参考文档
https://blog.csdn.net/siyue0211/article/details/80522595
https://www.twblogs.net/a/5f030bc29644181341a1c343/?lang=zh-cn
一对一 (One vs One)
给定数据集D=(x1,y1),(x2,y2)…,(xm,ym), yi=[C1,C2,…,CN]。OvO将这N个类两两配对,从而产生N(N-1)/2个二分类任务。于是我们会得到N(N-1)/2个分类结果,最终的结果可通过投票产生:把被预测得最多的类别作为最终分类结果。
一对多 (One vs Rect)
一对多是将一个类的样例作为正例,其它类的样例作为反例来训练N个分类器。在测试时若仅有一个分类器预测为正类,则对应类别标记为最终分类结果。如有多个分类器预测为正例,则以经过逻辑回归的数据作为衡量标准,哪个大选择哪个。
比较 OvO 和 OvR
容易看出,OvR只需训练N个分类器,而OvO则需要训练N(N-1)/2个分类器,因此,OvO的存储开销和测试时间开销通常比OvR更大。但在训练时,OvR的每个分类器均使用全部的训练样例,而OvO的每个分类器仅用到两个类的样例,因此,在类别很多的时候,OvO的训练时间开销通常比OvR更小。至于预测性能,则取决于具体的数据分布,在多数情况下两者差不多。
多对多 (Many vs Many)
多对多是每次将若干类作为正例,若干其他类作为负例。MvM的正反例构造有特殊的设计,不能随意选取。我们这里介绍一种常用的MvM技术:纠错输出码(EOOC)。
- 编码:对N个类做M次划分,每次划分将一部分类别划分为正例,一部分划分为反例,从而形成一个二分类的训练集:这样共有M个训练集,则可训练出M个分类器。
- 解码:M个分类器分别对测试样本进行预测,这些预测样本组成一个编码。将这个编码与每个类各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
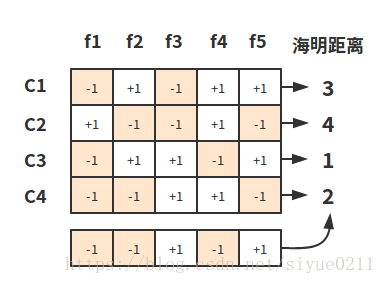
在分类器f2中,将C1和C3类的样例作为正例,C2和C4作为负例。在解码阶段各分类的测试结果联合起来称为测试示例的编码,测试示例是图中最下面一行。该编码与各类所对应的编码进行比较,将距离最小的编码所对应的类别作为预测结果。例如如果基于海明距离,预测结果是C3。
为什么要用纠错输出码呢?因为在测试阶段,ECOC编码对分类器的错误有一定的容忍和修正能力。例如上图中对测试示例正确的预测编码是(-1,1,1,-1,1),但在预测时f2出错从而导致了错误的编码(-1, -1, 1, -1,1)。但是基于这个编码仍然能产生正确的最终分类结果C3。

若有收获,就点个赞吧
0 人点赞
