
算法流程
- 计算测试样本与训练集中每个样本的距离
2. 按照距离的远近排序
3. 选取与当前测试样本最近的k个训练样本,作为该测试样本的邻居
4. 统计这k个样本的类别频次
5. k个样本里频次最高的类别,即为测试样本的类别
K-D-Tree划分
KD树
对于二维数据(x, y),如何构建查找树?KD树(k维空间)构造流程:
- 选择一个坐标轴(假设为
 ),以及在该坐标轴上的切分点,由此可将超矩形区域划分为
),以及在该坐标轴上的切分点,由此可将超矩形区域划分为
左/右子区域。其中左子区域k1坐标轴均小于该切分点,右子区域均大于该切分点
2. 在左/右子区域中,对除开 的其余维度执行以上步骤,直至所有节点已全部划分完毕
的其余维度执行以上步骤,直至所有节点已全部划分完毕
切分轴的选择(方向):选择方差最大的维度
切分点的选择(位置):在以上维度中,选择中点构造过程




切分轴轮转

KD树搜索
在KD树中寻找目标点x的最近邻

例子
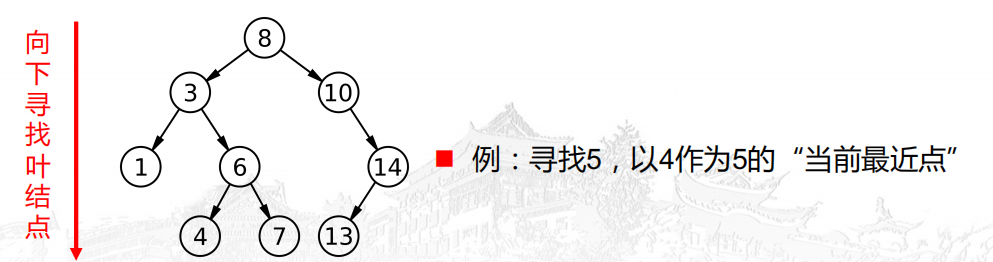
递归向上回退



算法执行实例


作业

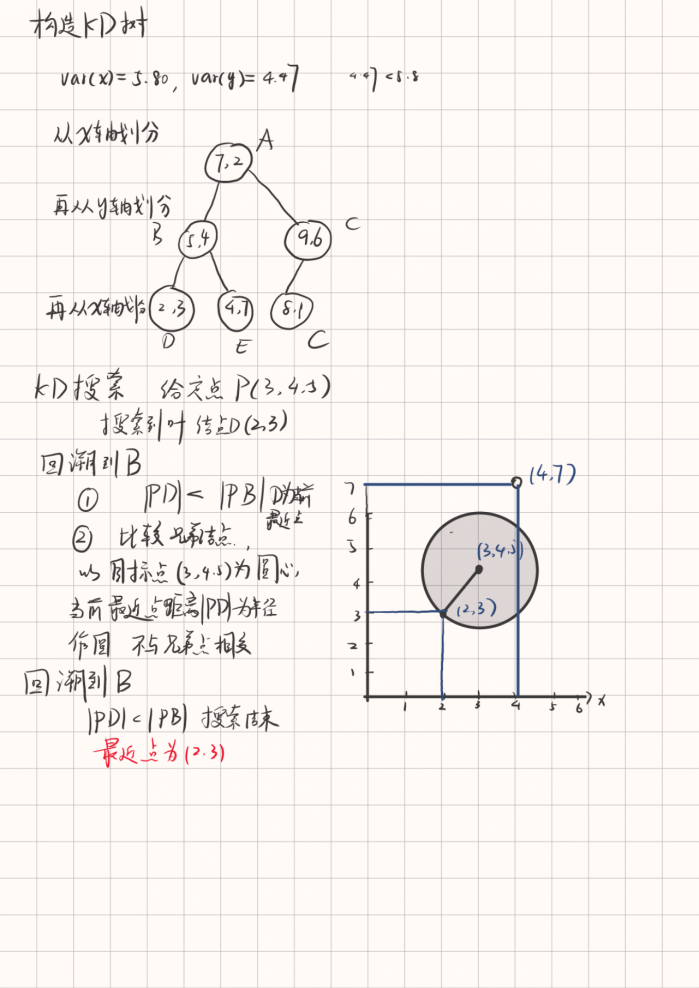
首先划分kd tree,找到二分查找到叶节点
向上回溯,比较兄弟节点
例子:鸢尾花数据集
例子:鸢尾花数据集
鸢尾花数据集:其中一类与另两类线性可分, 而另两类直接不线性可分。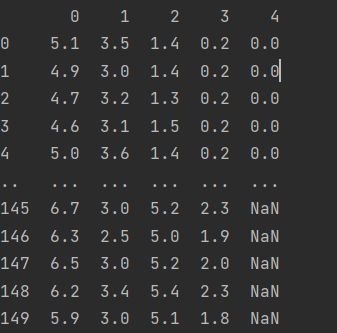
iris = datasets.load_iris()# 导入数据和标签iris_X = iris.data # 属性iris_y = iris.target # 对应类别
X_train, X_test, y_train, y_test = train_test_split(iris_X, iris_y, test_size=0.2,random_state=0xAAAA) # 测试比例 ,随机种子
# 设置knn分类器knn = KNeighborsClassifier()
# 进行训练knn.fit(X_train, y_train)
print(y_test) # 真实值print(knn.predict(X_test)) # 预测值print(knn.score(X_test,y_test))

若有收获,就点个赞吧
0 人点赞
