从Logistic Regression 到 感知机

为什么叫support vector machines
感知机:分离超平面不唯一
支持向量
离超平面最近的样本点,使得判断函数的等号成立。这几点被称为支持向量
几何间隔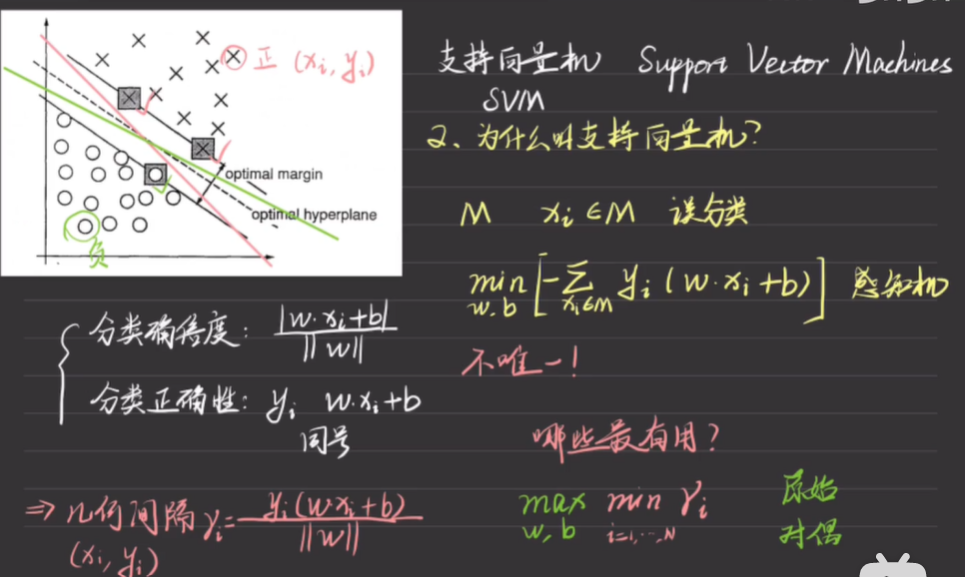
最有用的点是距离分离超平面最近的点
而这些点在高维空间中表示为向量
因此叫支持向量
几何间隔(margin)

目标函数和约束

KKT条件求解

- 对于强对偶性成立的优化问题,其主问题的最优解 x∗ 一定满足给出的 KKT 条 而 KKT 条件中的条件 (1) 就要求最优解 x∗ 能使得拉格朗日函数 L(x,λ, µ)
关于 x 的一阶导数等于 0; 对于任意优化问题,若拉格朗日函数 L(x,λ, µ) 是关于 x 的凸函数,那么此时对 L(x,λ, µ) 关于
x 求导并令导数等于 0 解出来的点一定是最小值点。根据对偶函数的定义可知,将最小值点代回
L(x,λ, µ) 即可得到对偶函数。练习
SMO求解对偶问题
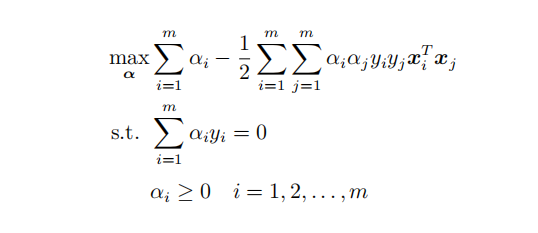
算法过程

如何求解b
支持向量
当
 时,即样本移一定在间隔边界上,其他样本点对w,b的求解无影响
时,即样本移一定在间隔边界上,其他样本点对w,b的求解无影响
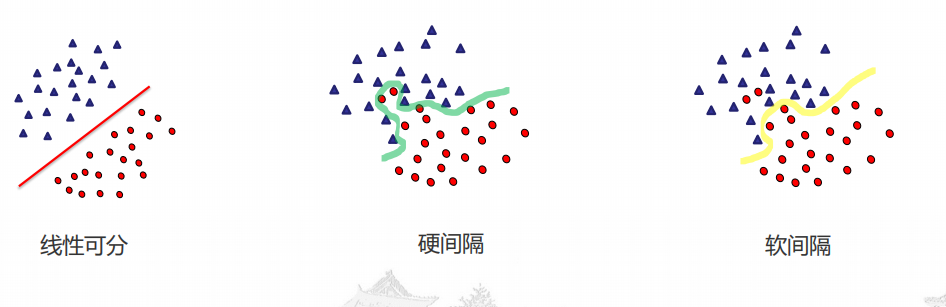
软间隔
为什么提出软间隔
在实际应用中,完全线性可分的样本是很少的,如果遇到了不能够完全线性可分的样本,我们应该怎么办?相比于硬间隔的苛刻条件,我们允许个别样本点出现在间隔带里面

软间隔求解
对比线性可分和软间隔




非线性支持向量机
为什么要提出非线性?
不存在直线将点分开
线性不可分:存在一个曲线可以分开
非线性可分
非线性不可分
原空间
核函数

核函数的作用
低维空间映射到高维空间后维度可能会很大,如果将全部样本的点乘全部计算好,这样的计算量太大了。但如果我们有这样的一核函数  ,
,  与
与  在特征空间的内积等于它们在原始样本空间中通过函数
在特征空间的内积等于它们在原始样本空间中通过函数  计算的结果
计算的结果
可见核函数的引入一方面减少了我们计算量,另一方面也减少了我们存储数据的内存使用量
常用核函数
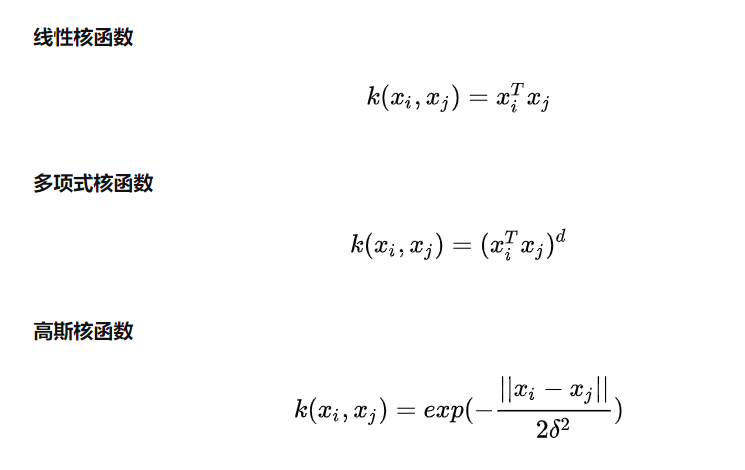
引入核函数后的对偶问题

核技巧
学习是隐式地在特征空间中学习,不需要显示地定义特征空间和映射函数。
正定核
什么是正定核
对于任意的样本点, 对应的Gram 矩阵半正定
对应的Gram 矩阵半正定

如何判断半正定?用来准备求解优化问题
- 特征根大于等于0
- 所有主子行列式大于等于0

欧式空间

Hilbert
支持向量机的优缺点
优点
- 有严格的数学理论支持,可解释性强,不依靠统计方法,从而简化了通常的分类和回归问题;
- 能找出对任务至关重要的关键样本(即:支持向量);
- 采用核技巧之后,可以处理非线性分类/回归任务;
最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”
缺点
训练时间长。当采用 SMO 算法时,由于每次都需要挑选一对参数,因此时间复杂度为
 ,其中 N 为训练样本的数量;
,其中 N 为训练样本的数量;- 当采用核技巧时,如果需要存储核矩阵,则空间复杂度为
 ;
; - 模型预测时,预测时间与支持向量的个数成正比。当支持向量的数量较大时,预测计算复杂度较高。
因此支持向量机目前只适合小批量样本的任务,无法适应百万甚至上亿样本的任务

若有收获,就点个赞吧
0 人点赞
