隐状态:
 存储了到时间步
存储了到时间步 的序列信息
的序列信息 表示当前的输入,有递推关系
表示当前的输入,有递推关系
循环神经网络是有隐状态的神经网络
无隐状态的神经网络
对于一个单隐藏层的的多层感知机 表示隐藏层激活函数
表示隐藏层激活函数
给定一个小批量样本 ,
, 为批量大小,
为批量大小, 为一个样本的维度,
为一个样本的维度,
隐藏层输出 ,
,

隐藏层权重参数为 ,
, ,
, 为隐藏层的神经元数目
为隐藏层的神经元数目
接下来,将隐藏层变量作用到输出层,得到
输出层的权重参数为

有隐状态的循环神经网络
 h
h
假设在在时间步t有小批量输入
 代表t时间步的隐变量,与多层感知机不同的是,保存了前一个时间步的隐变量
代表t时间步的隐变量,与多层感知机不同的是,保存了前一个时间步的隐变量 ,并引入更新参数
,并引入更新参数 来描述当前时间步中如何使用该隐变量
来描述当前时间步中如何使用该隐变量
当前隐藏变量的值由当前输入和上一个时间步的隐变量同时确定,于是:
隐状态使用的定义与前一个时间步中使用的定义相同, 因此上式 (8.4.5)的计算是循环的,基于循环计算的隐状态神经网络被命名为 循环神经网络
对于输出层,在时间步t下:
输出层的权重参数
 不随时间变化,换句话说循环神经网络总是使用这些参数
不随时间变化,换句话说循环神经网络总是使用这些参数
梯度剪裁
迭代计算这T个时间步上的梯度,反向传播会产生 的矩阵乘法链,导致数值不稳定
的矩阵乘法链,导致数值不稳定
如果我们进假设目标函数表现良好, 即函数在常数下是利普希茨连续 ,即是:
,即是: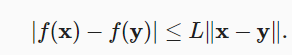
并假设:通过 更新参数,则
更新参数,则
这意味着我们不会观察到超过 的变化。这样的坏处是限制了取得进展的速度,好处是它限制了事情变糟的程度,尤其当我们朝着错误的方向前进时。
的变化。这样的坏处是限制了取得进展的速度,好处是它限制了事情变糟的程度,尤其当我们朝着错误的方向前进时。
那么如何解决梯度爆炸:
可以通过降低η的学习率来解决这个问题。
但是如果我们很少得到大的梯度呢? 在这种情况下,这种做法似乎毫无道理。


 进行投影即乘以一个小于1的系数, 并且更新后的梯度完全与的原始方向对齐。
进行投影即乘以一个小于1的系数, 并且更新后的梯度完全与的原始方向对齐。
RNN梯度消失问题
RNN中的总的梯度不会消失。即便梯度越传越弱,那也只是远距离的梯度消失,由于近距离的梯度不会消失,所有梯度之和并不会消失。RNN 所谓梯度消失的真正含义是,梯度被近距离梯度主导,导致模型难以学到远距离的依赖关系
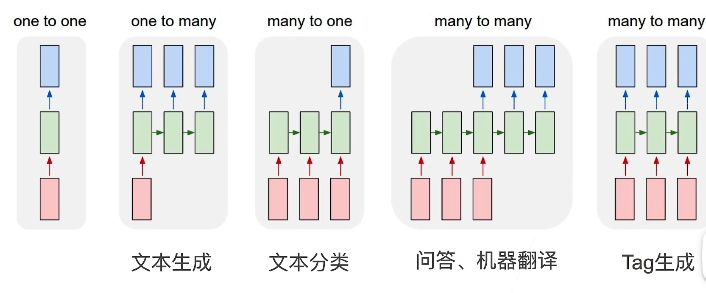
RNN应用

若有收获,就点个赞吧
0 人点赞
