1. sigmoid函数
曾经最主流的激活函数,现在很少用了,函数公式和图像如下图所示: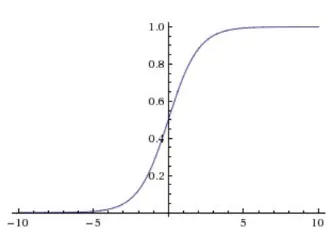
缺点
- Sigmoid容易饱和,当输入非常大或者非常小的时候,函数曲线非常平坦,梯度就接近于0,从图中可以看出梯度的趋势。而反向传播中,我们需要使用sigmoid的导数来更新权重,如果导数都基本为0,会导致权重基本没什么更新,我们就无法递归地学习到输入数据了,这种现象也可以叫做梯度弥散。
- Sigmoid 的输出不是0均值的,这是我们不希望的,因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正,那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。
- 计算量大,sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
优点:
将所有数据映射成了(0,1)之间的数,很好的表达神经元的激活与未激活的状态,适合二分类。2. tanh函数
tanh是在sigmoid基础上的改进,将压缩范围调整为(-1,1)。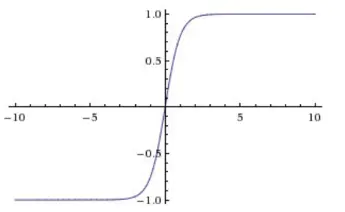
优点:
它是0均值的,解决了上述Sigmoid缺点中的第二个,所以实际中tanh会比sigmoid更常用。缺点
- 它还是存在梯度弥散的问题。
- 计算量大,函数要进行指数运算,这个对于计算机来说是比较慢的。
3. relu函数
relu函数是目前主流的激活函数,它的公式很简单,输入小于0的时候为0,大于0的时候是本身。
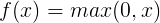
优点

若有收获,就点个赞吧
0 人点赞
