
1. PyTorch实现里面都设置 bias=False ?
因为使用了Batch Normalization,而其对隐藏层  有去均值的操作,所以这里的常数项
有去均值的操作,所以这里的常数项  可以消去,因为Batch Normalization有一个操作
可以消去,因为Batch Normalization有一个操作 ,所以上面
,所以上面 的数值效果是能由
的数值效果是能由 所替代的,因此我们在使用Batch Norm的时候,可以忽略各隐藏层的常数项
所替代的,因此我们在使用Batch Norm的时候,可以忽略各隐藏层的常数项  。这样在使用梯度下降算法时,只用对
。这样在使用梯度下降算法时,只用对  ,
,  和
和  进行迭代更新
进行迭代更新
2. ResNet结构为什么可以解决深度网络退化问题?
因为ResNet更加容易拟合恒等映射,因为ResNet的结构使得网络具有与学习恒等映射的能力,同时也具有学习其他映射的能力。因此ResNet的结构要优于传统的卷积网络(plain networks)结构。
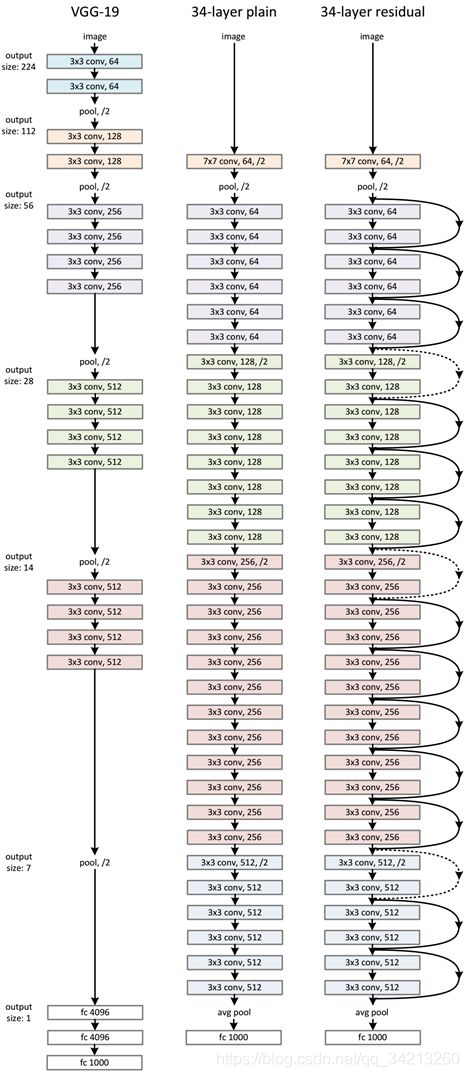
3. ResNet的网络结构
ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元,如下图所示。变化主要体现在ResNet直接使用 stride=2 的卷积做下采样,并且用 global average pool 层替换了全连接层。ResNet的一个重要设计原则是:当feature map大小降低一半时,feature map的数量增加一倍,这保持了网络层的复杂度。从下图中可以看到,ResNet相比普通网络每两层间增加了短路机制,这就形成了残差学习,其中虚线表示feature map数量发生了改变。下图展示的34-layer的ResNet。从最上面的表中可以看到,对于18-layer和34-layer的ResNet,其进行的两层间的残差学习,当网络更深时,其进行的是三层间的残差学习,三层卷积核分别是1x1,3x3和1x1,一个值得注意的是隐含层的feature map数量是比较小的,并且是输出feature map数量的1/4。
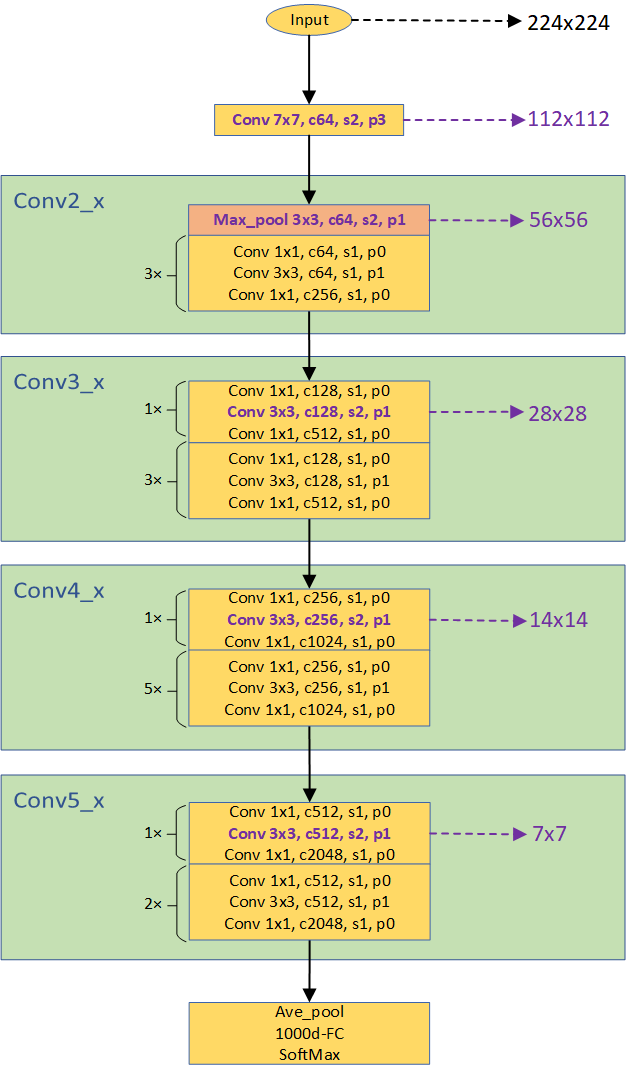
4. ResNet-50 网络结构
参考文档
ResNet 介绍
https://www.cnblogs.com/long5683/p/12957042.html
https://www.bilibili.com/video/av91981420
ResNet 作者现场演讲
https://zhuanlan.zhihu.com/p/54072011
ResNet 论文详解
https://zhuanlan.zhihu.com/p/462190341
ResNet 要解决的是什么问题
https://www.cnblogs.com/shine-lee/p/12363488.html
ResNet 为什么要1*1卷积
https://zhuanlan.zhihu.com/p/364527122
ResNet 的每个block 里,11,33,1*1卷积这样交替堆叠有什么好处和作用?
https://www.zhihu.com/question/384884504
偏执 bias
https://www.cnblogs.com/wanghui-garcia/p/10775860.html
https://blog.csdn.net/qq_22764813/article/details/97940302
ResNet 网络结构
https://zhoujiahuan.github.io/2020/06/11/ResNet-networks/
调参经验
https://www.cnblogs.com/mfryf/p/11393653.html
代码实现
import torch.nn as nnimport torchfrom torch.nn import functional as Fclass ResNetBasicBlock(nn.Module):def __init__(self, in_channels, out_channels, stride):super(ResNetBasicBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)def forward(self, x):output = self.conv1(x)output = F.relu(self.bn1(output))output = self.conv2(output)output = self.bn2(output)return F.relu(x + output)class ResNetDownBlock(nn.Module):def __init__(self, in_channels, out_channels, stride):super(ResNetDownBlock, self).__init__()self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.extra = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),nn.BatchNorm2d(out_channels))def forward(self, x):extra_x = self.extra(x)output = self.conv1(x)output = F.relu(self.bn1(output))output = self.conv2(output)output = self.bn2(output)return F.relu(extra_x + output)class ResNet18(nn.Module):""" ResNet18 """def __init__(self, out_channels):super(ResNet18, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.maxPool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = nn.Sequential(ResNetBasicBlock(64, 64, 1), ResNetBasicBlock(64, 64, 1))self.layer2 = nn.Sequential(ResNetDownBlock(64, 128, [2, 1]), ResNetBasicBlock(128, 128, 1))self.layer3 = nn.Sequential(ResNetDownBlock(128, 256, [2, 1]), ResNetBasicBlock(256, 256, 1))self.layer4 = nn.Sequential(ResNetDownBlock(256, 512, [2, 1]), ResNetBasicBlock(512, 512, 1))self.avgPool = nn.AdaptiveAvgPool2d(output_size=(1, 1))self.fc = nn.Linear(512, out_channels)def forward(self, x):out = self.conv1(x)out = self.bn1(out)out = self.maxPool(F.relu(out))out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.avgPool(out)out = torch.flatten(out, 1)out = self.fc(out)return out
import torch.nn as nnimport torchclass Bottleneck(nn.Module):def __init__(self, in_channels, middle_channels, out_channels, stride):super(Bottleneck, self).__init__()self.bottleneck = nn.Sequential(nn.Conv2d(in_channels, middle_channels, kernel_size=1, stride=1, bias=False),nn.BatchNorm2d(middle_channels),nn.ReLU(),nn.Conv2d(middle_channels, middle_channels, kernel_size=3, stride=stride, padding=1, bias=False),nn.BatchNorm2d(middle_channels),nn.ReLU(),nn.Conv2d(middle_channels, out_channels, kernel_size=1, stride=1, bias=False),nn.BatchNorm2d(out_channels))self.down = Falseif in_channels != out_channels:self.down = Trueself.downSample = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(out_channels))self.relu = nn.ReLU()def forward(self, x):old_x = xoutput = self.bottleneck(x)if self.down:old_x = self.downSample(old_x)output += old_xoutput = self.relu(output)return outputclass ResNet101(nn.Module):""" ResNet101 """def __init__(self, out_channels):super(ResNet101, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.layer1 = self.make_layer(in_channels=64, middle_channels=64, out_channels=256, stride=1, count=3)self.layer2 = self.make_layer(in_channels=256, middle_channels=128, out_channels=512, stride=2, count=4)self.layer3 = self.make_layer(in_channels=512, middle_channels=256, out_channels=1024, stride=2, count=23)self.layer4 = self.make_layer(in_channels=1024, middle_channels=512, out_channels=2048, stride=2, count=3)self.avgPool = nn.AdaptiveAvgPool2d(output_size=(1, 1))self.fc = nn.Linear(2048, out_channels)def make_layer(self, in_channels, middle_channels, out_channels, stride, count):layers = []for i in range(count):if i == 0:layers.append(Bottleneck(in_channels, middle_channels, out_channels, stride))else:layers.append(Bottleneck(out_channels, middle_channels, out_channels, 1))return nn.Sequential(*layers)def forward(self, x):out = self.conv1(x)out = self.layer1(out)out = self.layer2(out)out = self.layer3(out)out = self.layer4(out)out = self.avgPool(out)out = torch.flatten(out, 1)out = self.fc(out)return out

若有收获,就点个赞吧
0 人点赞
