我们继续撸豆瓣,创建项目什么的不说了,直接开始爬虫的编写。
爬虫的基本结构跟之前的一样:
# -*- coding: utf-8 -*-import scrapyfrom douban_images.items import DoubanImagesItemclass ImagesSpider(scrapy.Spider):name = 'images'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250/']def parse(self, response):doubanItem = DoubanImagesItem()items = response.xpath('//div[@class="item"]')for item in items:name = item.xpath('.//span[@class="title"]/text()').extract_first()pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()doubanItem['name'] = namedoubanItem['pic_url'] = pic_urlyield doubanItemnext = response.xpath('//div[@class="paginator"]//span[@class="next"]/a/@href').extract_first()if next is not None:next = response.urljoin(next)yield scrapy.Request(next, callback=self.parse)
items.py 也一样:
# -*- coding: utf-8 -*-import scrapyclass DoubanImagesItem(scrapy.Item):name = scrapy.Field()pic_url = scrapy.Field()
到了pipelines.py,情况有些不一样了,先上代码,后解释:
# -*- coding: utf-8 -*-# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.htmlfrom scrapy.pipelines.images import ImagesPipelinefrom scrapy import Requestclass DoubanImagesPipeline(ImagesPipeline):# 获取图片资源def get_media_requests(self, item, info):name = item['name']pic_url = item['pic_url']# 请求传过来的图片地址以获取图片资源yield Request(pic_url, meta={'name': name})# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字def file_path(self, request, response=None, info=None):ext = request.url.split('.')[-1]name = request.meta['name'].strip()filename = u'{1}.{2}'.format(name, name, ext)return filename
这里的话主要继承了scrapy的:ImagesPipeline这个类,我们需要在里面实现: get_media_requests(self, item, info) 这个方法,这个方法主要是把蜘蛛 yield 过来的图片链接执行下载。
主体代码准备完毕,还需要修改配置文件settings.py:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'ROBOTSTXT_OBEY = False# 启动图片下载中间件ITEM_PIPELINES = {'douban_images.pipelines.DoubanImagesPipeline': 300,}# 设置图片存储目录IMAGES_STORE = 'F:/images'
scrapy 给我们提供了一个常量:IMAGES_STORE,用于定义存储图片的路径, 可以是绝对路径也可以是相对路径, 相对路径相对于项目根目录。
开启爬虫:scrapy crawl images
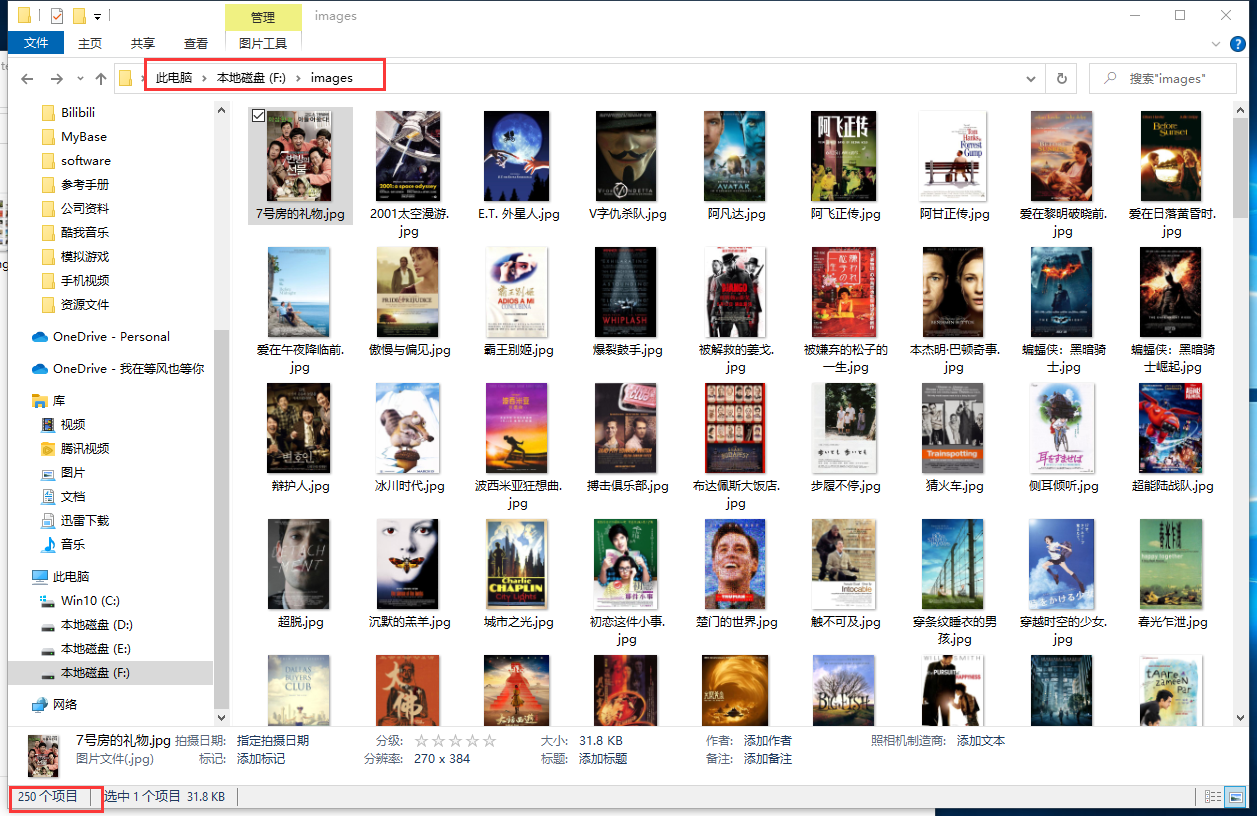
爬取完毕,可以看到目标文件夹里已经获取了250张图片:

若有收获,就点个赞吧
0 人点赞
