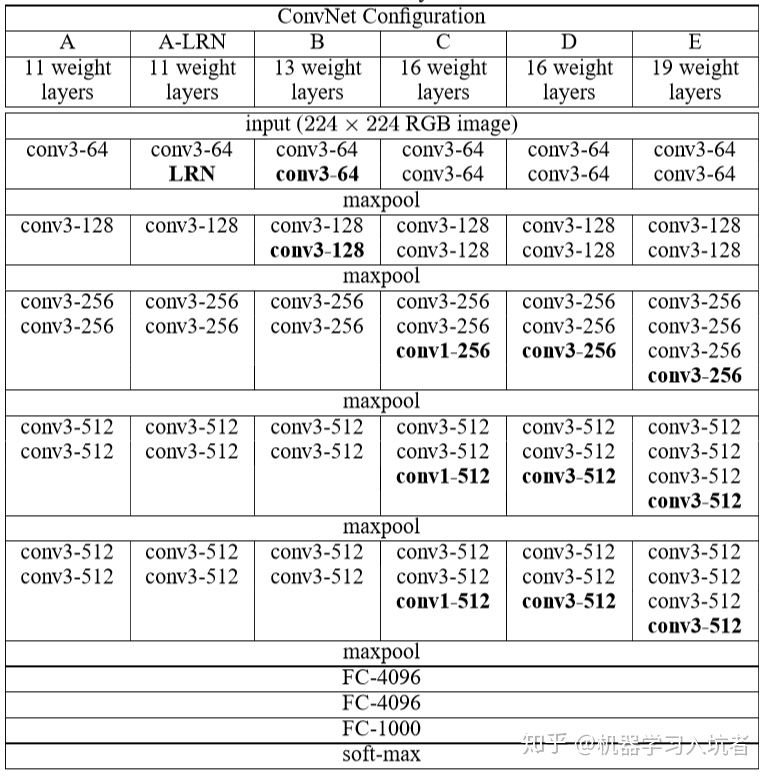
1. 为什么是5个块?
有人猜测是因为输入的宽高是 224224 的,经过5次 maxpool 之后图像宽高变成 77 ,是奇数无法被整除了。
2. 为什么图像分类的输入多是224*224?
一个图像分类模型,在图像中经历了下面的流程从输入image -> 卷积和池化 -> 最后一层的feature map -> 全连接层 -> 损失函数层softmax loss。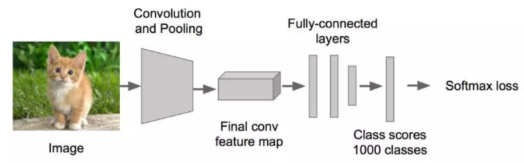
从输入到最后一个卷积特征feature map,就是进行信息抽象的过程,然后就经过全连接层/全局池化层的变换进行分类了,这个feature map的大小,可以是3×3,5×5,7×7等等。
解答1:在这些尺寸中,如果尺寸太小,那么信息就丢失太严重,如果尺寸太大,信息的抽象层次不够高,计算量也更大,所以7*7的大小是一个最好的平衡。
另一方面,图像从大分辨率降低到小分辨率,降低倍数通常是2的指数次方,所以图像的输入一定是72的指数次方。以ImageNet为代表的大多数分类数据集,图像的长宽在300分辨率左右。
解答2:所以要找一个7×2的指数次方,并且在300左右的,其中7×2的4次方=7×16=112,7×2的5次方等于7×32=224,7×2的6次方=448,与300最接近的就是224了。
这就是最重要的原因了,当然了对于实际的项目来说,有的不需要这么大的分辨率,比如手写数字识别MNIST就用3232,有的要更大,比如细粒度分类。
3. VGG16C为什么块最后是1*1的卷积?
使用1×11×1的卷积核,为了添加非线性激活函数的个数,而且不影响卷积层的感受野。
4. AdaptiveAvgPool2d的作用
因为输入图像的尺寸可能不是224224的,所以到最后一个块的时候尺寸不一定是77的,但是第一个线性层必须要求输入维度是固定的,所以可以使用该方法自适应输入的尺寸
5. BatchNorm2d 的作用
批正则化,对输入的批数据进行归一化,映射到均值为 0 ,方差为 1 的正态分布。为了能够使每一批的数据分布相同,同时能够避免梯度消失。
6. model.eval() 和 with torch.no_grad() 的区别
在 model.eval() 模式下,dropout层会让所有的激活单元都通过,而batchnorm层会停止计算和更新mean和var,直接使用在训练阶段已经学出的mean和var值。该模式不会影响各层的gradient计算行为,即gradient计算和存储与training模式一样,只是不进行反传。
而 with torch.no_grad() 则主要是用于停止autograd模块的工作,以起到加速和节省显存的作用,具体行为就是停止gradient计算,从而节省了GPU算力和显存,但是并不会影响dropout和batchnorm层的行为。
7. Dropout只在训练上起作用?
训练时,Dropout会随机丢弃一部分神经元,使其输出为0,那么输出数据的总大小就变小了。这样在测试的时候就会出现问题,由于测试的时候,Dropout不是起作用的,这将导致训练和预测时的数据分布不一样,为了解决这个问题,有两种方法:
- 训练时以比例r随机丢弃一部分神经元,不向后传递它们的信号;预测时向后传递所有神经元的信号,但是将每个神经元上的数值 乘以(1−r)。
- 训练时以比例r随机丢弃一部分神经元,不向后传递它们的信号,但是将那些被保留的神经元上的数值除以 (1−r);预测时向后传递所有神经元的信号,不做任何处理。
8. 数据预处理的时候为什么要做 transforms.Normalize
可能的原因: 数据如果分布在(0,1)之间,可能实际的bias,就是神经网络的输入b会比较大,而模型初始化时b=0的,这样会导致神经网络收敛比较慢,经过Normalize后,可以加快模型的收敛速度。因为对RGB图片而言,数据范围是[0-255]的,需要先经过ToTensor除以255归一化到[0,1]之后,再通过Normalize计算过后,将数据归一化到[-1,1]。9.Dropout2d很少使用?
卷积层一般使用BN来防止过拟合,由于卷积层只有很少的参数,他们本身就不需要多少正则化。更进一步说,特征图编码的是空间的关系,特征图的激活是高度相关的,这也导致了dropout的失效。10.为什么卷积核都是3*3?
VGG的思想是认为深度比宽度更有优势,所以两个 33 的感受野相当于一个 55 的感受野,这样参数会更少,且每个3*3之后会跟一个BN和ReLU,这样可以增加更多的非线性实现代码
```python import torch.nn as nn
class VGG16(nn.Module): “””VGG16”””
def create_conv2d(self, input_channel, output_channel, batch_norm):if batch_norm:return nn.Sequential(nn.Conv2d(in_channels=input_channel, out_channels=output_channel, padding=1, kernel_size=3, stride=1),nn.BatchNorm2d(output_channel),nn.ReLU())else:return nn.Sequential(nn.Conv2d(in_channels=input_channel, out_channels=output_channel, padding=1, kernel_size=3, stride=1),nn.ReLU())def __init__(self, input_channel, output_channel, batch_norm=False):super(VGG16, self).__init__()self.conv = nn.Sequential(# block 1self.create_conv2d(input_channel, 64, batch_norm),self.create_conv2d(64, 64, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 2self.create_conv2d(64, 128, batch_norm),self.create_conv2d(128, 128, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 3self.create_conv2d(128, 256, batch_norm),self.create_conv2d(256, 256, batch_norm),self.create_conv2d(256, 256, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 4self.create_conv2d(256, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 5self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),)self.linear = nn.Sequential(nn.AdaptiveAvgPool2d((7, 7)),nn.Flatten(),nn.Linear(in_features=512 * 7 * 7, out_features=4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(in_features=4096, out_features=4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(in_features=4096, out_features=output_channel))def forward(self, x):output = self.conv(x)output = self.linear(output)return output
```pythonimport torch.nn as nnclass VGG19(nn.Module):"""VGG19"""def create_conv2d(self, input_channel, output_channel, batch_norm):if batch_norm:return nn.Sequential(nn.Conv2d(in_channels=input_channel, out_channels=output_channel, padding=1, kernel_size=3, stride=1),nn.BatchNorm2d(output_channel),nn.ReLU())else:return nn.Sequential(nn.Conv2d(in_channels=input_channel, out_channels=output_channel, padding=1, kernel_size=3, stride=1),nn.ReLU())def __init__(self, input_channel, output_channel, batch_norm=False):super(VGG19, self).__init__()self.conv = nn.Sequential(# block 1self.create_conv2d(input_channel, 64, batch_norm),self.create_conv2d(64, 64, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 2self.create_conv2d(64, 128, batch_norm),self.create_conv2d(128, 128, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 3self.create_conv2d(128, 256, batch_norm),self.create_conv2d(256, 256, batch_norm),self.create_conv2d(256, 256, batch_norm),self.create_conv2d(256, 256, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 4self.create_conv2d(256, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),# block 5self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),self.create_conv2d(512, 512, batch_norm),nn.MaxPool2d(kernel_size=2, stride=2),)self.linear = nn.Sequential(nn.AdaptiveAvgPool2d((7, 7)),nn.Flatten(),nn.Linear(in_features=512 * 7 * 7, out_features=4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(in_features=4096, out_features=4096), nn.ReLU(), nn.Dropout(0.5),nn.Linear(in_features=4096, out_features=output_channel))def forward(self, x):output = self.conv(x)output = self.linear(output)return output
参考链接
为什么深度学习图像分类的输入多是224*224
https://blog.csdn.net/weixin_43183872/article/details/109179104
VGG介绍
https://www.cnblogs.com/wangguchangqing/p/10338560.html
AdaptiveAvgPool
https://blog.csdn.net/qq_41997920/article/details/98963215
https://www.zhihu.com/question/282046628
BatchNormal
https://www.jianshu.com/p/913e4c08a638
https://blog.csdn.net/qq_36560894/article/details/104679338
https://a-kali.github.io/2020/11/12/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E4%B8%AD%E7%9A%84%E5%BD%92%E4%B8%80%E5%8C%96/
https://www.w3cschool.cn/article/36979814.html
Dropout
https://blog.csdn.net/qq_36560894/article/details/104685895
https://zhuanlan.zhihu.com/p/61725100
https://kknews.cc/code/mnvee3p.html
Normalize

若有收获,就点个赞吧
0 人点赞
