我们先分析下 https://www.ip138.com/ 这个网站,它可以获取到我们的IP及所在区域:
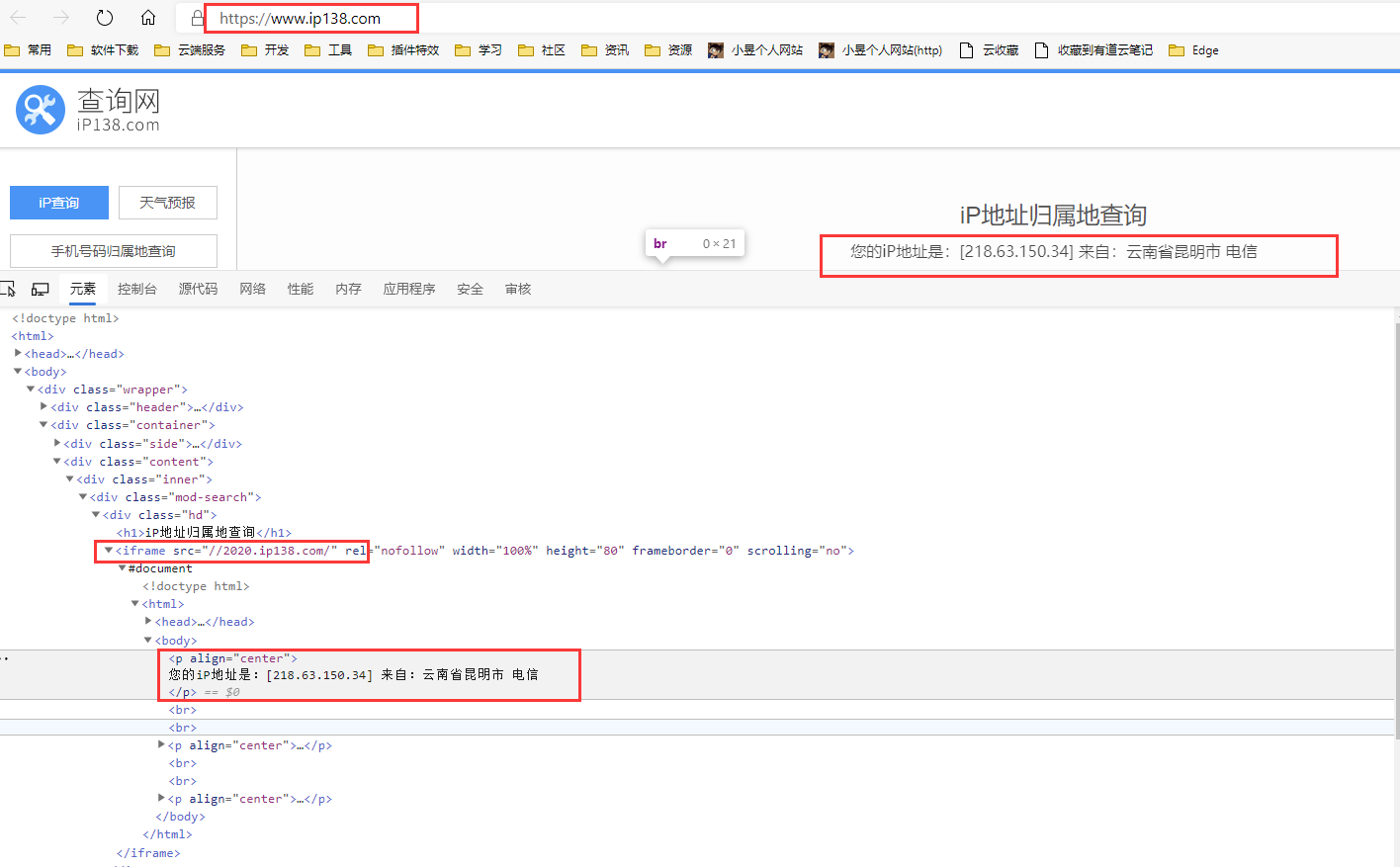
分析可知,其嵌套一个iframe,将 2020.ip138.com 的内容嵌入。
我们的目的是伪造一个headers,骗过此网站,让其解析伪造的IP。
开始编码
首先我们编写一个正常的爬虫,返回我们当前的IP:
# -*- coding: utf-8 -*-import scrapyclass Ip138Spider(scrapy.Spider):name = 'ip138'allowed_domains = ['ip138.com']start_urls = ['http://2020.ip138.com']def parse(self, response):print("=" * 40)print(response.css('p::text').extract_first())print("=" * 40)
在未伪造headers的时候,启动爬虫程序,会正常返回我的ip及所在地区

伪造IP
首先我们创建一个工具类,提供要给方法,用于伪造headers信息:
#! /usr/bin/env python3# -*- coding:utf-8 -*-import randomfrom ip138_fake_headers.settings import USER_AGENT_LISTclass Utils(object):@staticmethoddef get_header(host, ip=None):if ip is None:ip = str('%s.%s.%s.%s' % (random.choice(list(range(255))),random.choice(list(range(255))),random.choice(list(range(255))),random.choice(list(range(255)))))return {'Host': host,'User-Agent': random.choice(USER_AGENT_LIST),'server-addr': '','remote_user': '','X-Client-IP': ip,'X-Remote-IP': ip,'X-Remote-Addr': ip,'X-Originating-IP': ip,'x-forwarded-for': ip,'Origin': 'http://' + host,"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8","Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.5,en;q=0.3","Accept-Encoding": "gzip, deflate","Referer": "http://" + host + "/",'Content-Length': '0',"Connection": "keep-alive"}
这里引入了配置文件,我们需要在settings.py中配置USER_AGENT_LIST:
USER_AGENT_LIST=["Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1","Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3","Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3","Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3","Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24","Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"]
然后配置中间件:
# -*- coding: utf-8 -*-from ip138_fake_headers.libs.utils import Utilsfrom scrapy.http.headers import Headersclass Ip138FakeHeadersDownloaderMiddleware(object):def process_request(self, request, spider):request.headers = Headers(Utils.get_header('2020.ip138.com'))
在配置文件中启用中间件:
ROBOTSTXT_OBEY = FalseDOWNLOADER_MIDDLEWARES = {'ip138_fake_headers.middlewares.Ip138FakeHeadersDownloaderMiddleware': 1,}
启动爬虫程序,可以看到,伪造IP成功:

参考资料

若有收获,就点个赞吧
0 人点赞
