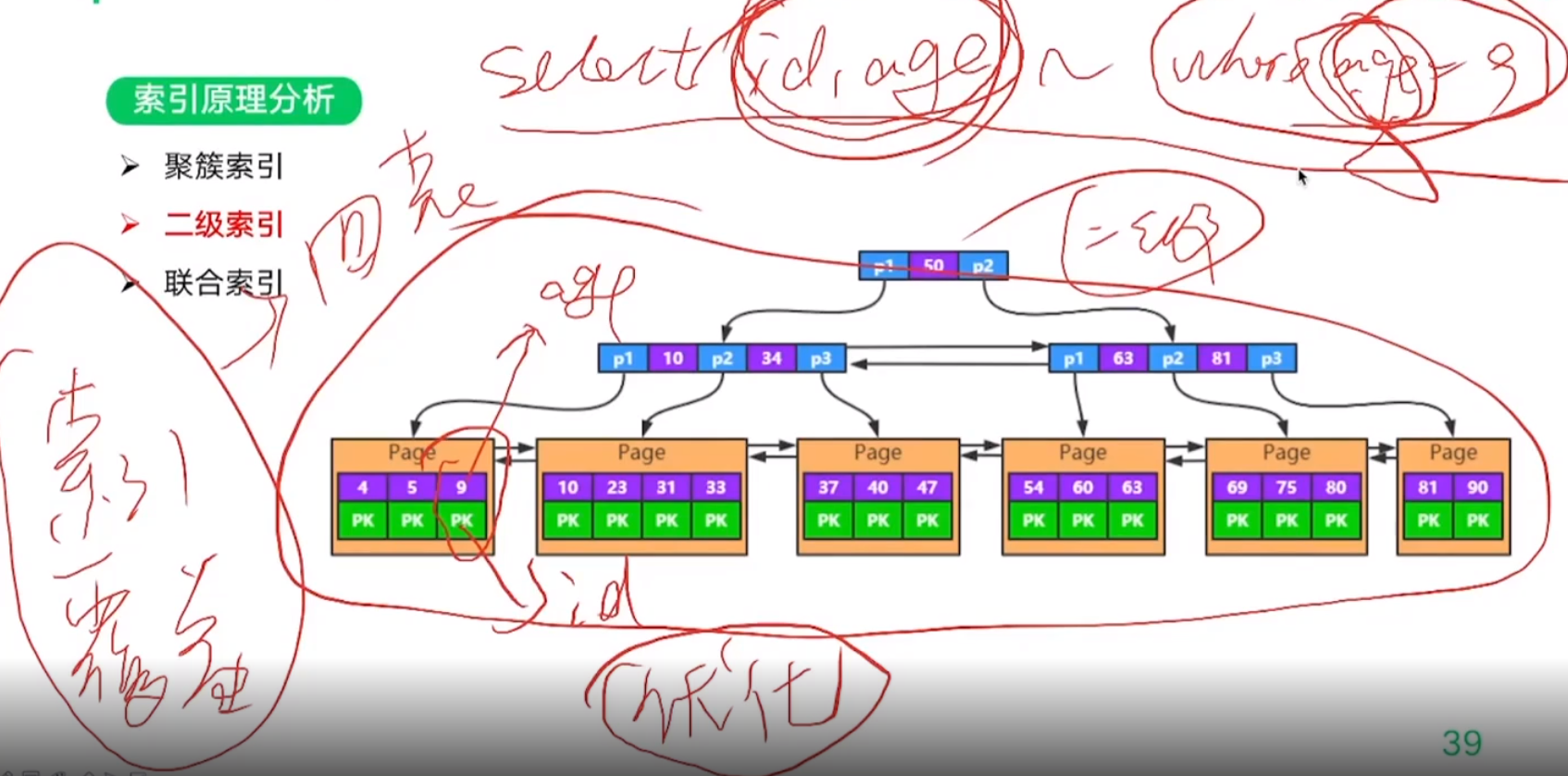
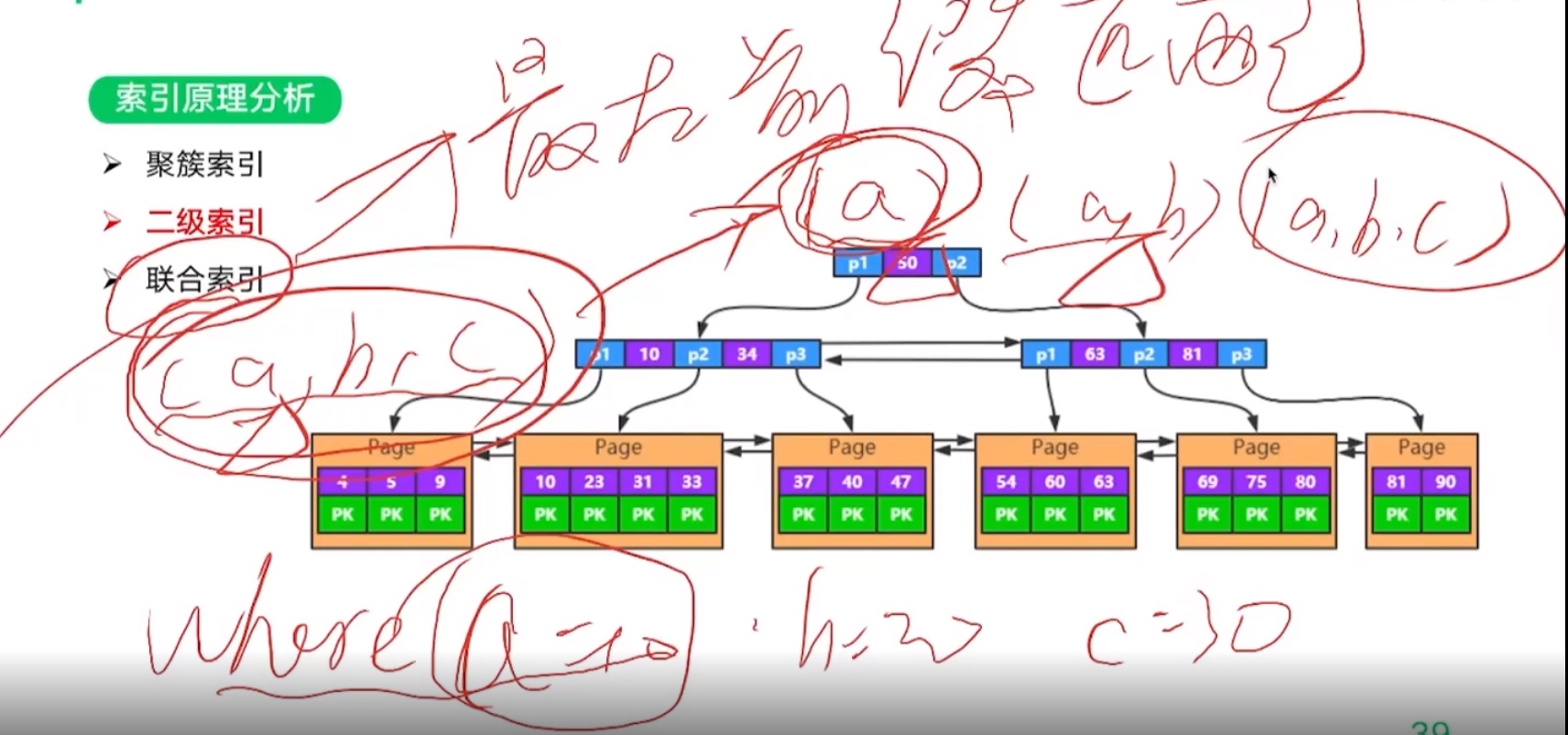
5. 索引下推优化(ICP)
where 过滤的三种方式:
a=10,c=30,d=50:
1. index key
1. where (a,b,c)==> 当用a=10 过滤时,会从索引树上找到对应的索引页
2. index filter (5.6之前,发生在server端;**ICP==》**5.6之后发生在搜索引擎端)
1. 当a=10过滤完了索引页之后,c=30在索引页页内过滤;
3. table filter(server层,把数据一条一条发送过去)
1. d不属于索引字段,但属于表字段
三、MySQL锁实现原理拆解以及设计 深度剖析
四、MySQL事物实现原理拆解及涉及 深度剖析

若有收获,就点个赞吧
0 人点赞
