一、概念
- DB: database
- DBMS: database management system —> Mysql\ oracle\ DB2\ sqlServer
- SQL: structure query language
- SQL语言分类:
- DML: data manipulation language : 数据操纵语言。增删改查
- insert update delete select
- DDL: data defination language: 数据定义语言,用于数据库和表得创建、修改、删除:
- create table ; alert table; drop table; create index; drop index;
- DCL: data control language : 数据控制语句。 定义用户的访问权限和安全级别:
- grant : 授予访问权限
- revoke: 撤销访问权限
- SQL语言分类:
- 数据库中有表,表中有数据;
- 每张表有唯一的表名
每张表中有一个或多个列,相当于Java、python中的“属性”
2. 主键、外键、索引
主键: 可以代表表中某一行的属性或属性组; 注:主键可以是一个属性,也可以是2个属性共同组成属性组
- 外键: 用于加强2张数据表中的一列或多列。 eg: a表(student)中的student_id作为主键, b表(course) 中也需要student_id字段,此时student_id在b表中就充当外键,使得a表和b表产生关联; ——》此时,要删除a表中的student_id时,就需要确认b表中的student_id是否与其关联。
- 索引: 快速定位的属性。
三者关系: https://blog.csdn.net/weixin_33816611/article/details/92214124?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1.pc_relevant_default&utm_relevant_index=2
三、mysql的使用
- 登录:
- mysql -uroot -p123456
- mysql -h localhost -P3306 -uroot -p123456 // 端口号
- 常见命令:
show tables from mysqlDatabases; // 直接换库select version(); //查版本mysql-- versiondesc 表; // 查表结构
四、 DQL语言的学习
0.创建表
CREATE TABLE `departments` (
`department_id` int(4) NOT NULL AUTO_INCREMENT,
`department_name` varchar(3) DEFAULT NULL,
`manager_id` int(6) DEFAULT NULL,
`location_id` int(4) DEFAULT NULL,
PRIMARY KEY (`department_id`),
KEY `loc_id_fk` (`location_id`),
CONSTRAINT `loc_id_fk` FOREIGN KEY (`location_id`) REFERENCES `locations` (`location_id`)
) ENGINE=InnoDB AUTO_INCREMENT=271 DEFAULT CHARSET=gb2312;
0.1 增加索引
给parts表增加名为index_mod 的索引,是建立在model字段上的
alter table parts add index index_mod(model);



0.2 增加外键(即增加一种“约束”)
因为pc(computer)表中需要用到配件 cpu信息,即pc表中的外键; 而配件表(parts)中cpu需要作为主键;
alter table pc add constraint fk_cpu_model
forgeign key(cpuModel)
references parts(model)
ON UPDATE CASCADE;
| 第一行是说要为Pc表设置外键,给这个外键起一个名字叫做fk_cpu_model; 第二行是说将本表的cpumodel字段设置为外键; 第三行是说这个外键受到的约束来自于Parts表的model字段。 第四行:在主表更新时,子表(们)产生连锁更新动作,似乎有些人喜欢把这个叫“级联”操作。 |
|---|
1. 删、改
1. 增加字段 add
alter table Phone_table add color varchar(20);
2. 删除字段 drop
alter table phone_table drop color;
3. 修改字段数据类型 modify
alter table phone_table modify name varchar(12);
4. 修改字段的数据类型并且改名
alter table phone_table name pname char(18);
5. drop table
drop table user;
6. 删除表数据,不删除表结构,速度第二,不能和where联用
truncate table user;
7. 删除表数据,不删除结构,速度最慢,但可以和where联用
delete from user where user_id=1;
详细解读:
https://blog.csdn.net/weixin_39755890/article/details/111260075?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-0.no_search_link&spm=1001.2101.3001.4242.1
8. 添加外键约束
ALTER TABLE <数据表名> ADD CONSTRAINT <外键约束名>
FOREIGN KEY(<列名>)
REFERENCES <主表名> (<列名>);
alter table pc add constraint fk_cpu_model
forgeign key(cpuModel)
references parts(model)
ON UPDATE CASCADE;
9. 删除外键约束 drop
ALTER TABLE <表名> DROP FOREIGN KEY <外键约束名>;
10. 修改表时创建外键约束
ALTER TABLE <数据表名> ADD CONSTRAINT <外键名>
FOREIGN KEY(<列名>) REFERENCES <主表名> (<列名>);
11. 修改元素内容 set
# DIRECTOR table (update statements)
UPDATE DIRECTOR
SET GENDER='Male'
WHERE `FIRSTNAME` ='Laurence' AND `LASTNAME` ='Wu'
2.插入数据
insert into `departments`(`department_id`,`department_name`,`manager_id`,`location_id`) values (10,'Adm',200,1700),(20,'Mar',201,1800),(30,'Pur',114,1700),(40,'Hum',203,2400),(50,'Shi',121,1500),(60,'IT',103,1400),(70,'Pub',204,2700),(80,'Sal',145,2500),(90,'Exe',100,1700),(100,'Fin',108,1700),(110,'Acc',205,1700),(120,'Tre',NULL,1700),(130,'Cor',NULL,1700),(140,'Con',NULL,1700),(150,'Sha',NULL,1700),(160,'Ben',NULL,1700),(170,'Man',NULL,1700),(180,'Con',NULL,1700),(190,'Con',NULL,1700),(200,'Ope',NULL,1700),(210,'IT ',NULL,1700),(220,'NOC',NULL,1700),(230,'IT ',NULL,1700),(240,'Gov',NULL,1700),(250,'Ret',NULL,1700),(260,'Rec',NULL,1700),(270,'Pay',NULL,1700);
3.查询字段
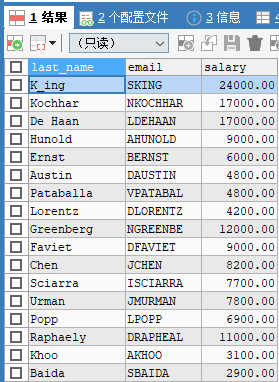
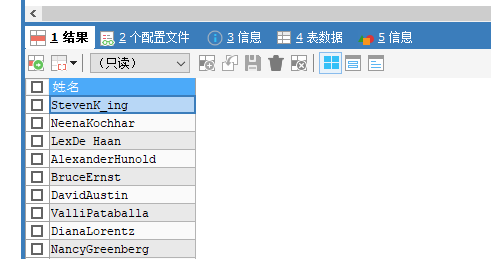
USE myemployees;
SELECT last_name,email,salary FROM employees;
4.查询常量值
USE myemployees;
SELECT 100;
5.查询表达式
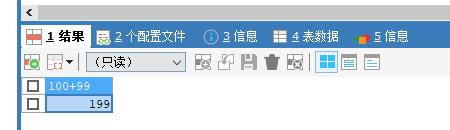
USE myemployees;
SELECT 100*98;
6.查询函数
USE myemployees;
SELECT VERSION();
7.为字段起别名
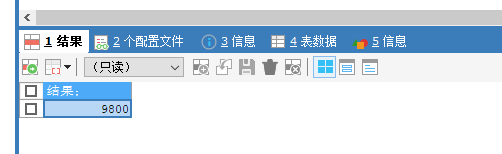
select 100*98 as 结果;
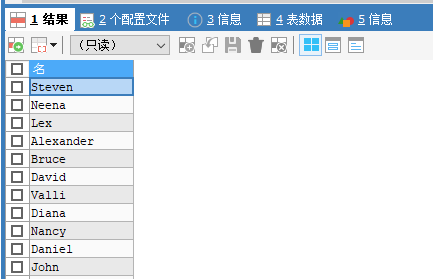
SELECT first_name AS 名 FROM employees;
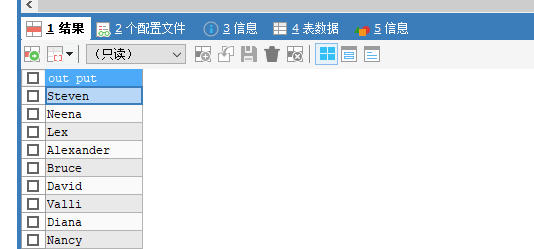
SELECT first_name AS "out put" FROM employees;
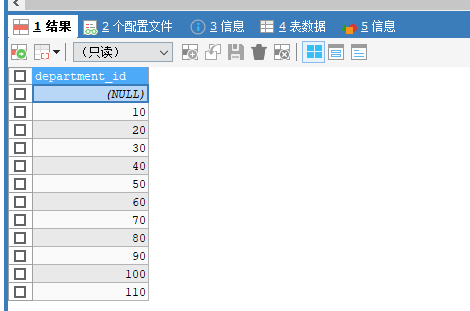
8. 去重—distince
SELECT DISTINCT department_id FROM employees;
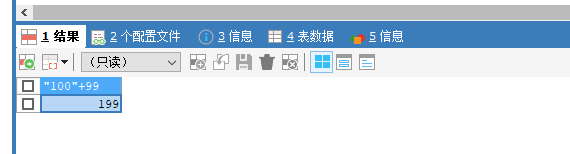
9. +号的作用
eg: 查询姓 和名 连接成一个字段,并显示为姓名
Java中: + 号的作用:
1. 运算符, 连个操作数都为数值型;
2. 连接符:字符串
- sql中只有一个功能: 运算符:
11. 练习
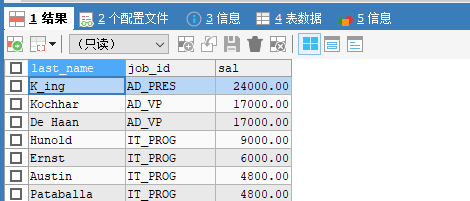
select last_name,job_id,salary as sal from employees;
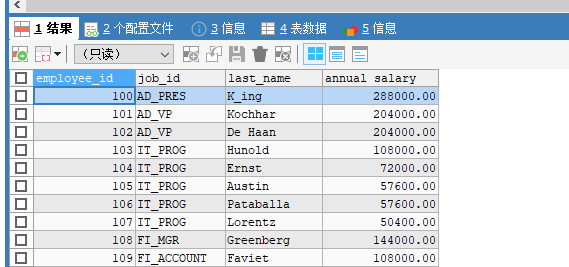
select employee_id, job_id, last_name, salary*12 as `annual salary` from employees;
DESC departments;
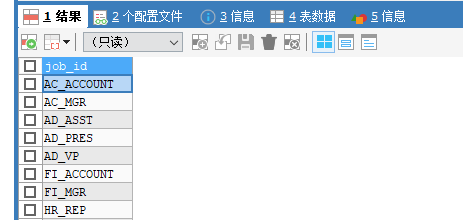
SELECT DISTINCT job_id FROM employees;
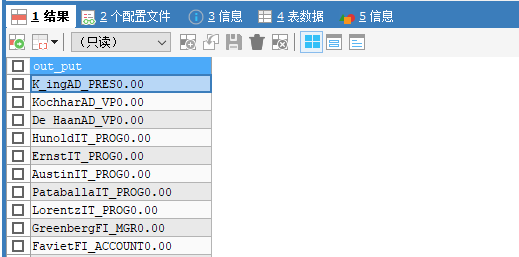
// 显示出表employees的全部列,各个列之间用逗号连接,列头显示成out_put
SELECT
CONCAT(`last_name`,`job_id`,IFNULL(`commission_pct`,0))
AS out_put
FROM employees;

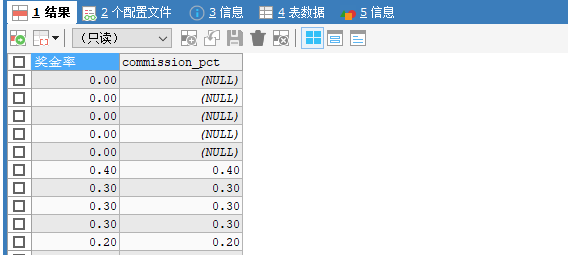
12. 拼接空值时防止全部为null—-IFNULL
USE myemployees;
SELECT IFNULL(`commission_pct`,0) AS `奖金率`, commission_pct FROM employees;
五、条件查询
1. 语法
select
查询列表
from
表名
where
筛选条件;
----------》 当筛选条件成立时,结果显示出来;当结果不成立,pass掉。 相当于if判断;
-----------》执行顺序:
1. from 表: 查看有没有此表;
2. where语句: 查看该表中有没有符合条件的行;
3. select语句:输出想要的列;
2. 筛选的分类
1. 按条件表达式筛选
条件运算符: > , <, =, <>(不等于), >=, <=
2. 按逻辑表达式筛选
逻辑运算符: &&, ||, !
and , or, not
逻辑运算符的作用:用于连接条件表达式。
3. 模糊查询
3. 实践
1. 按条件表达式筛选
SELECT * FROM employees WHERE salary>12000;

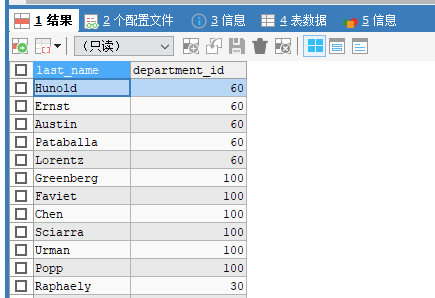
SELECT last_name, department_id FROM employees WHERE department_id<>90;
2. 按逻辑表达式筛选
工资在10000—-200000的员工名,工资,奖金
SELECT last_name, commission_pct FROM employees WHERE salary>=10000 AND salary<=20000;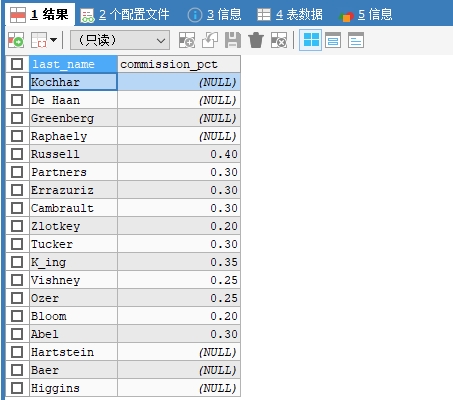
查询部门编号不是在90-120之间的,或者工资高于15000的员工信息
SELECT * FROM employees WHERE department_id<90 OR salary>15000;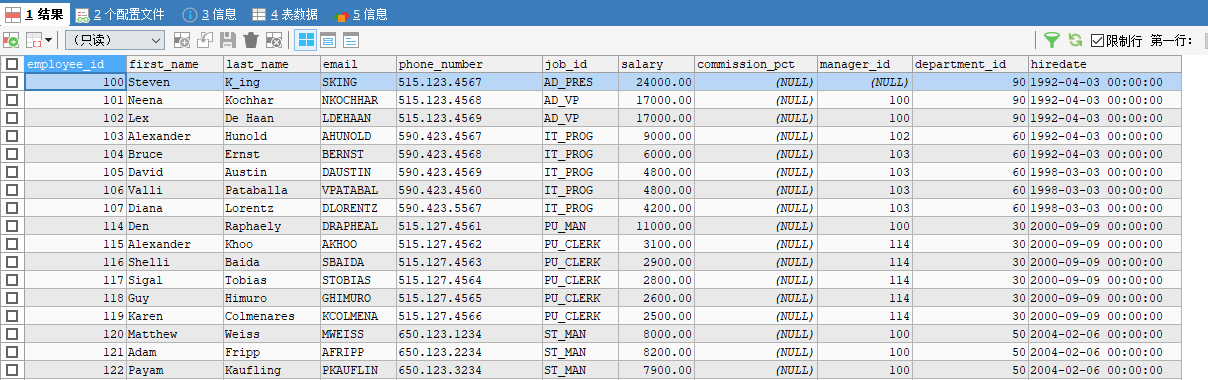
3. 模糊查询
like
between and
in
is null
查询员工名中包含"a" 的员工信息
SELECT * FROM employees WHERE last_name LIKE 'a%';
like 一般和通配符搭配使用:
%: 任意多个字符,包含0个字符
_: 任意单个字符
# 查询员工名中第三个字符为e,第五个字符为a的员工名和工资
SELECT last_name,salary FROM employees WHERE last_name LIKE '__e__a%';
SELECT last_name,salary FROM employees WHERE last_name LIKE '__n__l%';
# 通过escape进行转义,来查询符合条件的数据
SELECT * FROM employees WHERE last_name LIKE '_$_%' ESCAPE '$'; escape可以是任意内容,不一定非要'\'或'$'
转义:特殊符号在当前语句中实际是普通符号,取其真实含义


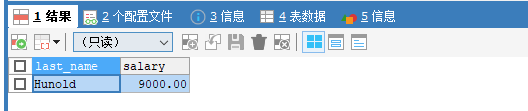

包含临界值
【】等价于: employee_id>=100 and employee_id<=200, 所以前后顺序不能变换
SELECT * FROM employees WHERE employee_id BETWEEN 100 AND 200;
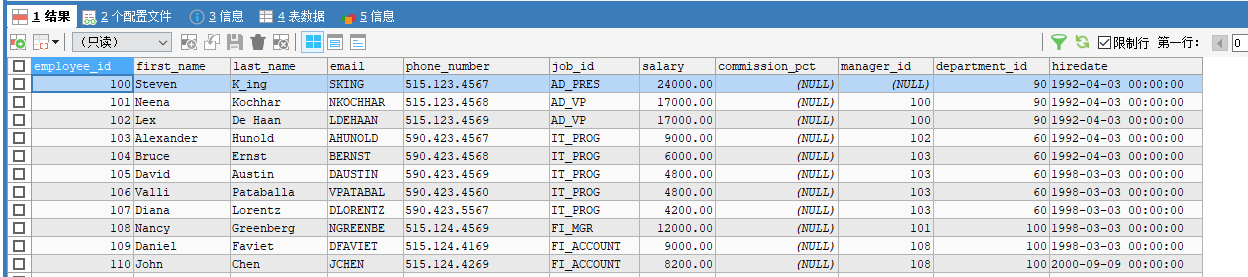
in 语句:
括号的值不可以用正则表达式
SELECT *
FROM employees
WHERE job_id
IN ('AD_PRES','AD_VP','IT_PROG'); // 值的类型必须统一或兼容, 用''
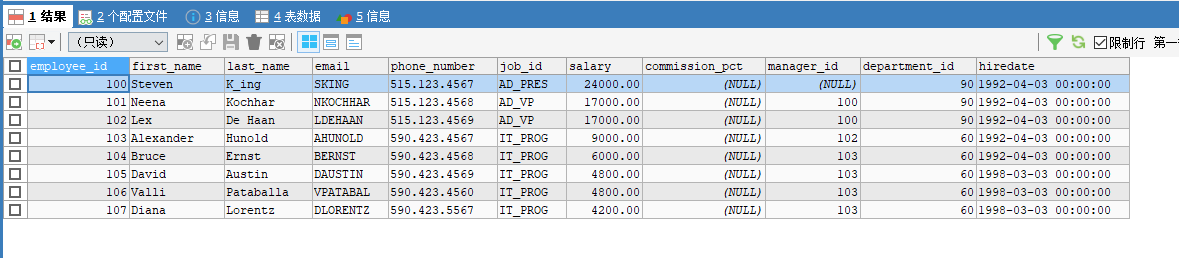
判断null值
SELECT * FROM employees WHERE `commission_pct` IS NOT NULL;
判断不等于字符: <>
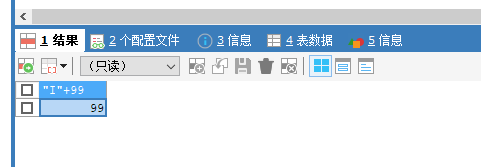
select * from employees where job_id <> "IT";
或者:SELECT * FROM employees WHERE job_id != "IT";
注意: 没有 is not "IT"
注意: 没有 is not “IT”
4. 实战
select * from employees;
select * from employees where commission_pct is like "%%" and last_name like "%%";
二者结果不一样。 当commission_pct为null,获取不到其信息
SELECT last_name,salary,commission_pct FROM employees WHERE commission_pct LIKE '%%';
如果想避免null值情况,则更改为:
select * from employees where commission_pct like '%%' or last_name like '%%' or employee_id like '%%';
三者取并集,只要不出现同时为null,则所有数据都会取到。
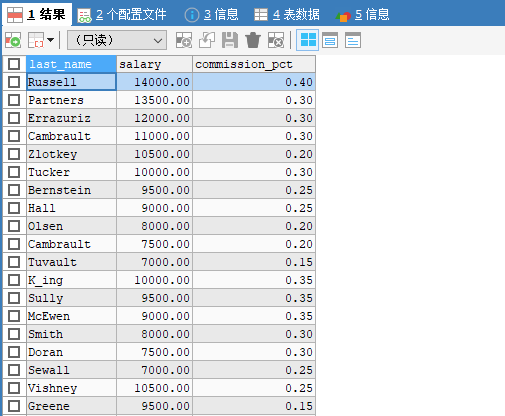
六、排序查询— order by
order by是在分组情况下进阶的排序;
一般情况下是放在查询语句最后面;
但是如果有limit,则表明是结果分页,limit在最后。
1. 语法
select *
from 表
where 筛选条件
order by 排序列表 【asc | desc】
2. 案例
1.简单排序
SELECT *
FROM employees
ORDER BY salary ASC; // asc不写默认是升序

2. 筛选加排序
SELECT *
FROM employees
WHERE department_id >= 90
ORDER BY hiredate ASC;
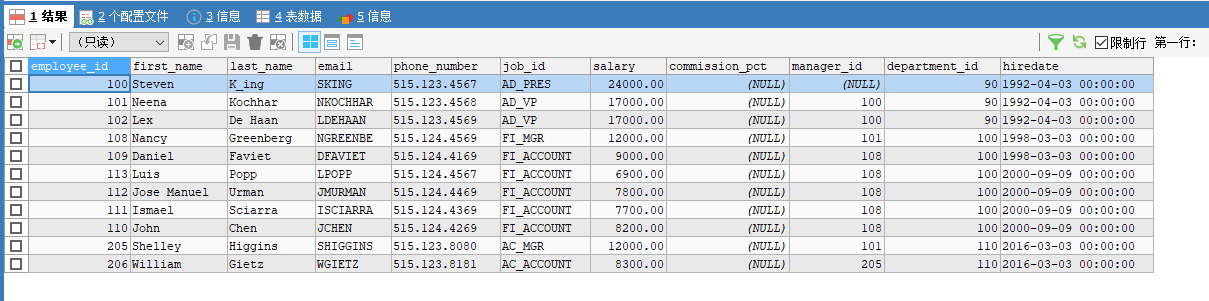
3. 按别名排序
按表达式,年薪高低和年薪 — 需要null值
SELECT *, salary*(1+IFNULL(commission_pct,0)) AS 年薪
FROM employees
ORDER BY 年薪 ASC;
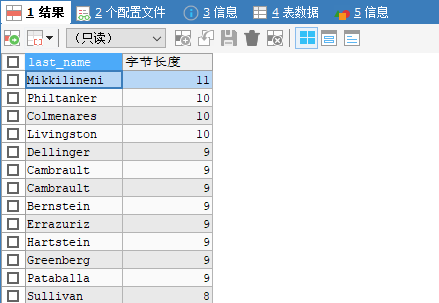
4. 函数排序
按姓名的长度排序(函数排序)
SELECT last_name,LENGTH(last_name) 字节长度
FROM employees
ORDER BY 字节长度 DESC;
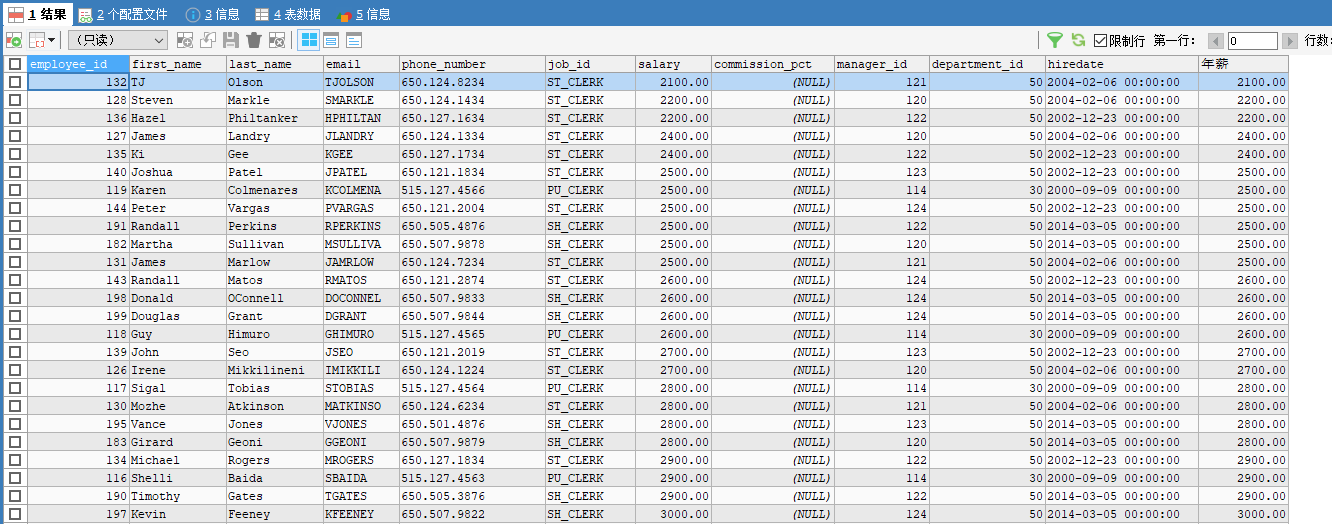
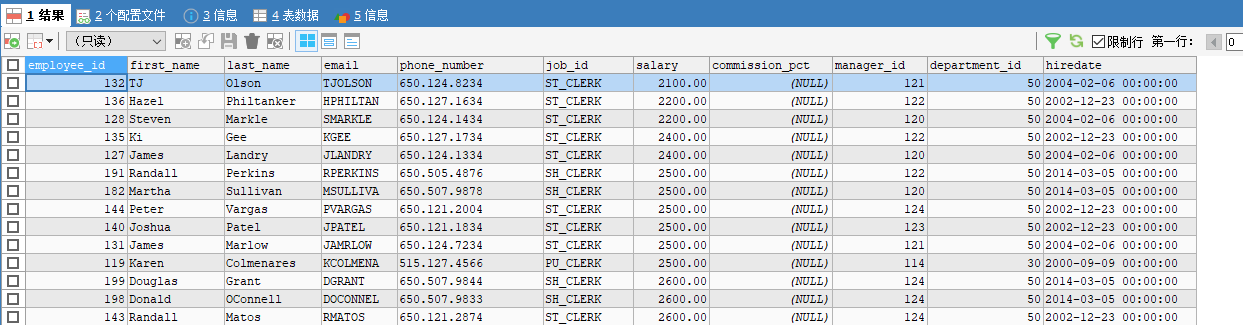
5. 双条件排序
先按工资排序,再按员工编号排序 —- 按条件顺序依次写(前面是整体主要排序,后面是次要的局部补充)
SELECT *
FROM employees
ORDER BY salary ASC,employee_id DESC;
七、常见函数
1. 单行函数
1.1 定义:传进一个值,返回出来
1.2 常见的分类:
1.2.1 字符函数: 参数为字符,
1. length('job');
1. concat('last_name','_','first_name');
1. upper('job');
1. lower('job');
1. substr('李莫愁爱上了陆展元',6); ==>"陆展元" mysql下标从1开始
1. substr('李莫愁爱上了陆展元',1,3); ==》"李莫愁"
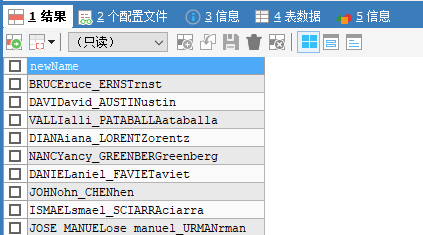
1. 示例: 将姓名中首字符大写,其他字符小写,然后拼接,显示出来
1. SELECT CONCAT(UPPER(SUBSTR(first_name,1)),LOWER(SUBSTR(first_name,2)),'_',UPPER(SUBSTR(last_name,1)),LOWER(SUBSTR(last_name,2))) AS newName FROM employees;
1. 
7. instr --->返回字串在原来的字符串的第一次索引。如果找不到,返回0
7. trim ----> 去左右空隔
1. select trim('a' from 'aaaaa张翠山aaa') as out_put;
9. lpad
1. 用指定的字符实现左填充。 select lpad('殷素素',10,'*') as out_put;
10. rpad: 右填充
10. replace: 替换
1.2.2 数学函数: 传进的值为数值型,
12. round : 四舍五入
12. ceil: 向上取整,返回大于等于该参数的最小整数
12. floor: 向下取整
12. truncate: 截断
12. mod: 取余,取模。= “%”
1.2.3 日期函数:
17. now(): 现在
17. curdate(): 日期+时间
17. curtime(): 时间
17. YEAR(NOW()): 年
17. YEAR('1998-08-14');
17. YEAR(NOW());
17. str_to_date
1. SELECT STR_TO_DATE('1998-3-2','%Y-%c-%d') AS out_put; 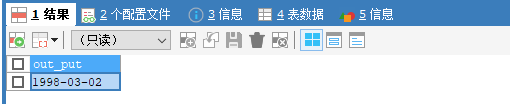
1. SELECT * FROM employees WHERE hiredate=STR_TO_DATE('4-3 1992','%c-%d %Y');
1. 
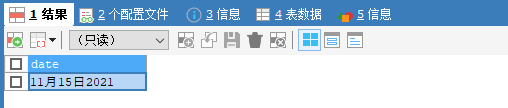
24. date_format: 将日期转为字符
1. SELECT DATE_FORMAT(NOW(),'%m月%d日%Y') AS DATE;
1. 
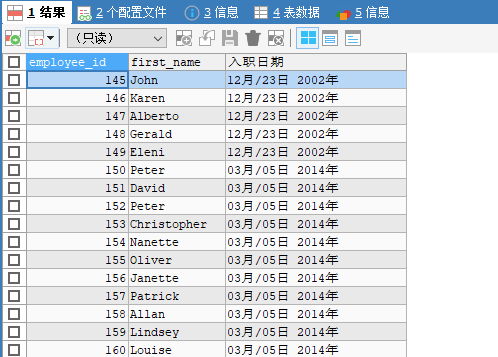
2. 查询有奖金的人的入职日期,日期格式:xx月/xx日 xx年
1. SELECT employee_id,first_name,DATE_FORMAT(hiredate,'%m月/%d日 %Y年')入职日期
FROM employees
WHERE commission_pct IS NOT NULL;
1.2.4 其他函数:version(); database(); user();
1. 流程空值函数:
1. if 函数
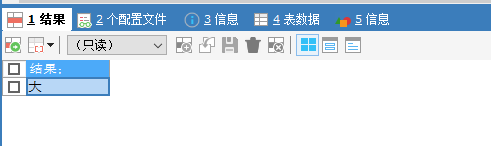
1. select if(10>5,'大','小') 结果;
1. 
2. case 函数
1. 使用一: switch case 效果
1. case要判断的表达式或字段 when 常量1 then 要显示的值;
1. select salary 原始工资, department_id case department_id when 30 then salary*1.1 when 40 then salary*1.2 when 50 then salary*1.3 else salary end as 新工资 from employment;
2. 使用二: 多重if
2. 分组函数
2.0 定义
传进一组值,最终返回一个值,做统计用的。也叫聚合函数、组函数
2.1 分类
1. sum() , avg(), count(), min(), max(),round()
eg1: SELECT SUM(salary) FROM employees;
null+数值=null
sum/avg/max/min方法都忽略了null值
2. 和distinct搭配使用
SELECT SUM(DISTINCT salary), SUM(salary) FROM employees;
3. count()详细介绍
- count(string)
- count(*)
- count(1)=count(*)=count(“翠霞”) // 相当于在原表中增加了1列
八、 分组查询
1. 案例
1. 查询每个部门的平均工资
SELECT department_id,AVG(salary) AS avg_salary FROM employees GROUP BY department_id;
2. 查询每个工种的最高工资
SELECT MAX(salary),job_id FROM employees GROUP BY job_id;
3. 查询每个位置上的部门个数
SELECT COUNT(*),location_id FROM departments GROUP BY location_id;
4. 添加筛选条件(分组前筛选)
查询邮箱中包含“a”字符的,每个部门的平均工资
SELECT AVG(salary),department_id FROM employees WHERE email LIKE '%a%' GROUP BY department_id;
查询有奖金的每个领导手下员工的最高工资
SELECT MAX(salary),manager_id FROM employees WHERE commission_pct IS NOT NULL GROUP BY manager_id;
5. 添加复杂的筛选(分组后筛选)—-having
5.1 筛选每个员工人数大于2的组的最高工资
where在group by 前面,所以 where的子句中不能包含group by分组,而是用havIng来筛选
step 1:统计符合条件的分组
select count(*) from employees group by department_id;
step2: 根据step1的结果筛选
select count(*),department_id from employees group by department_id having count(*) >2;
5.2 查询每个工种有奖金的员工的最高工资》12000 的工种编号和最高工资
step1: 查询每个工种有奖金的最高工资
SELECT job_id,MAX(salary) FROM employees WHERE commission_pct IS NOT NULL GROUP BY department_id;
step2: 对选出来的结果再进行一次筛选
SELECT job_id,MAX(salary) FROM employees WHERE commission_pct IS NOT NULL GROUP BY department_id HAVING MAX(salary)>12000;
5.3 查询领导编号大于102的每个领导手下的最低工资大于5000的领导是哪个
SELECT first_name,last_name,MIN(salary),manager_id
FROM employees
WHERE manager_id>102
GROUP BY manager_id HAVING MIN(salary)>5000;
6. 分组前筛选和分组后筛选的比较
- 分组前筛选:数据源是原始表; group by 子句的前面,用where子句
- 分组后:数据源分组后的结果集; group by子句的后面,用having + 筛选条件。
- 分组函数作为条件,肯定是放在having 子句中;
-
7. group by子句支持的内容
按表达式或函数分组
eg: 按员工姓名的长度分组,查询每一组员工的个数,筛选员工个数大于5的有哪些
SELECT department_id,LENGTH(last_name) L1,COUNT(*) FROM employees GROUP BY L1 HAVING COUNT(*)>5;
8. 按多个字段分组
eg: 查询每个部门每个工种的平均工资—-调换group by顺序不影响结果
SELECT AVG(salary),department_id,job_id FROM employees GROUP BY department_id,job_id;
9. 查询所有部门的编号,员工数量和工资平均值,并按平均工资降序
SELECT department_id AS d_id,COUNT(*),AVG(salary) FROM employees GROUP BY department_id ORDER BY AVG(salary) DESC;
9. 执行顺序
from: 1<br /> where: 2 -----》分组前筛选<br /> select: 3
group by: 4 ----》在此之前都是查询阶段<br /> having: 5 ----》 分组后筛选阶段
order by: 6 ----> 最终的结果order <br /> limit: 7 ----》 分页展示结果

若有收获,就点个赞吧
0 人点赞
