仍然以之前抓取豆瓣电影Top250为例。
爬虫程序跟之前抓取豆瓣电影保存到纯文本文件一致:
# -*- coding: utf-8 -*-import scrapyfrom douban_mongodb.items import DoubanMongodbItemclass Top250Spider(scrapy.Spider):name = 'top250'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250/']def parse(self, response):doubanItem = DoubanMongodbItem()items = response.xpath('//div[@class="item"]')for item in items:title = item.xpath('.//span[@class="title"]/text()').extract_first()detail_page_url = item.xpath('./div[@class="pic"]/a/@href').extract_first()star = item.xpath('.//span[@class="rating_num"]/text()').extract_first()pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()doubanItem['title'] = titledoubanItem['detail_page_url'] = detail_page_urldoubanItem['star'] = stardoubanItem['pic_url'] = pic_urlyield doubanItemnext = response.xpath('//div[@class="paginator"]//span[@class="next"]/a/@href').extract_first()if next is not None:next = response.urljoin(next)yield scrapy.Request(next, callback=self.parse)
提取的item也一致:
# -*- coding: utf-8 -*-import scrapyclass DoubanMongodbItem(scrapy.Item):title = scrapy.Field()detail_page_url = scrapy.Field()star = scrapy.Field()pic_url = scrapy.Field()
配置也一致:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'ROBOTSTXT_OBEY = False# 启动图片下载中间件ITEM_PIPELINES = {'douban_mongodb.pipelines.DoubanMongodbPipeline': 300,}
唯一需要改变的就是Pipeline。
连接数据库, 我们需要使用到 pymongo 模块, 使用 pip install pymongo 进行安装。
在 __init__ 中进行数据库连接的初始化操作,在 process_item 方法中将数据转化为字典进行存储即可。
# -*- coding: utf-8 -*-from pymongo import MongoClientclass DoubanMongodbPipeline(object):def __init__(self, databaseIp='127.0.0.1', databasePort=27017, mongodbName='test'):client = MongoClient(databaseIp, databasePort)self.db = client[mongodbName]# 我的MongoDB无密码,如果有密码可以使用以下代码认证# self.db.authenticate(user, password)def process_item(self, item, spider):postItem = dict(item) # 把item转化成字典形式self.db.scrapy.insert(postItem) # 向数据库插入一条记录return item # 会在控制台输出原item数据,可以选择不写
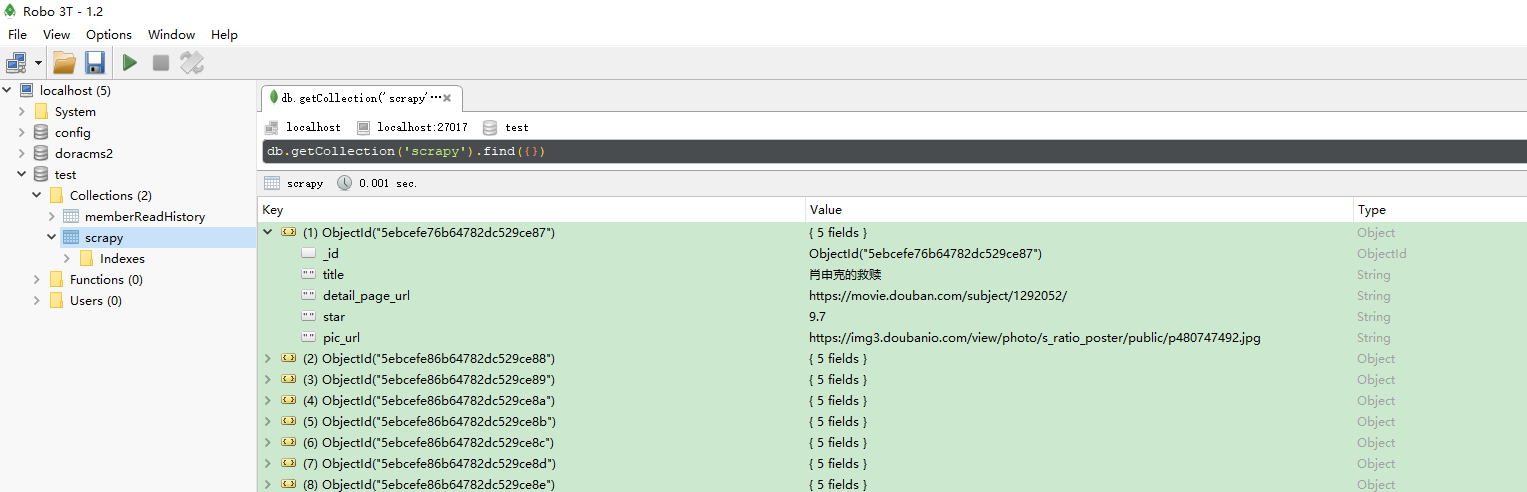
ok,执行爬虫程序,可以看到豆瓣电影top250的信息都已经存储到数据库了:

若有收获,就点个赞吧
0 人点赞
