def calc_ent(datasets):"""计算熵"""data_length = len(datasets)label_count = {}for i in range(data_length):label = datasets[i][-1]if label not in label_count:label_count[label] = 0label_count[label] += 1ent = -sum([(p / data_length) * log(p / data_length, 2)for p in label_count.values()])return entdef cond_ent(datasets, axis=0):"""条件熵"""data_length = len(datasets)feature_sets = {}for i in range(data_length):feature = datasets[i][axis]if feature not in feature_sets:feature_sets[feature] = []feature_sets[feature].append(datasets[i])cond_ent = sum([(len(p) / data_length) * calc_ent(p) for p in feature_sets.values()])return cond_entdef info_gain_train(datasets):count = len(datasets[0]) - 1ent = calc_ent(datasets)# ent = entropy(datasets)best_feature = []for c in range(count):c_info_gain = info_gain(ent, cond_ent(datasets, axis=c))best_feature.append((c, c_info_gain))print('特征({}) - info_gain - {:.3f}'.format(labels[c], c_info_gain))# 比较大小best_ = max(best_feature, key=lambda x: x[-1])return '特征({})的信息增益最大,选择为根节点特征'.format(labels[best_[0]])
print("-----------------------------------------")print(info_gain_train(np.array(datasets)))print("-----------------------------------------")print("-----------------------------------------")print(info_gain_train(np.array(datasets)))print("-----------------------------------------")
每次分类的信息增益
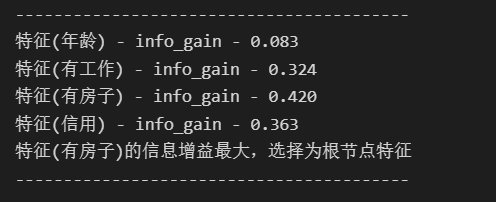
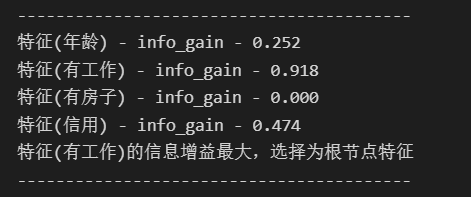
分类结果如下
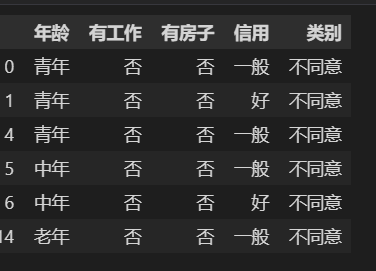

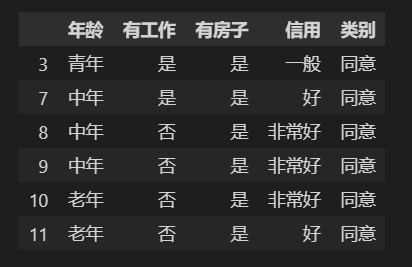
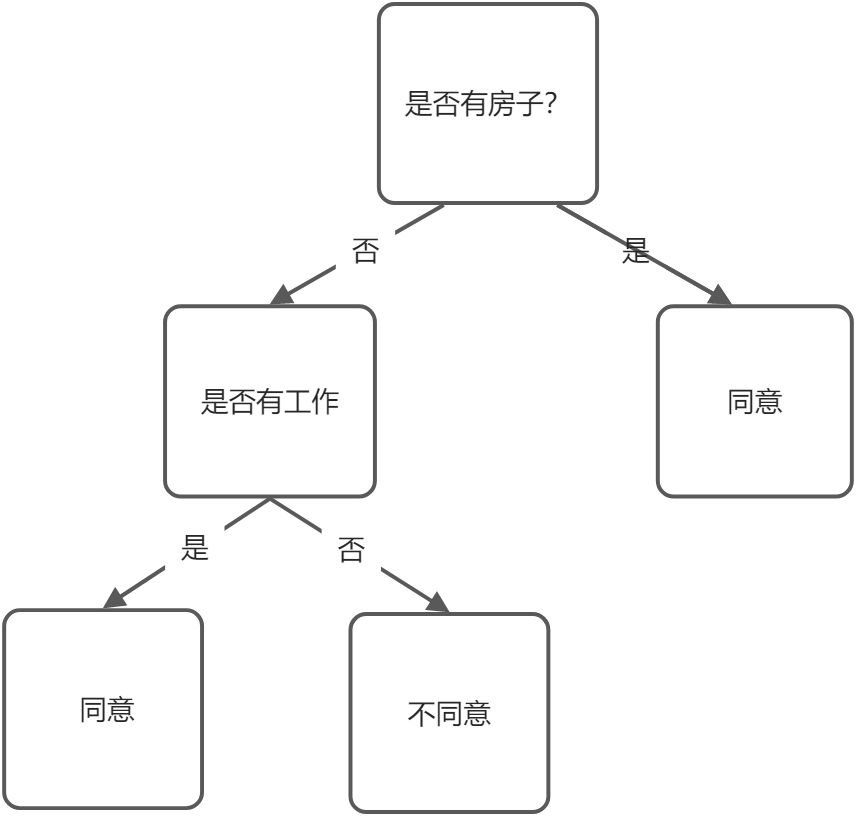
决策树如下


若有收获,就点个赞吧
0 人点赞
