- 参考链接
- 缩放
裁剪">
裁剪- 旋转和翻转
- 图像变换
- torchvision.transforms.Pad
torchvision.transforms.ColorJitter">
torchvision.transforms.ColorJitter- transforms.Grayscale/RandomGrayscale">
 transforms.Grayscale/RandomGrayscale
transforms.Grayscale/RandomGrayscale
transforms.RandomAffine">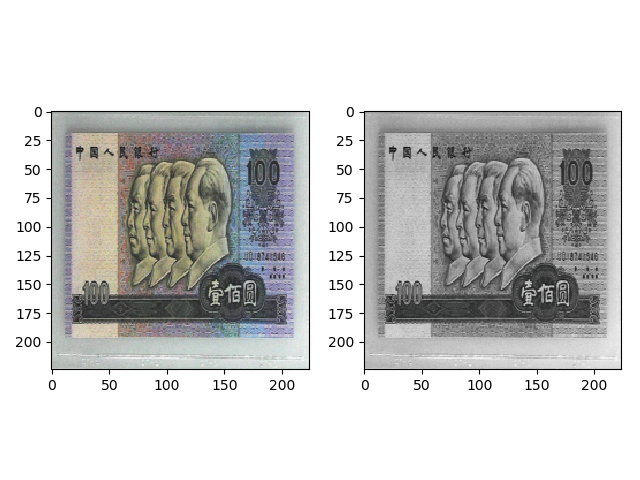
transforms.RandomAffine
transforms.RandomErasing">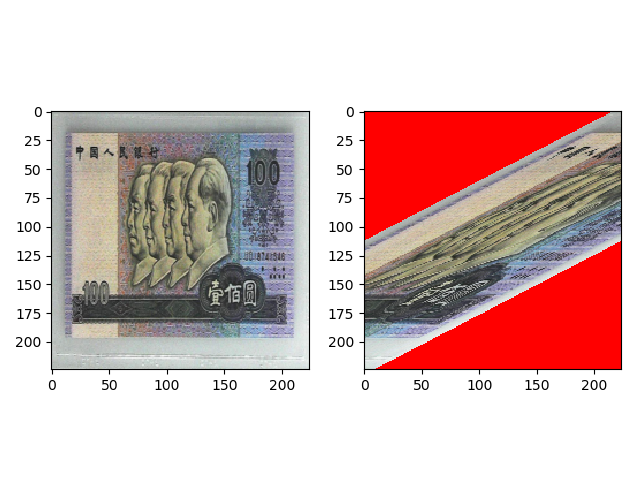
transforms.RandomErasing- transforms.Lambda">
 transforms.Lambda
transforms.Lambda
- transforms 的操作
- 自定义 transforms
- 完整代码
- 数据增强实战应用
参考链接
https://www.cnblogs.com/zhangxiann/p/13570884.html
缩放
transforms.Resize
torchvision.transforms.Resize((224, 224)) # 把图片缩放到 224x224
把图片缩放到 (224, 224) 大小 ,缩放会改变图片原始的宽高比,下面的所有操作都是基于缩放之后的图片进行的,然后再进行其他 transform 操作。
原图如下:
经过缩放之后,图片如下:
裁剪
transforms.CenterCrop
torchvision.transforms.CenterCrop(196) # 从图像中心裁剪图片

如果裁剪的 size 比原图大,那么会填充值为 0 的像素。
transforms.CenterCrop(512) # 效果如下

transforms.RandomCrop
torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode='constant')
功能:从图片中随机裁剪出尺寸为 size 的图片,如果有 padding,那么先进行 padding,再随机裁剪 size 大小的图片。
- size: 要裁剪的大小
- padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
- pad_if_need: 当图片小于设置的 size,是否填充
- padding_mode:
- constant: 像素值由 fill 设定
- edge: 像素值由图像边缘像素设定
- reflect: 镜像填充,最后一个像素不镜像。([1,2,3,4] -> [3,2,1,2,3,4,3,2])
- symmetric: 镜像填充,最后一个像素也镜像。([1,2,3,4] -> [2,1,1,2,3,4,4,4,3])
- fill: 当 padding_mode 为 constant 时,设置填充的像素值
transforms.RandomCrop(224, padding=16) 的效果如下,这里的 padding 为 16,所以会先在 4 边进行 16 的 padding,默认填充 0,然后随机裁剪出 (224,224) 大小的图片,这里裁剪了左上角的区域。
transforms.RandomCrop(224, padding=(16, 64)) 的效果如下,首先在左右进行 16 的 padding,上下进行 64 的 padding,然后随机裁剪出 (224,224) 大小的图片。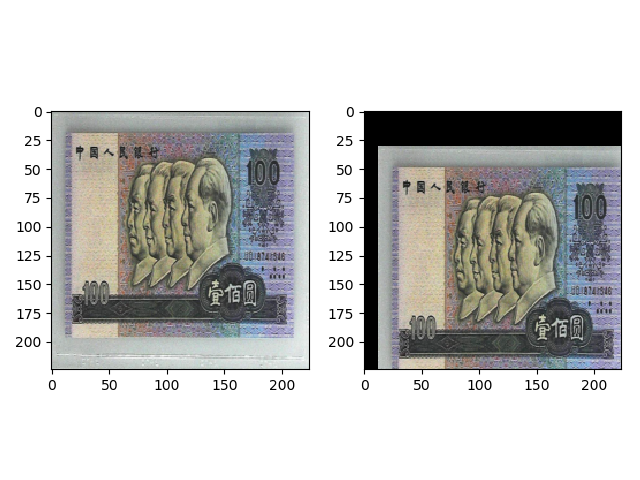
transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)) 的效果如下,首先在上下左右进行 16 的 padding,填充值为 (255, 0, 0),然后随机裁剪出 (224,224) 大小的图片。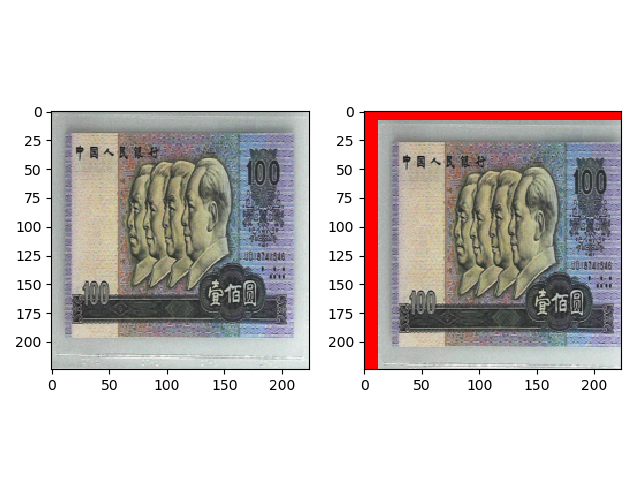
transforms.RandomCrop(512, pad_if_needed=True) 的效果如下,设置pad_if_needed=True,图片小于设置的 size,用 (0,0,0) 填充。
transforms.RandomCrop(224, padding=64, padding_mode=’edge’) 的效果如下,首先在上下左右进行 64 的 padding,使用边缘像素填充,然后随机裁剪出 (224,224) 大小的图片。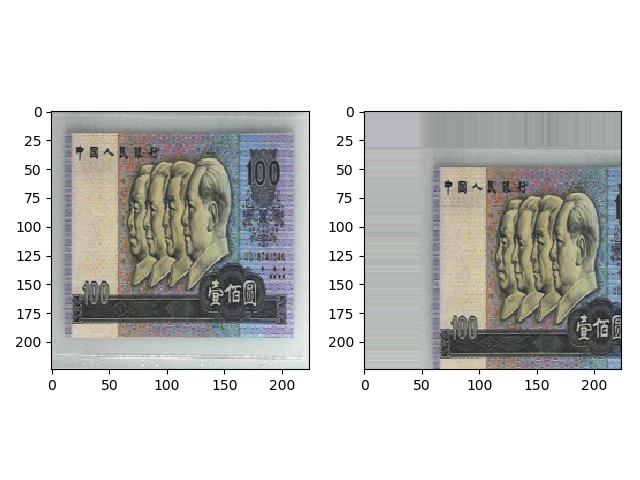
transforms.RandomCrop(224, padding=64, padding_mode=’reflect’) 的效果如下,首先在上下左右进行 64 的 padding,使用镜像填充,然后随机裁剪出 (224,224) 大小的图片。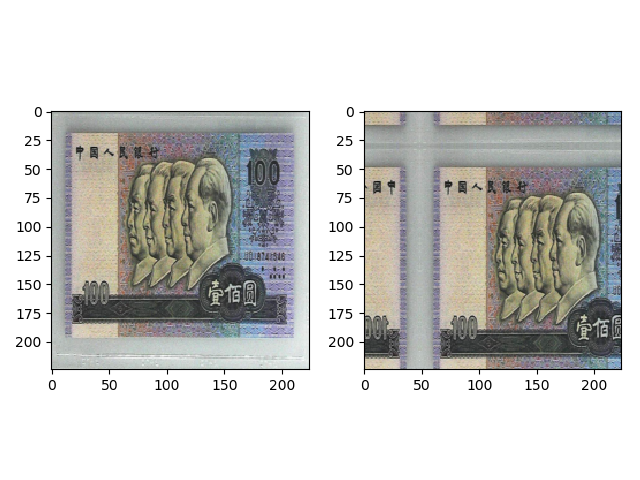
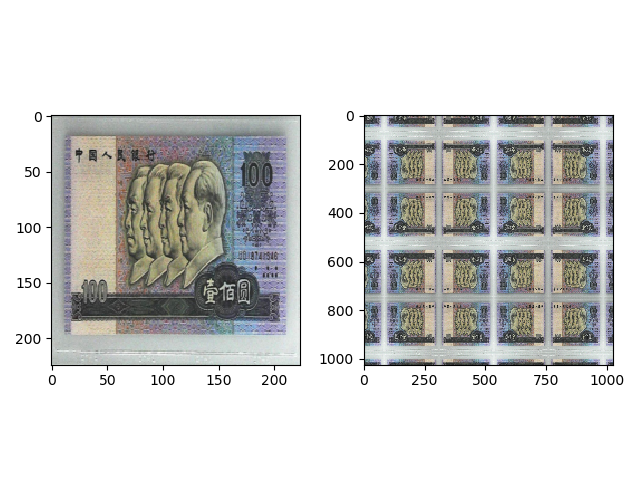
transforms.RandomCrop(1024, padding=1024, padding_mode=’symmetric’) 的效果如下,首先在上下左右进行 1024 的 padding,使用镜像填充,然后随机裁剪出 (1024, 1024) 大小的图片。
 transforms.RandomResizedCrop
transforms.RandomResizedCrop
torchvision.transforms.RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
功能:随机大小、随机宽高比裁剪图片。首先根据 scale 的比例裁剪原图,然后根据 ratio 的长宽比再裁剪,最后使用插值法把图片变换为 size 大小。
- size: 裁剪的图片尺寸
- scale: 随机缩放面积比例,默认随机选取 (0.08, 1) 之间的一个数
- ratio: 随机长宽比,默认随机选取 ($\displaystyle\frac{3}{4}$, $\displaystyle\frac{4}{3}$ ) 之间的一个数。因为超过这个比例会有明显的失真
- interpolation: 当裁剪出来的图片小于 size 时,就要使用插值方法 resize
- PIL.Image.NEAREST
- PIL.Image.BILINEAR
- PIL.Image.BICUBIC
transforms.RandomResizedCrop(size=224, scale=(0.08, 1)) 的效果如下,首先随机选择 (0.08, 1) 中 的一个比例缩放,然后随机裁剪出 (224, 224) 大小的图片。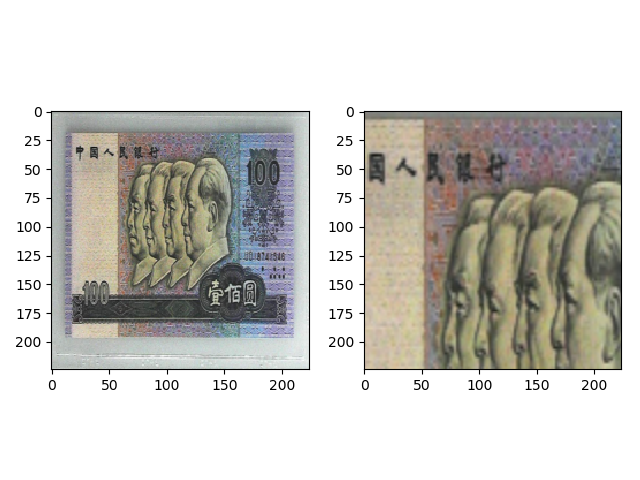
transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)) 的效果如下,首先缩放 0.5 倍,然后随机裁剪出 (224, 224) 大小的图片。
 transforms.FiveCrop/TenCrop
transforms.FiveCrop/TenCrop
torchvision.transforms.FiveCrop(size)torchvision.transforms.TenCrop(size, vertical_flip=False)
功能:FiveCrop 在图像的上下左右以及中心裁剪出尺寸为 size 的 5 张图片。TenCrop 对这 5 张图片进行水平或者垂直镜像获得 10 张图片。
- size: 最后裁剪的图片尺寸
- vertical_flip: 是否垂直翻转
由于这两个方法返回的是 tuple,每个元素表示一个图片,我们还需要把这个 tuple 转换为一张图片的tensor。代码如下:
transforms.FiveCrop(112)transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
并且把transforms.Compose中最后两行注释:
# transforms.ToTensor()# transforms.Normalize(norm_mean, norm_std)
- transforms.toTensor() 接收的参数是 Image,由于上面已经进行了 toTensor()。因此注释这一行。
- transforms.Normalize() 方法接收的是 3 维的 tensor (在 _is_tensor_image()方法 里检查是否满足这一条件,不满足则报错),而经过transforms.FiveCrop返回的是 4 维张量,因此注释这一行。
最后的 tensor 形状是 [ncrops, c, h, w],图片可视化的代码也需要做修改:
## 展示 FiveCrop 和 TenCrop 的图片ncrops, c, h, w = img_tensor.shapecolumns=2 # 两列rows= math.ceil(ncrops/2) # 计算多少行# 把每个 tensor ([c,h,w]) 转换为 imagefor i in range(ncrops):img = transform_invert(img_tensor[i], train_transform)plt.subplot(rows, columns, i+1)plt.imshow(img) plt.show()
5 张图片分别是左上角,右上角,左下角,右下角,中心。图片如下: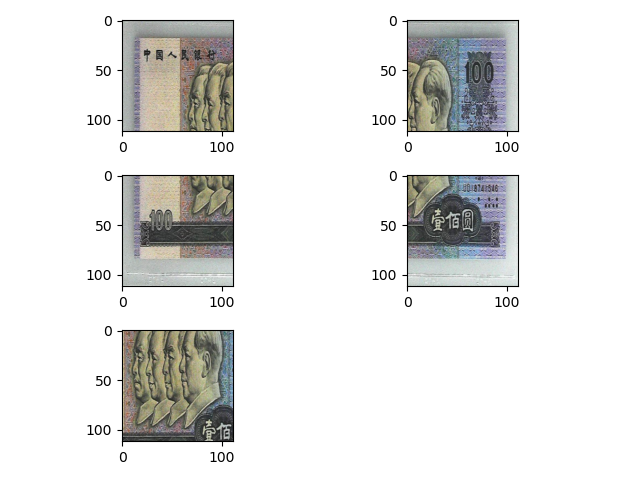
transforms.TenCrop 的操作同理,只是返回的是 10 张图片,在 transforms.FiveCrop 的基础上多了镜像。
旋转和翻转
transforms.RandomHorizontalFlip/RandomVerticalFlip
功能:根据概率,在水平或者垂直方向翻转图片
- p: 翻转概率
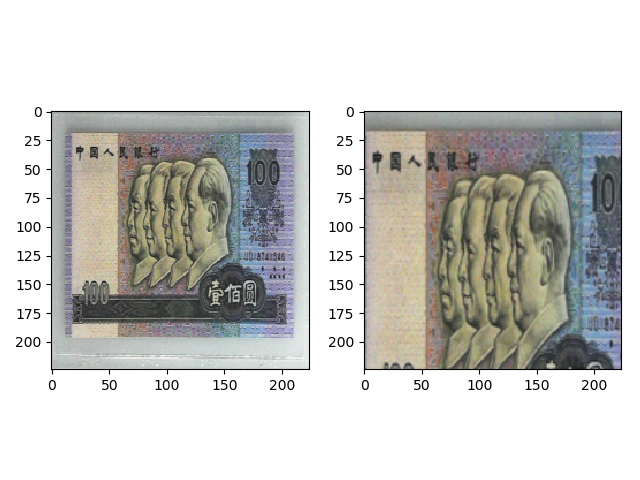
transforms.RandomHorizontalFlip(p=0.5),那么一半的图片会被水平翻转。
transforms.RandomHorizontalFlip(p=1),那么所有图片会被水平翻转。水平翻转的效果如下。
transforms.RandomVerticalFlip(p=1) 垂直翻转的效果如下。
transforms.RandomRotation
torchvision.transforms.RandomRotation(degrees, resample=False, expand=False, center=None, fill=None)
功能:随机旋转图片
- degree: 旋转角度
- 当为 a 时,在 (-a, a) 之间随机选择旋转角度
- 当为 (a, b) 时,在 (a, b) 之间随机选择旋转角度
- resample: 重采样方法
- expand: 是否扩大矩形框,以保持原图信息。根据中心旋转点计算扩大后的图片。如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。
- center: 旋转点设置,是坐标,默认中心旋转。如设置左上角为:(0, 0)
transforms.RandomRotation(90) 的效果如下,shape 为 (224, 224),原来图片的 4 个角有部分信息丢失。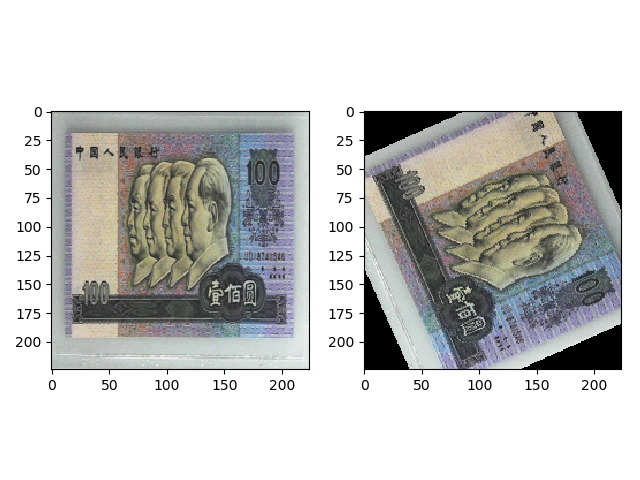
transforms.RandomRotation((90), expand=True) 的效果如下,shape 大于 (224, 224),具体的 shape 的大小会根据旋转角度和原图大小计算。原来图片的 4 个角都保留了下来。
但是需要注意的是,如果设置 expand=True, batch size 大于 1,那么在一个 Batch 中,每张图片的 shape 都不一样了,会报错 Sizes of tensors must match except in dimension 0。所以如果 expand=True,那么还需要进行 resize 操作。
transforms.RandomRotation(30, center=(0, 0)) 设置旋转点为左上角,效果如下。
transforms.RandomRotation(30, center=(0, 0), expand=True) 的效果如下,如果旋转点不是中心,即使设置 expand = True,还是会有部分信息丢失。
图像变换
torchvision.transforms.Pad
torchvision.transforms.Pad(padding, fill=0, padding_mode='constant')
功能:对图像边缘进行填充
- padding: 设置填充大小
- 当为 a 时,上下左右均填充 a 个像素
- 当为 (a, b) 时,左右填充 a 个像素,上下填充 b 个像素
- 当为 (a, b, c, d) 时,左上右下分别填充 a,b,c,d
- padding_mode: 填充模式,有 4 种模式,constant、edge、reflect、symmetric
- fill: 当 padding_mode 为 constant 时,设置填充的像素值,(R, G, B) 或者 (Gray)
transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode=’constant’) 的效果如下,上下左右的 padding 为 16,填充为 (255, 0, 0)。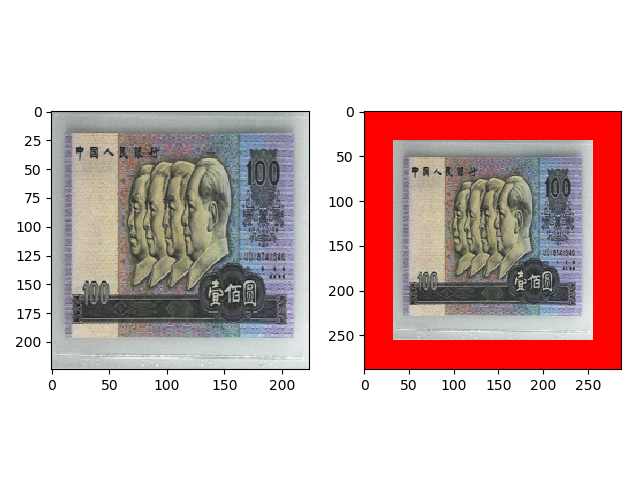
transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode=’constant’) 的效果如下,左右的 padding 为 8,上下的 padding 为 64,填充为 (255, 0, 0)。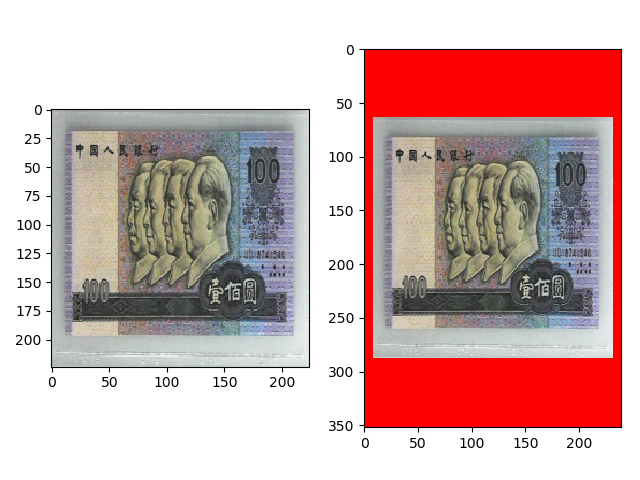
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=’constant’) 的效果如下,左、上、右、下的 padding 分别为 8、16、32、64,填充为 (255, 0, 0)。
transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode=’symmetric’) 的效果如下,镜像填充。这时padding_mode属性不是constant, fill 属性不再生效。
torchvision.transforms.ColorJitter
torchvision.transforms.ColorJitter(brightness=0, contrast=0, saturation=0, hue=0)
功能:调整亮度、对比度、饱和度、色相。在照片的拍照过程中,可能会由于设备、光线问题,造成色彩上的偏差,因此需要调整这些属性,抵消这些因素带来的扰动。
- brightness: 亮度调整因子
- contrast: 对比度参数
- saturation: 饱和度参数
- brightness、contrast、saturation 参数:当为 a 时,从 [max(0, 1-a), 1+a] 中随机选择;当为 (a, b) 时,从 [a, b] 中选择。
- hue: 色相参数
- 当为 a 时,从 [-a, a] 中选择参数。其中 $0\le a \le 0.5$。
- 当为 (a, b) 时,从 [a, b] 中选择参数。其中 $0 \le a \le b \le 0.5$。
transforms.ColorJitter(brightness=0.5) 的效果如下。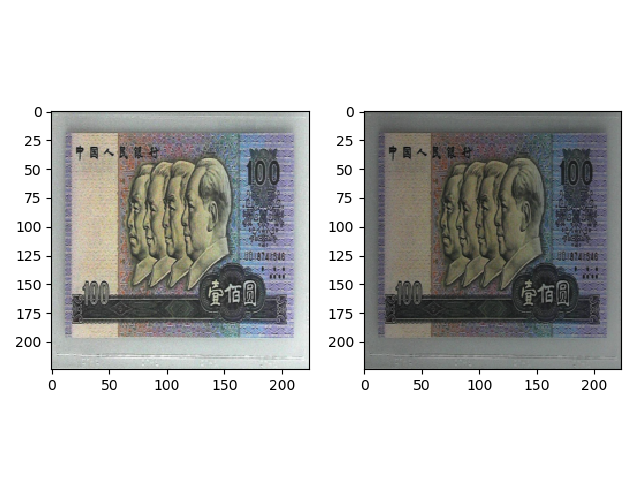
transforms.ColorJitter(contrast=0.5) 的效果如下。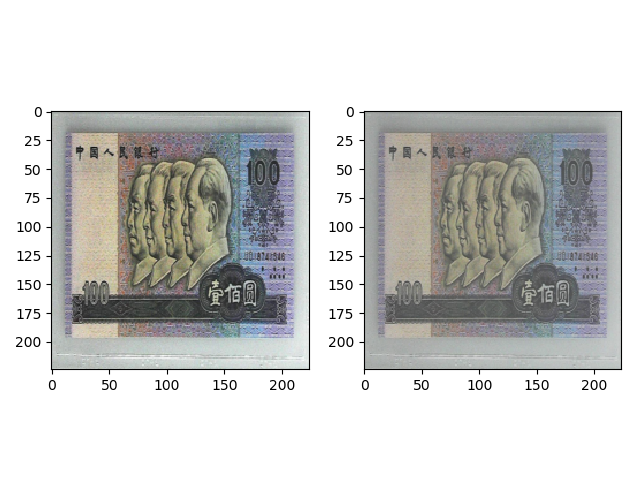
transforms.ColorJitter(saturation=0.5) 的效果如下。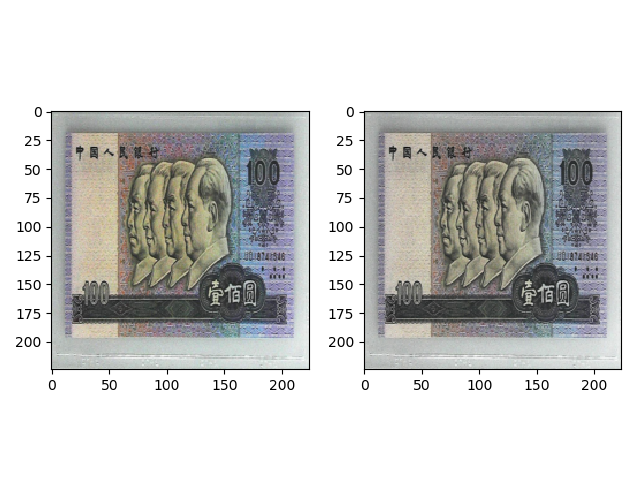
transforms.ColorJitter(hue=0.3) 的效果如下。
transforms.Grayscale/RandomGrayscale
torchvision.transforms.Grayscale(num_output_channels=1)
功能:将图片转换为灰度图
- num_output_channels: 输出的通道数。只能设置为 1 或者 3 (如果在后面使用了transforms.Normalize,则要设置为 3,因为transforms.Normalize只能接收 3 通道的输入)
torchvision.transforms.RandomGrayscale(p=0.1, num_output_channels=1)
- p: 概率值,图像被转换为灰度图的概率
- num_output_channels: 输出的通道数。只能设置为 1 或者 3
功能:根据一定概率将图片转换为灰度图
transforms.Grayscale(num_output_channels=3) 的效果如下。
transforms.RandomAffine
torchvision.transforms.RandomAffine(degrees, translate=None, scale=None, shear=None, resample=False, fillcolor=0)
功能:对图像进行仿射变换,仿射变换是 2 维的线性变换,由 5 种基本操作组成,分别是旋转、平移、缩放、错切和翻转。
- degree: 旋转角度设置
- translate: 平移区间设置,如 (a, b),a 设置宽 (width),b 设置高 (height)。图像在宽维度平移的区间为 $- img_width \times a < dx < img_width \times a$,高同理
- scale: 缩放比例,以面积为单位
- fillcolor: 填充颜色设置
- shear: 错切角度设置,有水平错切和垂直错切
- 若为 a,则仅在 x 轴错切,在 (-a, a) 之间随机选择错切角度
- 若为 (a, b),x 轴在 (-a, a) 之间随机选择错切角度,y 轴在 (-b, b) 之间随机选择错切角度
- 若为 (a, b, c, d),x 轴在 (a, b) 之间随机选择错切角度,y 轴在 (c, d) 之间随机选择错切角度
- resample: 重采样方式,有 NEAREST、BILINEAR、BICUBIC。
transforms.RandomAffine(degrees=30) 的效果如下,中心旋转 30 度。
transforms.RandomAffine(degrees=0, translate=(0.2, 0.2) 的效果如下,设置水平和垂直的平移比例都为 0.2。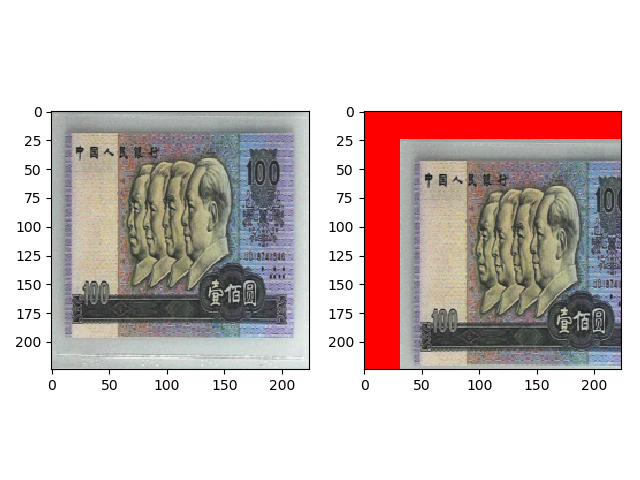
transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)) 的效果如下,设置宽和高的缩放比例都为 0.7。
transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)) 的效果如下,在 x 轴上不错切,在 y 轴上随机选择 (0, 45) 之间的角度进行错切。
transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)) 的效果如下。在 x 轴上随机选择 (-90, 90) 之间的角度进行错切,在 y 轴上不错切。
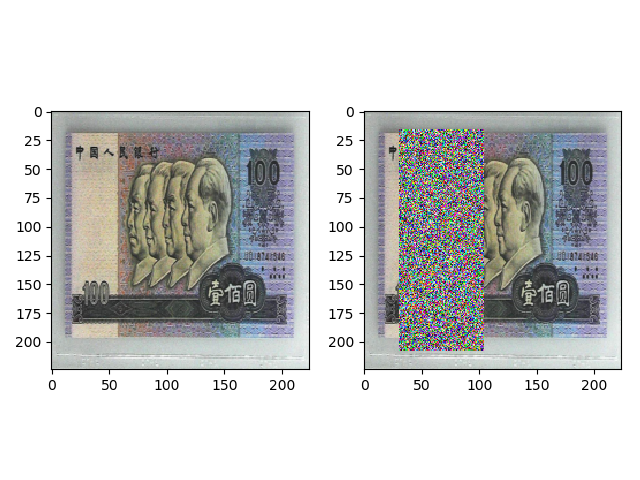
transforms.RandomErasing
torchvision.transforms.RandomErasing(p=0.5, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=0, inplace=False)
功能:对图像进行随机遮挡。这个操作接收的输入是 tensor。因此在此之前需要先执行transforms.ToTensor()。同时注释掉后面的transforms.ToTensor()。
- p: 概率值,执行该操作的概率
- scale: 遮挡区域的面积。如(a, b),则会随机选择 (a, b) 中的一个遮挡比例
- ratio: 遮挡区域长宽比。如(a, b),则会随机选择 (a, b) 中的一个长宽比
- value: 设置遮挡区域的像素值。(R, G, B) 或者 Gray,或者任意字符串。由于之前执行了transforms.ToTensor(),像素值归一化到了 0~1 之间,因此这里设置的 (R, G, B) 要除以 255
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)) 的效果如下,从scale=(0.02, 0.33)中随机选择遮挡面积的比例,从ratio=(0.3, 3.3)中随机选择一个遮挡区域的长宽比,value 设置的 RGB 值需要归一化到 0~1 之间。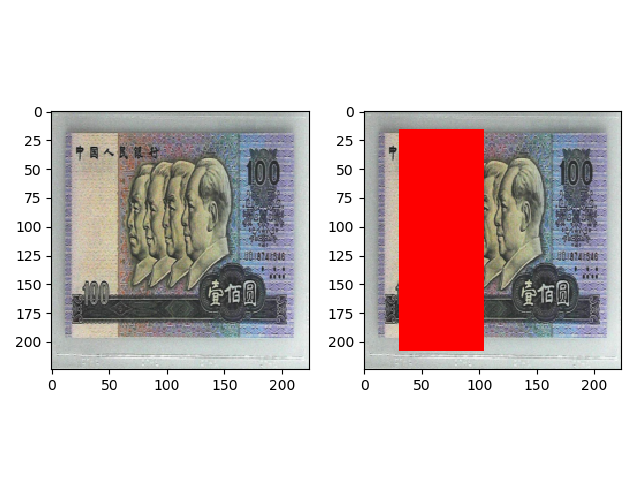
transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=’fads43’) 的效果如下,value 设置任意的字符串,就会使用随机的值填充遮挡区域。
transforms.Lambda
自定义 transform 方法。在上面的FiveCrop中就用到了transforms.Lambda。
transforms.FiveCrop(112, vertical_flip=False), transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops]))
transforms.FiveCrop 返回的是长度为 5 的 tuple,因此需要使用transforms.Lambda 把 tuple 转换为 4D 的 tensor。
transforms 的操作
torchvision.transforms.RandomChoice
torchvision.transforms.RandomChoice([transforms1, transforms2, transforms3])
transforms.RandomApply
torchvision.transforms.RandomApply([transforms1, transforms2, transforms3], p=0.5)
功能:根据概率执行一组 transforms 操作,要么全部执行,要么全部不执行。
transforms.RandomOrder
transforms.RandomOrder([transforms1, transforms2, transforms3])
自定义 transforms
自定义 transforms 有两个要素:仅接受一个参数,返回一个参数;注意上下游的输入与输出,上一个 transform 的输出是下一个 transform 的输入。
我们这里通过自定义 transforms 实现椒盐噪声。椒盐噪声又称为脉冲噪声,是一种随机出现的白点或者黑点,白点称为盐噪声,黑点称为椒噪声。信噪比 (Signal-Noise Rate,SNR) 是衡量噪声的比例,图像中正常像素占全部像素的占比。
我们定义一个AddPepperNoise类,作为添加椒盐噪声的 transform。在构造函数中传入信噪比和概率,在call()函数中执行具体的逻辑,返回的是 image。
import numpy as npimport randomfrom PIL import Image# 自定义添加椒盐噪声的 transformclass AddPepperNoise(object):"""增加椒盐噪声Args:snr (float): Signal Noise Ratep (float): 概率值,依概率执行该操作"""def __init__(self, snr, p=0.9):assert isinstance(snr, float) or (isinstance(p, float))self.snr = snrself.p = p# transform 会调用该方法def __call__(self, img):"""Args:img (PIL Image): PIL ImageReturns:PIL Image: PIL image."""# 如果随机概率小于 seld.p,则执行 transformif random.uniform(0, 1) < self.p:# 把 image 转为 arrayimg_ = np.array(img).copy()# 获得 shapeh, w, c = img_.shape# 信噪比signal_pct = self.snr# 椒盐噪声的比例 = 1 -信噪比noise_pct = (1 - self.snr)# 选择的值为 (0, 1, 2),每个取值的概率分别为 [signal_pct, noise_pct/2., noise_pct/2.]# 椒噪声和盐噪声分别占 noise_pct 的一半# 1 为盐噪声,2 为 椒噪声mask = np.random.choice((0, 1, 2), size=(h, w, 1), p=[signal_pct, noise_pct/2., noise_pct/2.])mask = np.repeat(mask, c, axis=2)img_[mask == 1] = 255 # 盐噪声img_[mask == 2] = 0 # 椒噪声# 再转换为 imagereturn Image.fromarray(img_.astype('uint8')).convert('RGB')# 如果随机概率大于 seld.p,则直接返回原图else:return img
AddPepperNoise(0.9, p=0.5) 的效果如下。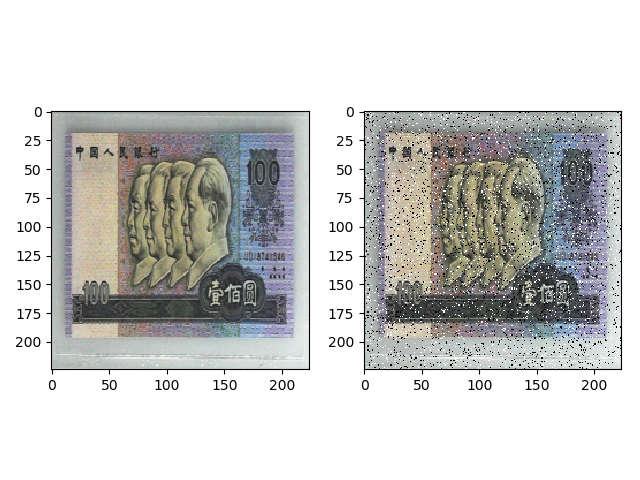
完整代码
# -*- coding: utf-8 -*-import osimport numpy as npimport torchimport randomimport mathimport torchvision.transforms as transformsfrom PIL import Imagefrom matplotlib import pyplot as pltfrom enviroments import rmb_split_dirfrom lesson2.transforms.addPepperNoise import AddPepperNoisedef set_seed(seed=1):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)set_seed(1) # 设置随机种子# 参数设置MAX_EPOCH = 10BATCH_SIZE = 1LR = 0.01log_interval = 10val_interval = 1rmb_label = {"1": 0, "100": 1}#对 tensor 进行反标准化操作,并且把 tensor 转换为 image,方便可视化。def transform_invert(img_, transform_train):"""将data 进行反transfrom操作:param img_: tensor:param transform_train: torchvision.transforms:return: PIL image"""# 如果有标准化操作if 'Normalize' in str(transform_train):# 取出标准化的 transformnorm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))# 取出均值mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)# 取出标准差std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)# 乘以标准差,加上均值img_.mul_(std[:, None, None]).add_(mean[:, None, None])# 把 C*H*W 变为 H*W*Cimg_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C# 把 0~1 的值变为 0~255img_ = np.array(img_) * 255# 如果是 RGB 图if img_.shape[2] == 3:img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')# 如果是灰度图elif img_.shape[2] == 1:img_ = Image.fromarray(img_.astype('uint8').squeeze())else:raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )return img_norm_mean = [0.485, 0.456, 0.406]norm_std = [0.229, 0.224, 0.225]train_transform = transforms.Compose([# 缩放到 (224, 224) 大小,会拉伸transforms.Resize((224, 224)),# 1 CenterCrop 中心裁剪# transforms.CenterCrop(512), # 512# transforms.CenterCrop(196), # 512# 2 RandomCrop# transforms.RandomCrop(224, padding=16),# transforms.RandomCrop(224, padding=(16, 64)),# transforms.RandomCrop(224, padding=16, fill=(255, 0, 0)),# transforms.RandomCrop(512, pad_if_needed=True), # pad_if_needed=True# transforms.RandomCrop(224, padding=64, padding_mode='edge'),# transforms.RandomCrop(224, padding=64, padding_mode='reflect'),# transforms.RandomCrop(1024, padding=1024, padding_mode='symmetric'),# 3 RandomResizedCrop# transforms.RandomResizedCrop(size=224, scale=(0.08, 1)),# transforms.RandomResizedCrop(size=224, scale=(0.5, 0.5)),# 4 FiveCrop# transforms.FiveCrop(112),# 返回的是 tuple,因此需要转换为 tensor# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),# 5 TenCrop# transforms.TenCrop(112, vertical_flip=False),# transforms.Lambda(lambda crops: torch.stack([(transforms.ToTensor()(crop)) for crop in crops])),# 1 Horizontal Flip# transforms.RandomHorizontalFlip(p=1),# 2 Vertical Flip# transforms.RandomVerticalFlip(p=1),# 3 RandomRotation# transforms.RandomRotation(90),# transforms.RandomRotation((90), expand=True),# transforms.RandomRotation(30, center=(0, 0)),# transforms.RandomRotation(30, center=(0, 0), expand=True), # expand only for center rotation# 1 Pad# transforms.Pad(padding=32, fill=(255, 0, 0), padding_mode='constant'),# transforms.Pad(padding=(8, 64), fill=(255, 0, 0), padding_mode='constant'),# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='constant'),# transforms.Pad(padding=(8, 16, 32, 64), fill=(255, 0, 0), padding_mode='symmetric'),# 2 ColorJitter# transforms.ColorJitter(brightness=0.5),# transforms.ColorJitter(contrast=0.5),# transforms.ColorJitter(saturation=0.5),# transforms.ColorJitter(hue=0.3),# 3 Grayscale# transforms.Grayscale(num_output_channels=3),# 4 Affine# transforms.RandomAffine(degrees=30),# transforms.RandomAffine(degrees=0, translate=(0.2, 0.2), fillcolor=(255, 0, 0)),# transforms.RandomAffine(degrees=0, scale=(0.7, 0.7)),# transforms.RandomAffine(degrees=0, shear=(0, 0, 0, 45)),# transforms.RandomAffine(degrees=0, shear=90, fillcolor=(255, 0, 0)),# 5 Erasing# transforms.ToTensor(),# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value=(254/255, 0, 0)),# transforms.RandomErasing(p=1, scale=(0.02, 0.33), ratio=(0.3, 3.3), value='fads43'),# 1 RandomChoice# transforms.RandomChoice([transforms.RandomVerticalFlip(p=1), transforms.RandomHorizontalFlip(p=1)]),# 2 RandomApply# transforms.RandomApply([transforms.RandomAffine(degrees=0, shear=45, fillcolor=(255, 0, 0)),# transforms.Grayscale(num_output_channels=3)], p=0.5),# 3 RandomOrder# transforms.RandomOrder([transforms.RandomRotation(15),# transforms.Pad(padding=32),# transforms.RandomAffine(degrees=0, translate=(0.01, 0.1), scale=(0.9, 1.1))]),AddPepperNoise(0.9, p=0.5),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),])path_img=os.path.join(rmb_split_dir, "train", "100","0A4DSPGE.jpg")img = Image.open(path_img).convert('RGB') # 0~255img=transforms.Resize((224, 224))(img)img_tensor = train_transform(img)## 展示单张图片# 这里把转换后的 tensor 再转换为图片convert_img=transform_invert(img_tensor, train_transform)plt.subplot(1, 2, 1)plt.imshow(img)plt.subplot(1, 2, 2)plt.imshow(convert_img)plt.show()plt.pause(0.5)plt.close()## 展示 FiveCrop 和 TenCrop 的图片# ncrops, c, h, w = img_tensor.shape# columns=2 # 两列# rows= math.ceil(ncrops/2) # 计算多少行# # 把每个 tensor ([c,h,w]) 转换为 image# for i in range(ncrops):# img = transform_invert(img_tensor[i], train_transform)# plt.subplot(rows, columns, i+1)# plt.imshow(img)# plt.show()
数据增强实战应用
数据增强的原则是需要我们观察训练集和测试集之间的差异,然后应用有效的数增强,使得训练集和测试集更加接近。比如下图中的数据集,训练集中的猫是居中,而测试集中的猫可能是偏左、偏上等位置的。这时可以使用平移来做训练集数据增强。
在下图的数据集中,训练集中白猫比较多,测试集中黑猫比较多,这时可以对训练集的数做色彩方面的增强。而猫的姿态各异,所以可从仿射变换上做数据增强。还可以采用遮挡、填充等数据增强。
我们在上个人民币二分类实验中,使用的是第四套人民币。但是在这个数据集上训练的模型不能够很准确地对第五套人民币进行分类。下图是 3 种图片的对比,第四套 1 元人民币和第五套 100 元人民币都比较偏红,因此容易把第五套 100 元人民币分类成 1 元人民币。
而实际测试中,训练完的模型在第五套 100 元人民币上错误率高,第五套 100 元人民币分类成 1 元人民币。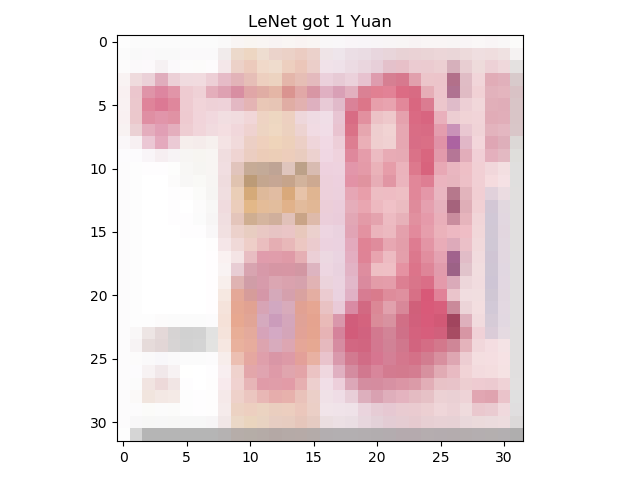
在 transforms中添加了灰度变换transforms.RandomGrayscale(p=0.9),把所有图片变灰,减少整体颜色带来的偏差,准确率有所上升。

若有收获,就点个赞吧
0 人点赞
