判别模型和生成模型
监督学习模型可分为判别模型和生成模型
判别模型
- 由数据直接学习决策函数
#card=math&code=Y%20%3D%20f%28X%29&id=sXqeb)或者条件概率分布
#card=math&code=P%28Y%7CX%29&id=US8PK)的模型,即判别模型
- 基本思想是在有限的样本条件下建立判别函数,不考虑样本的产生模型,直接研究预测模型
- 即:直接估计
#card=math&code=f%28X%29&id=U0R17)的值即为使
- 如:线性回归、逻辑回归、感知机、决策树、支持向量机
生成模型
- 由训练数据学习联合概率分布
#card=math&code=P%28X%2CY%29&id=SaqPt),然后求得后验概率分布
- 即:估计
#card=math&code=P%28X%7CY%29&id=UfPxZ)然后推导
- 如:朴素贝叶斯、HMM
过拟合和欠拟合
过拟合
- 如果一味追求提高对训练数据的预测能力,所选模型的复杂度往往会比真模型更高。这种现象称为过拟合。
- 过拟合是指学习时选择的模型所包含的参数过多,以至于出现这一模型对已知数据预测的很好,但对未知数据预测的很差的现象。
欠拟合
- 训练误差和验证误差都很严重,但它们之间仅有一点点差距
- 如果模型不能降低训练误差, 这可能意味着模型过于简单(即表达能力不足),无法捕获试图学习的模式。
- 由于我们的训练和验证误差之间的泛化误差很小,我们有理由相信可以用一个更复杂的模型降低训练误差。
详见
过拟合与欠拟合
监督学习和无监督学习
监督学习
是指从标注数据中学习预测模型的机器学习问题,监督学习的本质是学习输入到输出的映射的统计规律。
无监督学习
是从无标注的数据中学习数据的统计规律或者说内在结构的机器学习。主要包括聚类、降维、概率统计。无监督学习可以用于数据分析或者监督学习的前处理。
数据增广
- 主要用于增加训练数据集,让数据集尽可能多样化,使得训练的模型有更强的泛化能力。
- 如:数据不平衡时对数量较少类别的样本进行过采样。
正则化
- 是模型选择的典型方法
- 是结构风险最小化策略的实现,是在经验风险上加一个正则化项(或罚项)。
- 正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值越大。
- 正则化的作用是选择经验风险与模型复杂度同时较小的模型。
SVM(支持向量机)
- 是一种二分类模型。
- 基本模型:定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。
- 支持向量机还包括核技巧,这使它称为实质上的非线性分类器。
- 学习策略:间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
- 学习算法:求解凸二次规划的最优化算法。
核函数
- 核函数应用于SVM,基本思想就是通过一个非线性变换将输入空间对应于一个特征空间,使得样本在特征空间中线性可分(支持向量机)。这样,分类问题的学习任务就可以通过在特征空间中求解线性支持向量机完成。
- 核函数想法:在学习和预测中只定义核函数
#card=math&code=K%28x%2Cz%29&id=kbPee),而不显式地定义映射函数
。
优化问题求解过程
1.最终目标:
- 分离超平面:
- 分类决策函数:
%20%3D%20sign(w%5E*%20%5Ccdot%20x%20%2B%20b)#card=math&code=f%28x%29%20%3D%20sign%28w%5E%2A%20%5Ccdot%20x%20%2B%20b%29&id=Tv8vR)
2.凸优化问题的目标函数:
- 目标函数:
#card=math&code=with%20%5C%20%5Cgamma_i%20%3D%20y_i%20%28%5Cfrac%20%7Bw%7D%20%7B%7C%7Cw%7C%7C%7D%20%5Ccdot%20x_i%20%2B%20%5Cfrac%20%7Bb%7D%20%7B%7C%7Cw%7C%7C%7D%29&id=TT9g4)
3.间隔最大化(有约束的优化问题)
%20%5Cgeq%20%5Cgamma%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN#card=math&code=s.t.%20%5Cquad%20y_i%28%5Cfrac%20%7Bw%7D%20%7B%7C%7Cw%7C%7C%7D%20%5Ccdot%20x_i%20%2B%20%5Cfrac%20%7Bb%7D%20%7B%7C%7Cw%7C%7C%7D%29%20%5Cgeq%20%5Cgamma%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN&id=cPSeO)
用函数间隔表示:
%20%5Cgeq%20%5Chat%20%5Cgamma%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN#card=math&code=s.t.%20%5Cquad%20y_i%28w%20%5Ccdot%20x_i%20%2B%20b%29%20%5Cgeq%20%5Chat%20%5Cgamma%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN&id=jzpbV)
令 ,且
 ,得到等价问题:
,得到等价问题:
%20-%201%20%5Cgeq%200%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN#card=math&code=s.t.%20%5Cquad%20y_i%28w%20%5Ccdot%20x_i%20%2B%20b%29%20-%201%20%5Cgeq%200%20%2C%20%5Cquad%20i%3D1%2C2%2C…%2CN&id=ofRUZ)
4. 原问题的对偶问题
构建拉格朗日函数
%20%3D%20%5Cfrac%201%202%20%7C%7Cw%7C%7C%5E2%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calpha_i%20y_i%20(w%20%5Ccdot%20x_i%20%2B%20b)%20%2B%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calphai#card=math&code=L%28w%2Cb%2C%5Calpha%29%20%3D%20%5Cfrac%201%202%20%7C%7Cw%7C%7C%5E2%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calphai%20y_i%20%28w%20%5Ccdot%20x_i%20%2B%20b%29%20%2B%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calpha_i&id=E6Ohq)
其中
此时,原问题的对偶问题为:
#card=math&code=%5Cunderset%20%7B%5Calpha%7D%20%7Bmax%7D%20%5C%20%5Cunderset%20%7Bw%2Cb%7D%20%7Bmin%7D%20%5C%20L%28w%2Cb%2C%5Calpha%29&id=rmD44)
- 求解
#card=math&code=%5Cunderset%20%7Bw%2Cb%7D%20%7Bmin%7D%20%5C%20L%28w%2Cb%2C%5Calpha%29&id=MXMpg) :
分别对求偏导数并令其等于0,得:
%20%3D%20w%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calpha_i%20y_i%20x_i%20%3D%200#card=math&code=%5Cnabla_w%20L%28w%2Cb%2C%5Calpha%29%20%3D%20w%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calphai%20y_i%20x_i%20%3D%200&id=N2SKf)
%20%3D%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calphai%20y_i%20%3D%200#card=math&code=%5Cnabla_b%20L%28w%2Cb%2C%5Calpha%29%20%3D%20-%20%5Csum%5Climits%7Bi%3D1%7D%5EN%20%5Calphai%20y_i%20%3D%200&id=woUfA)
代入拉格朗日函数得: - 求
的极大,将其转换成求极小问题,得:


SMO算法
详情
支持向量机
决策树的构建过程
输入:训练集 ,属性集合
,属性集合
输出:决策树 T
T
- 如果所有D属于一类
 ,返回单节点子树
,返回单节点子树
- 如果属性集合
 为空,以
为空,以 实例最多的一类
实例最多的一类 为子节点标记,返回单节点子树
为子节点标记,返回单节点子树
- 计算所有属性的信息增益,选择信息增益最大的属性

- 对
 的所有取值
的所有取值 将
将 划分成若干子集
划分成若干子集
- 对于第i个子节点,以
 为训练集,
为训练集, 为属性集合递归调用1-3
为属性集合递归调用1-3
- 对
评价指标
- 准确率:在类别平衡时可以客观地度量模型的性能,但在
类别不平衡时,需要引入新的度量指标来评价模型的性能 - 召回率:全部真阳里能成功召回多少
- 精准率:全部预测阳性里,猜对了多少
- F1:
,同时结合了召回率和精准率的综合性评价指标
注:召回率、精准率和F1指标只针对二分类。多分类时,采取One-vs-Rest策略,一类视为阳性,其余视为阴性。
- 混淆矩阵:越集中在对角线表示性能越好
- ROC曲线(受试者工作特征曲线):假阳率(所有真阴样本里,被预测成阳性的比例,越低越好)和真阳率(在所有真阳里,被正确预测成阳性的比例,即召回率,越高越好),ROC曲线越靠近左上角表示模型性能越好
- PR(Precision-Recall)曲线:(y-x),越靠近右上角表示性能越好。
详见
评价方法
激活函数的表达形式
- sigmoid
- Tanh
- ReLU
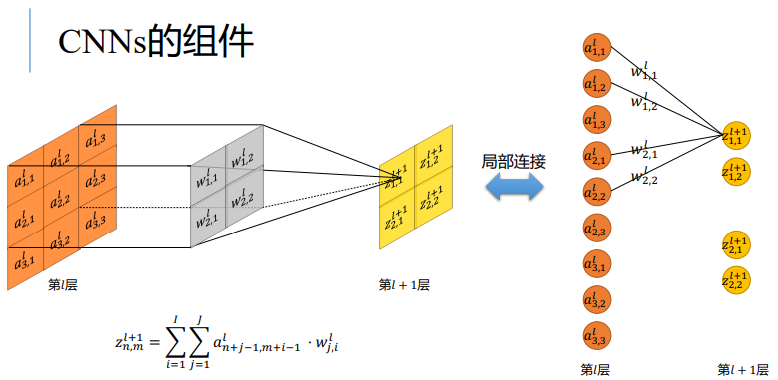
卷积
- 卷积核w沿着输入a的宽和高的方向进行滑动
- 输出z由w和a对位元素相乘并求和得到
- 假设卷积核w的大小是
 ,输出z的大小是
,输出z的大小是

如果把二维或者三维的图片输入拉成一维的话,
- 对位元素相乘求和等价于全连接中的局部连接
- 每次运算共享卷积核(相同的参数)
所以卷积操作中的参数量等于卷积核的大小,远远小于全连接中的参数量
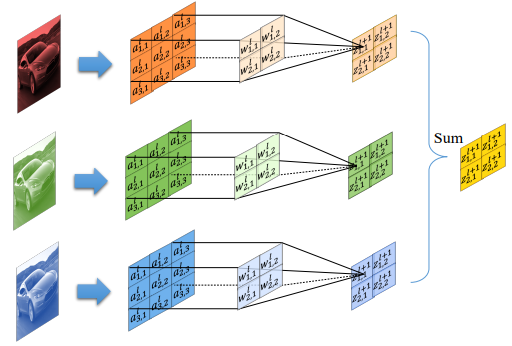
当图片是多通道的输入时:
- 分别对R,G,B通道进行卷积运算
- 对每个卷积运算的输出求和,得到最终输出
如何获取多通道的输出:
- 使用多套卷积核对输入进行卷积
- 堆叠每个卷积的输出,其中输出的通道数等于卷积核的数目
- 步长:控制卷积核的移动步幅
- 边缘补充(如0),从而保持输出大小与输入大小一致
- 池化:在不引入可学习参数w的前提下,高效地对输入进行下采样,降低输入的维度
- 最大值池化
- 均值池化
随机梯度下降算法
- 准备训练数据集

- 随机初始化神经网络各层参数
 ,设置学习率
,设置学习率
- 随机选择b个样本(一个batch),计算并积累各样本对各层参数的梯度

- 更新参数:

- 继续第3步,直到模型收敛
注:重点!反向传播算法求 。
。

- 定义敏感系数

- 链式法则:

 由前向计算可以求得,此时关键为求
由前向计算可以求得,此时关键为求 ,即重点!如何求各层神经元的敏感系数
,即重点!如何求各层神经元的敏感系数
假设损失函数
- 最后一层神经远的敏感系数

- 隐藏层神经元的敏感系数



结果
- 标量形式

 **即第
**即第 层的
层的 的权重和再乘以激活函数的导数
的权重和再乘以激活函数的导数
- 向量形式


 ,其中
,其中  是按元素乘
是按元素乘
梯度消失问题
有些激活函数如sigmoid,其导数在(0, 1)之间,因此在反向传播过程中多个(0, 1)的数字相乘可能会导致梯度消失。
对于激活函数的选择:
 ,线性激活函数,得到的是线性模型,但是模型的拟合能力弱
,线性激活函数,得到的是线性模型,但是模型的拟合能力弱 ,非线性激活函数,模型拟合能力强,但是梯度消失/爆炸,训练困难
,非线性激活函数,模型拟合能力强,但是梯度消失/爆炸,训练困难
所以激活函数 ReLU  是比较好的选择
是比较好的选择
从模型结构的角度:
- 模型深度并非越大越好
- 结构改进,如深度残差神经网络模型:

详见
解决梯度问题
RNN的梯度消失问题

若有收获,就点个赞吧
0 人点赞
