1. 逻辑图
2. explain 查询当前sql语句状态
1. 示例
EXPLAIN SELECT * FROM `ba_act_type`;
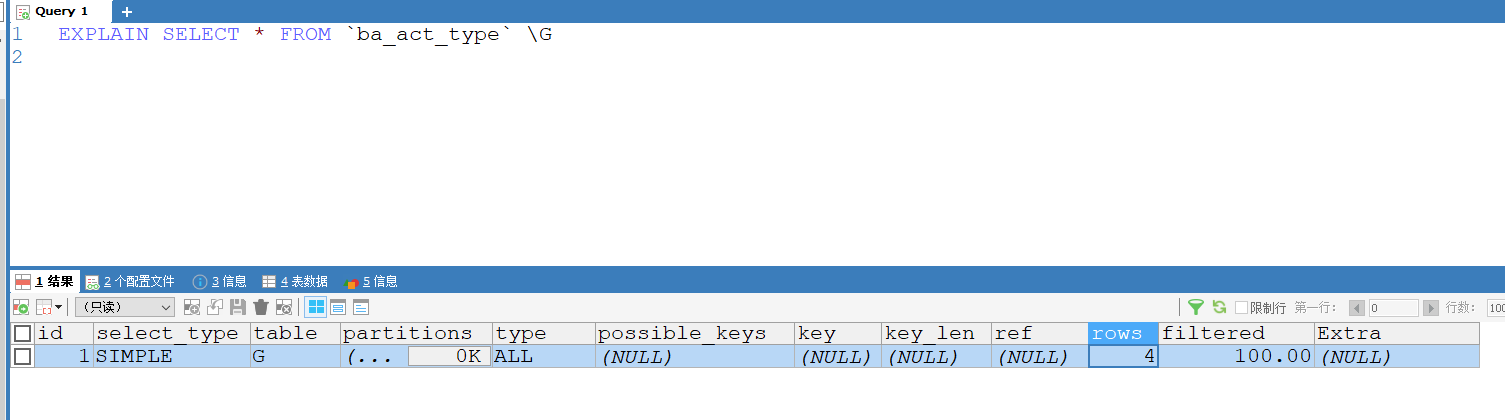
| id: 不是关键信息; table: 表名; select_type: 没啥用 partitions: 是不是分区表
type: 查询对应的类型—-》 常见的类型: (按照执行效率从高到低) systm > const > ref > range > index > all
all: 全表扫描; 保证达到range级别
possible_key: 可能用到的索引 ,意义不大
key: 实际用没用到索引, 尽量不要为空
extra: 额外的信息,using index condition: 索引下推, using index:使用了索引覆盖 using filesort使用了临时空间进行排序 |
| —- |
2. 分库分表最新的技术 sharding sphere

3. 索引
| 用途: 提高查询效率
设计索引要考虑的因素:
1. 索引和行数据具体存在什么地方?——》索引和实际的数据都是存在磁盘的,只是在进行数据读取的时候,优先把索引提取到内存中; 要判断是什么存储引擎:不同的数据文件在磁盘中的不同组织形式
mysql中每个数据表有2个不同的后缀, frm个ibd:
frm: 表结构;
ibd: 索引和数据<—-innodb
myisam数据库是三个文件: frm,MYD, MYI: myd: data, myi: index
2. 存储什么信息
2. 什么格式的数据: key-val : hashmap, tree, B+ tree
|
| —- |
| 查询搜索引擎方法: |
|
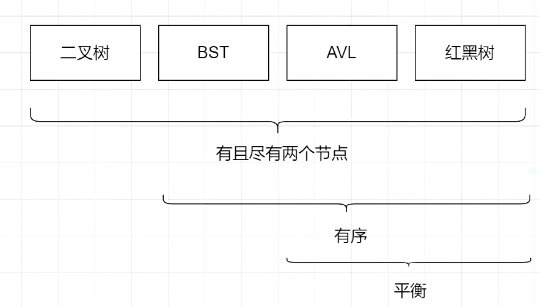
1. 数据结构 1. 设计原则 1. 优化 1. 失效 1. 回表 1. 索引覆盖 1. 最左匹配 1. 索引下推 1. 聚簇索引 |
|---|
3. Mysql索引的实现原理和数据结构
| B+ tree: 当表中数据量很大,索引也变得很大。 如果索引太大无法加载到内存中,该怎么办?—-》分块读取:16G=1G+1G+1G….——-》分而治之思想:1)减少IO量——》一次读4KB/8KB/16KB; 2)减少IO次数 |
|---|
| 操作系统: 1. 局部性原理: 事件局部性:之前被访问过的数据很有可能再次被访问 空间局部性:数据和程序都有聚集成群的倾向—-》把具有某些特征的数据放在一起 2. 磁盘预读: 内存跟磁盘在进行交互的时候,有一个最小的逻辑单位,称之为data page, 一般为4KB或8KB,由操作系统决定。在读取数据的时候,一般读取最小页的整数倍。Innodb一次读取16KB; |
| 为什么是B+树? hash表的缺点:  1. 需要好的hash算法,否则会产生hash碰撞,同时保证数据足够散列(上图中,0,2,3,5,6,7位置没有数据,而1,4位置数据聚集,导致散列不够); 2. hash表数据是无序的,所以需要进行范围查找时,需要逐个遍历,导致效率低下; 《memory存储引擎支持的是hash索引,innodb引擎支持的是自适应hash》 自适应hash: innodb四大特性之一 tree: 1. 共同点: |
2. 劣势:
1. 当插入更多数据时候,会发生自旋现象,使得树变得非常高—-》树深了,使得IO次数变得更多,每一层对应一次IO,影响查询效率
3. 解决问题:
1. 变深的根源是只有2个分支,可以增加分支。 10,20,30,40可以有5个分支——》B树
《查看数据结构的网站: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html》
B树:
1. 结构:
多分枝,包含数据和区间的指针;
无重复数据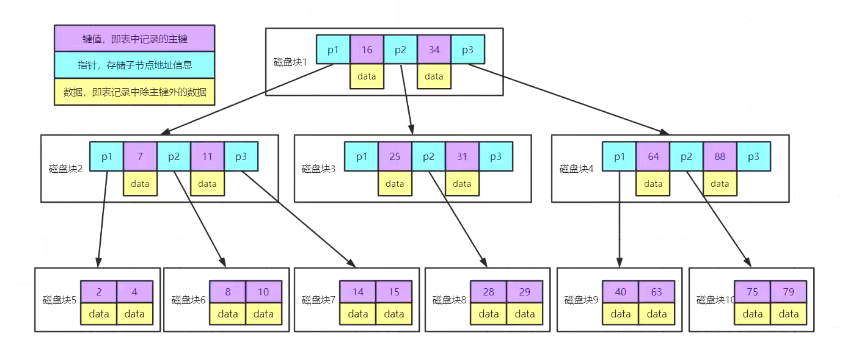
2. 缺点:
数据部分占据了大量的空间,如果数据量太大,就会导致树的高度很高,就会多次IO,影响效率。
3. 解决:
B+树, 数据部分存在最底层数据层,其他层全是索引
B+树
1. 结构:
叶子节点之间有指针连接; 有重复数据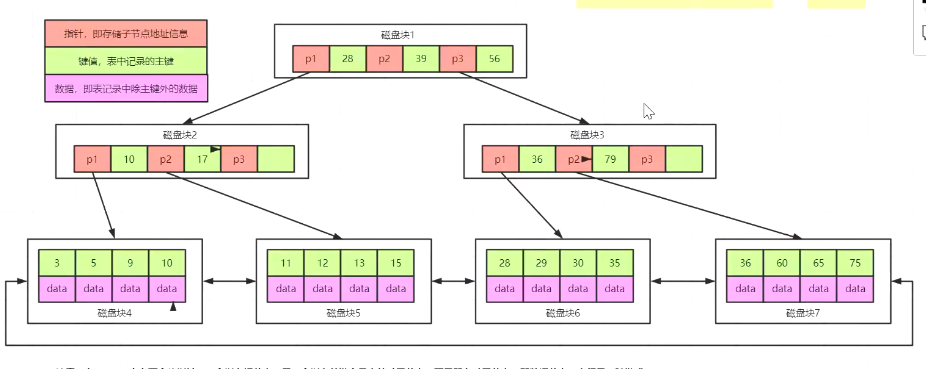
2. Mysql的B+树一般是多少层?
一般情况下,3—4层的B+树足以支持千万级别的数据;
3. 数据库选择索引用int类型还是varchar?
int: 4bytes
varchar():括号内指定的长度来决定
所以: 小于4,则用varchar, 大于4, 用int
墨守成规的规定: 让key尽可能占用存储空间
4. 优化点
varchar(20), 但是实际上有些占用4个字节,有些占用16个字节,但是varchar规定每个单元格是20个字节,就造成了浪费。 此时需要使用前缀索引, 即把索引的某些部分当作索引(比如前3个字节/前4个字节),其他不重要的部分则忽略;
5. 数据库中的基数:
与优化索引有关。
定义: DV(distinct value) 唯一值大概有多少,根据唯一值进行筛选前缀索引。
截取前3位数,差距很大,不合适: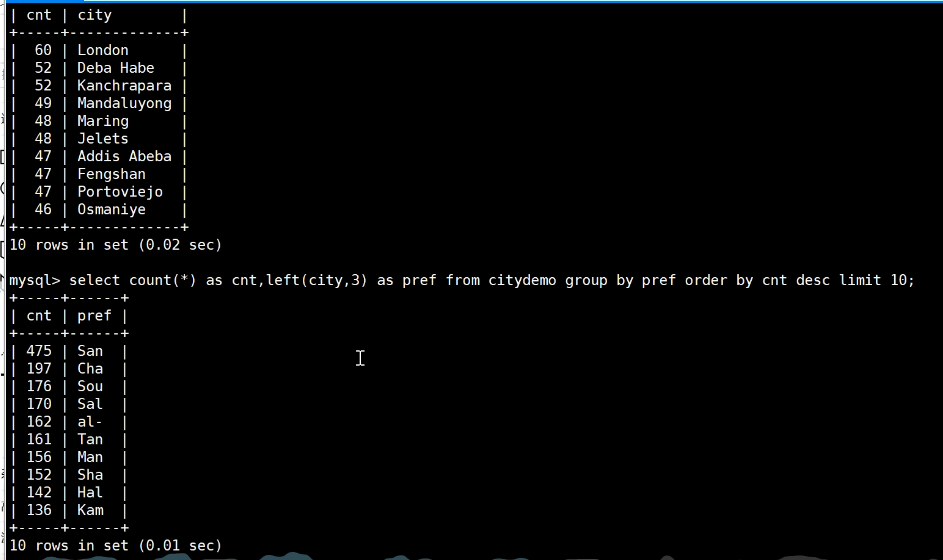
截取前5个字符,数据差异小了很多: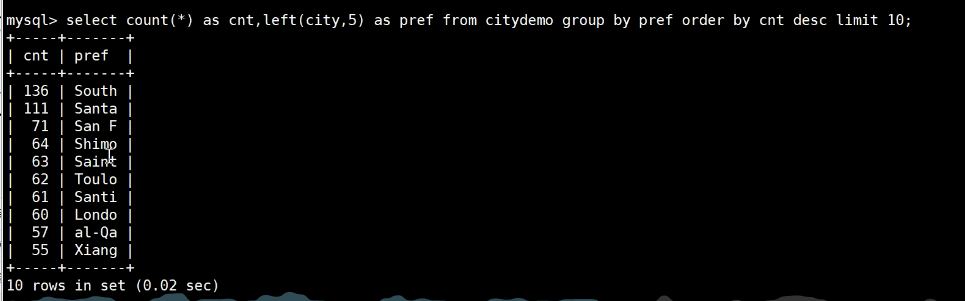
截取前7位,差距更小: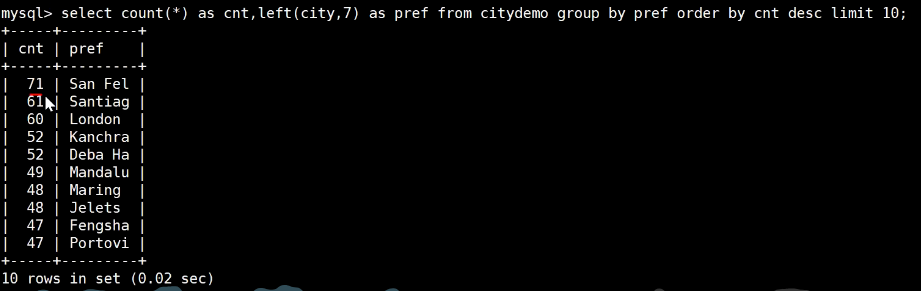
创建前7位索引的前缀索引的办法:sql
alter table 表名 add key(索引名(7))
6. 基数计算的算法 hyperloglog
|
4. 聚簇索引和非聚簇索引
1. 判断依据:
1. 索引和数据存储在一起的叫聚簇索引;没有存储在一起的叫非聚簇索引。
1. innodb存储引擎在进行数据插入的时候,数据必须要跟某个索引列存储在一起。这个索引可以是主索引(主键),也可以是其他索引。如果没有主键,就选择唯一键,没有唯一键就选择6字节的rowId进行存储。
1. 数据必须是跟某个索引绑定在一起的,此时绑定数据的索引叫聚簇索引。
1. 其他索引的叶子节点中存储的数据不再是整行的结构,而是聚簇索引的id值,

5. innodb中既有聚簇索引,也有非聚簇索引。 而myisam中只有非聚簇索引(其原本的索引和数据本就是分文件存放的)。
2. 回表
id, name, age, gender
id: 主键 name:普通索引
查询语句: select from table where name=”张三”;
检索过程: where name=”张三”—>from table—> select
分析: 根据 name的B+树匹配到对应的叶子节点,查询到对应的行记录 id——>再根据 行 id的B+树检索整行记录。这个过程就称之为回表。——》效率很低,尽量避免回表。
3. 索引覆盖
id, name, age, gender
id: 主键 name:普通索引
查询语句: select id,name from table where name=”张三”;
分析: 根据name的值去name的B+树检索对应的记录,能获取到id的属性值, 索引的叶子节点中包含了查询的所有列,此时不需要回表。 这个过程叫做索引覆盖。会出现using index的提示信息,效率很高。
关键优化点: 在某些场景中可以考虑将要查询的所有列都变成组合索引,此时会加快查询效率。
4. 最左匹配
创建索引的时候可以选择多个列来共同组成索引,此时叫做组合索引或联合索引,要遵循最左匹配原则。
id, name, age, gender
id: 主键 name,age: 组合索引
select from table where name=”张三” and age=12; (可以)
select from table where name=”张三”; (可以)
select from table where age=12; (没有name时不可以用age)
select from table where age=12 and name=”张三”; (把name和age调换顺序不会影响最终结果。在mysql中有个优化器,会自动帮助我们调整顺序,满足最左匹配)
牵扯到索引失效的问题:
select from table where age>12 and name=”张三”; (此时调换age和name属性,结果不变,所以索引不会失效)
select from table where age>12 and name=”张三” and gender=male; (此时gender=male的索引会失效)
5. 索引下推
select * from table where name=”张三” and age=12;
在没有索引下推之前: 根据name从存储引擎中拉取数据到server层,然后在server层对age进行数据过滤;
有了索引下推之后: 根据name和age两个条件进行数据筛选,将筛选后的结果返回给server层。
此时将server层条件过滤下推到存储引擎中。
索引下推是默认开启的。
下推减少了IO的数据量,很好。 |
| —- |
5. 如何回答面试中遇到的优化问题
技术+表达方式:
| 在工作中做过很多优化的问题,一般的优化我们并不是出现了问题才进行优化的,在数据库建模和数据库设计的时候会预先考虑到一些优化的问题,比如表字段的类型、长度等,包括创建合适的索引等方式,但是这种方式只是一种提前的预防,并不能解决所有问题。 所以在生产环境中出现sql问题后,我会从数据库的性能监控,索引的创建和维护,sql语句的调整,参数的设置,架构的调整等多个方面进行综合考虑。 在性能监控的时候,会选择show profiles,performance_schema来进行监控; 索引: 参数: 在我最近做的一个xx项目中,出现了一个xx问题,我通过分析执行计划以及xx的方式顺利解决了这个问题,并且在公司中做了技术分享,详细了解了对应数据库知识; 还有在另外一个xx项目中,。。。  |
|---|
6. mysql事物隔离性的实现原理
6.1 事物
6.2 锁
step1: 设置查看锁的参数: set global innodb_status_output_locks=1;
step2: show engine innodb status \G; —->此时没有锁
step3: select from table for update; ——>此时加锁了,有多少行就 有多少把锁,其他事物就无法更改数据库。也就意味着不存在幻读;
幻读:
事物1,事物2
step0: begin;——>开启事物
step1: select from table; —>两个事物都执行, 此时是快照读
step2: 事物2: insert into table values();
step3: 事物2: commit;
step4: 事物1: select from table; ——>延用step1中的快照读,意味着不能读到最新的数据,此时*产生幻读; 如果事物1也进行一次当前读,再进行快照读,那么就会更新readview,就会读到最新的数据。
乐观锁
悲观锁
行锁
表锁
记录锁
自增锁
意向锁
6.5 ACID的底层原理
6.3 MySQL中锁机制
MVCC: multi-version concurrency control 多版本并发控制
作用: 为了解决在并发访问时,提高数据库读写效率。
2个基本概念:
当前读:读取的是数据的最新版本,总是读取到最新的数据;
快照读: 读的是历史版本记录;
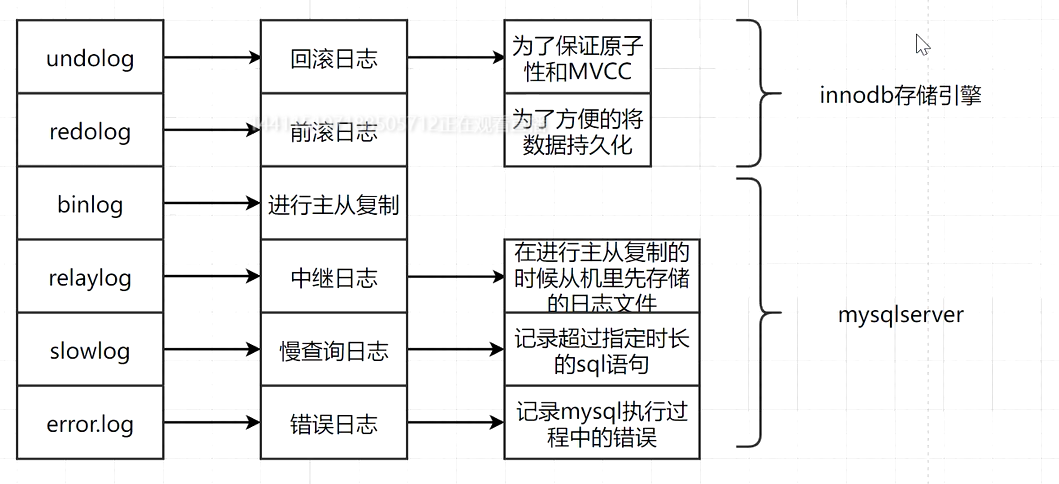
回滚的时候,历史数据并不是以一个单纯的数据文件存在的,而是通过undo_log (回滚日志) 的形式出现的。
什么时候sql语句会当前读?什么时候快照读?
当前读语句:
select …. lock in share mode;
select …. for update; for update是加了锁
update
delete
insert
快照读:
select …
实现场景:
A事物 B事物
step1: select 语句 select语句
step2: 无 update—》commit的操作
step3: select 语句—-》此时能读取B事物更新后的数据吗?
事物的隔离级别:
读未提交
读已提交(RC)——可以读取到最新的结果记录
可重复读(RR)(默认的隔离级别)———->不可以读取到最新的结果记录
串行化 ————> 加锁,一个挨着一个的读写过程
出现差异的原因: MVCC——>可见性算法
6.4.1 MVCC原理
第一部分: 隐藏字段:每一行记录中都会包含几个用户不可见字段,
DB_TRX_ID:最近 创建/修改 该记录事物的ID;
DB_ROW_ID: 隐藏主键
DB_ROW_PTR: 回滚指针, 配合 undo_log一起完成回滚的功能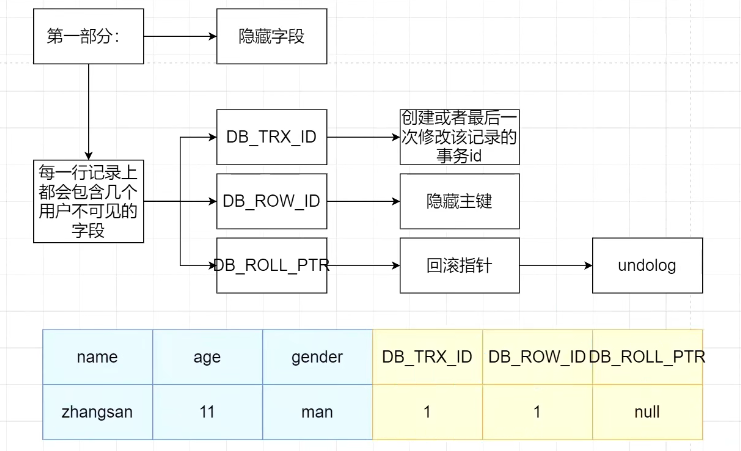
第二部分:undo_log 回滚日志
保存的是历史版本状态。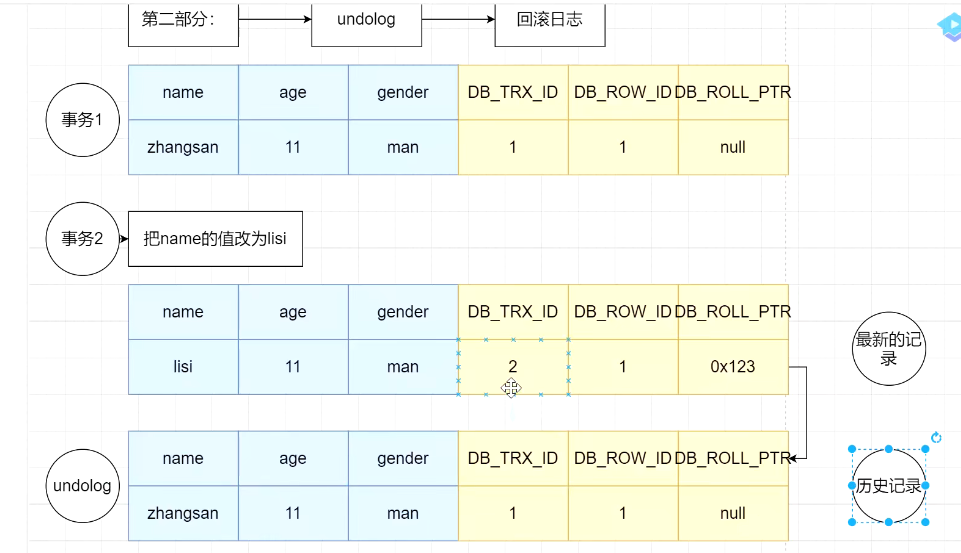
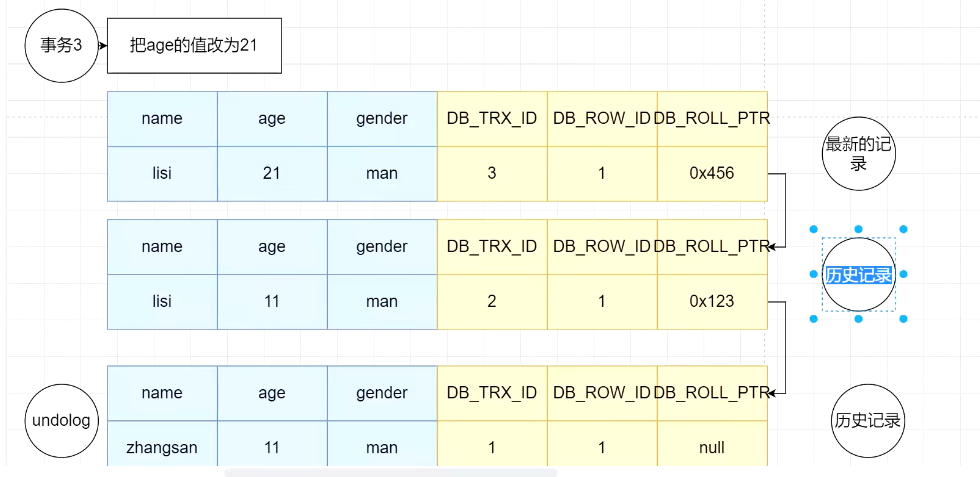
当不同的事物对同一条记录做修改时,会导致该记录的undolog形成一个线性表,也就是链表,该链表的链首是最新的记录,链尾是最早的记录。
Q: 现在有了事物4,那么事物4读取的数据是哪一个版本的数据?—-需要按照规则读取
有几个问题没有说:1)事物是否提交? 2)四个事物开启的时机
第三部分: readview 事物在进行快照读的时候,产生的读视图
readview包含的组件:trx_list: 当前系统活跃的事物id;
up_limit_id: 列表中事物最小的id
low_limit_id: 系统尚未分配的下一个事物id
实际场景:
事物1 事物2 事物3 事物4
step1: update;commit
step2: 快照读
Q: 事物2的快照读可以读到事物4更新后的数据吗?——>可以
可见性算法
readview生成的时机是不同的。
RC(read committed): 每次在进行快照读的时候,都会生成新的readview
RR: 只有第一次进行快照读的时候才生成readview, 之后的读操作都会用第一次生成的readview.
案例2: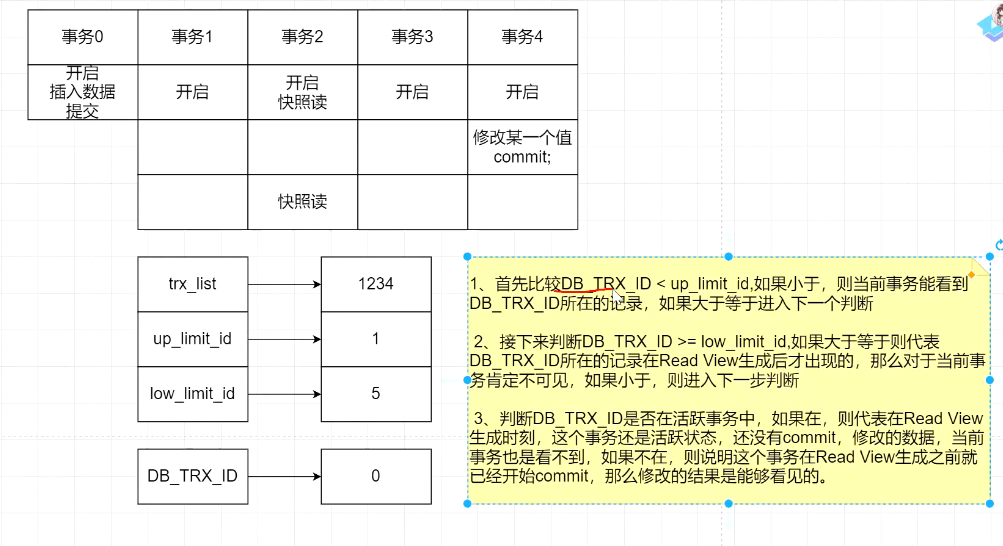
注意:上图中DB_TRX_ID是事物0 提交后,事物2的快照读的情况;
如果事物2快照读了,则能看到事物0已提交的数据;
紧接着, 事物4修改某个值。随后事物2再次快照读, 如果事物4没有提交,在RR隔离级别时,是读不到事物4修改的数据; 如果事物4提交了,则可以读到事物4的数据。
6.4 事物的特性
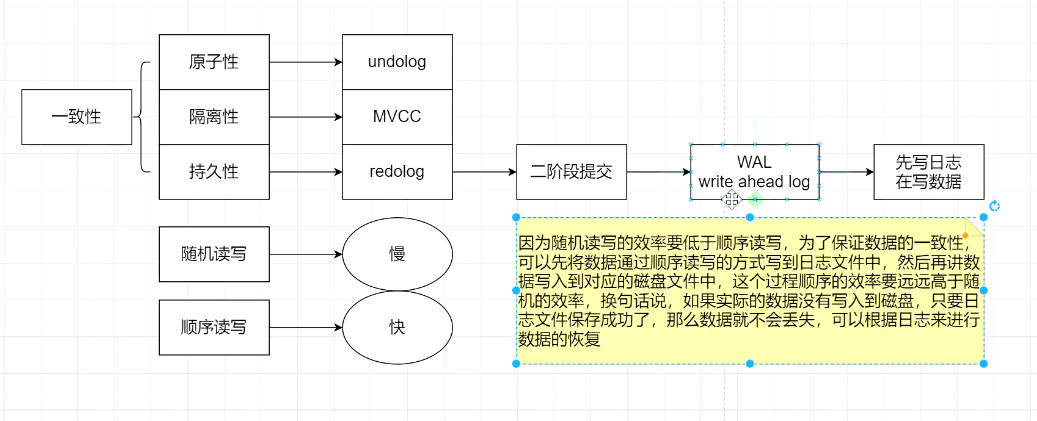
1. 原子性:依赖undolog实现
1. 一致性:依赖其他3个特性
1. 隔离性:通过MVCC实现
1. 持久性:通过redolog实现——> 会出现二阶段提交:有WAL机制(read ahead log):预写机制
欲写机制:先写日志后写数据;
随机读写: 速度慢
顺序读写: 速度快, 用append方式添加记录
两阶段提交: mysql的日志文件: binlog innodb是插件引擎,有undolog和redolog
为了保证redoLog和binlog数据保持一致,所以有了二阶段提交的概念。写日志时,先写redolog,后写binlog. 回复时,先恢复binlog,后恢复redolog。 redolog是两阶段: 第一阶段修改后,状态改为prepare,再写binlog,后续再将redolog状态改为commit状态。
一般只需要判断binlog是否成功,binlog成功就几乎没有问题了,除非redolog磁盘损坏。
主从复制: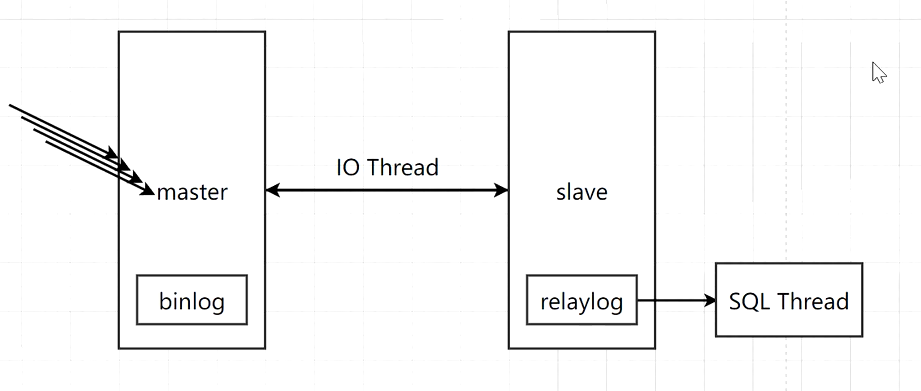
6.6 Java中不加锁实现锁的机制:
CAS: compare and swap 比较并替换
| | —- | | | | | | |

若有收获,就点个赞吧
0 人点赞
