性能观察与诊断
训练集低:欠拟合
• 训练集高,测试集低:过拟合
(泛化能力不足)
• 训练集高,测试集高
过拟合
什么是过拟合
过度拟合,所选模型的复杂度比真实模型的复杂度高。
在训练集(training set)上表现好,但是在测试集上效果差
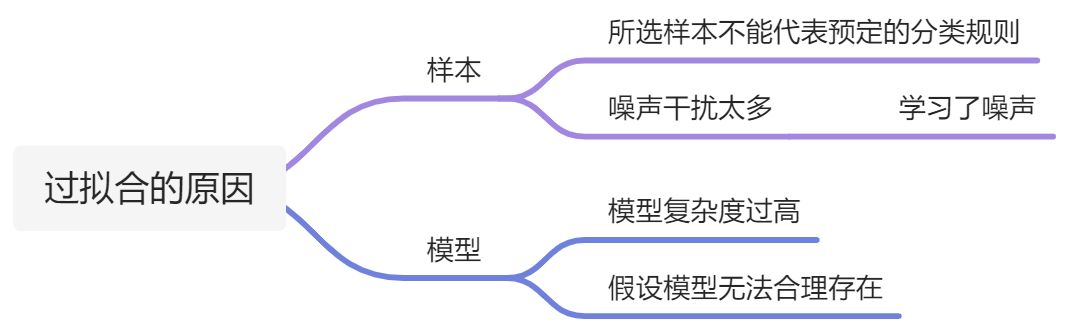
出现过拟合的原因
- 建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
- 样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
- 假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
- 参数太多,模型复杂度过高
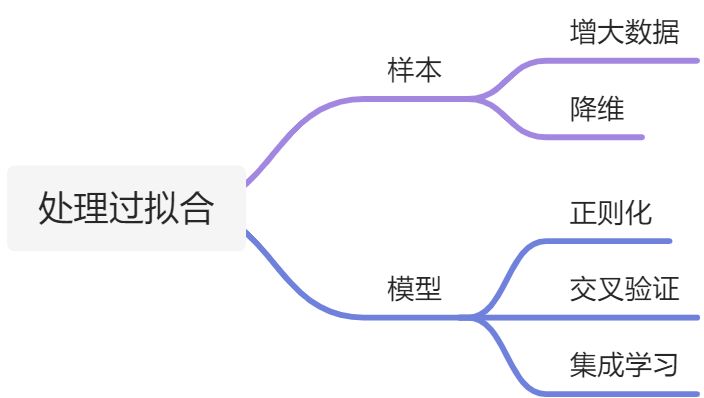
处理过拟合的办法
1.获得更多的训练数据
使用更多的训练数据是解决过拟合问题最有效的手段,因为更多的样本能够让模型学习到
更多更有效的特征,减小噪声的影响。
2.降维
即丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用一些
模型选择的算法来帮忙(例如PCA)。
3.正则化
正则化(regularization)的技术,使模型参数稀疏,常见的正则化方法包括L1、L2正则化。
dropout:按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络,减少神经元之间复杂的共适应关系
4.集成学习方法
集成学习是把多个模型集成在一起,来降低单一模型的过拟合风险,过
主要思想是:分别训练几个不同的模型,然后让所有的模型表决测试样例的输出
5.交叉验证
欠拟合
处理欠拟合的办法
1.添加新特征
当特征不足或者现有特征与样本标签的相关性不强时,模型容易出现欠拟合。通
过挖掘组合特征等新的特征,往往能够取得更好的效果。
2.增加模型复杂度
简单模型的学习能力较差,通过增加模型的复杂度可以使模型拥有更强的拟合能
力。例如,在线性模型中添加高次项,以及在神经网络模型中增加网络层数或神
经元个数等。
3.减小正则化强度
正则化是用来防止过拟合的,但当模型出现欠拟合现象时,则需要有针对性地减
小正则化强度。

若有收获,就点个赞吧
0 人点赞
