仍然以之前抓取豆瓣电影Top250为例。
首先在MySQL的test数据库中创建数据表:
CREATE TABLE `douban_videos` (`id` int(11) NOT NULL AUTO_INCREMENT,`title` varchar(255) DEFAULT NULL,`detail_page_url` varchar(255) DEFAULT NULL,`star` varchar(255) DEFAULT NULL,`pic_url` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
爬虫程序跟之前抓取豆瓣电影保存到纯文本文件一致:
# -*- coding: utf-8 -*-
import scrapy
from douban_mysql.items import DoubanMysqlItem
class Top250Spider(scrapy.Spider):
name = 'top250'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250/']
def parse(self, response):
doubanItem = DoubanMysqlItem()
items = response.xpath('//div[@class="item"]')
for item in items:
title = item.xpath('.//span[@class="title"]/text()').extract_first()
detail_page_url = item.xpath('./div[@class="pic"]/a/@href').extract_first()
star = item.xpath('.//span[@class="rating_num"]/text()').extract_first()
pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()
doubanItem['title'] = title
doubanItem['detail_page_url'] = detail_page_url
doubanItem['star'] = star
doubanItem['pic_url'] = pic_url
yield doubanItem
next = response.xpath('//div[@class="paginator"]//span[@class="next"]/a/@href').extract_first()
if next is not None:
next = response.urljoin(next)
yield scrapy.Request(next, callback=self.parse)
提取的item也一致:
# -*- coding: utf-8 -*-
import scrapy
class DoubanMysqlItem(scrapy.Item):
title = scrapy.Field()
detail_page_url = scrapy.Field()
star = scrapy.Field()
pic_url = scrapy.Field()
配置也一致:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
ROBOTSTXT_OBEY = False
# 启动图片下载中间件
ITEM_PIPELINES = {
'douban_mysql.pipelines.DoubanMysqlPipeline': 300,
}
唯一需要改变的就是Pipeline。
连接数据库, 我们需要使用到 pymysql 模块, 使用 pip install pymysql 进行安装。
数据库连接的初识化, 放于管道类的 __init__ 中, 并将游标保存。
在 process_item 方法中, 使用初始化时创建的游标进行数据库操作。
# -*- coding: utf-8 -*-
import pymysql.cursors
class DoubanMysqlPipeline(object):
def __init__(self):
# 连接数据库
self.connect = pymysql.connect(
host='127.0.0.1', # 数据库地址
port=3306, # 数据库端口
db='test', # 数据库名
user='root', # 数据库用户名
passwd='root', # 数据库密码
charset='utf8', # 编码方式
use_unicode=True)
# 通过cursor执行增删查改
self.cursor = self.connect.cursor()
# 如果没有则创建表
self.cursor.execute("""
CREATE TABLE IF NOT EXISTS `douban_videos` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL,
`detail_page_url` varchar(255) DEFAULT NULL,
`star` varchar(255) DEFAULT NULL,
`pic_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
""")
def process_item(self, item, spider):
# 检查是否已经存在数据
value = self.cursor.execute(
"""
select title from douban_videos where title=%s
""", item['title']
)
if value == 0:
self.cursor.execute(
"""
insert into douban_videos(title, detail_page_url, star, pic_url ) value (%s, %s, %s, %s)
""",
(item['title'], item['detail_page_url'], item['star'], item['pic_url']))
# 提交sql语句
self.connect.commit()
return item
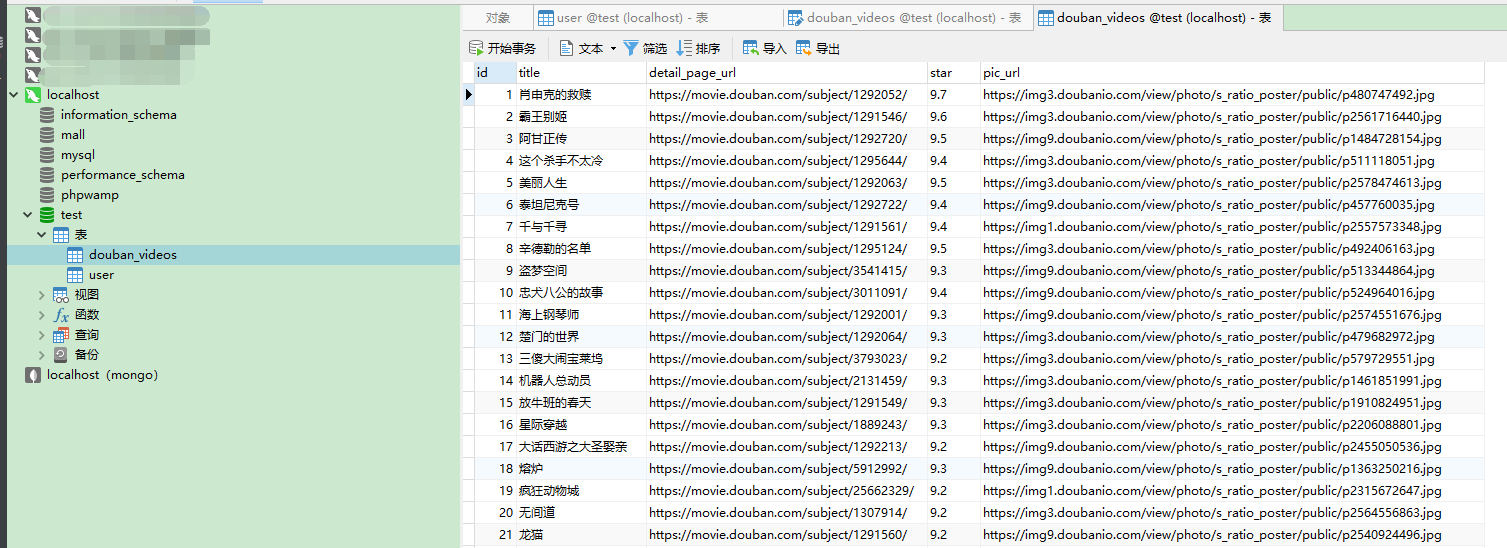
ok,执行爬虫程序,可以看到豆瓣电影top250的信息都已经存储到数据库了:

若有收获,就点个赞吧
0 人点赞
