看到网上大都是豆瓣爬虫登录的示例,于是自己也搞了一个。
登录逻辑分析
跟网上看到的不太一样,网上基本上都是抓取页面,获取到登录页表单,检测时候有验证码,如果有则下载,没有则直接表单提交登录。而通过我自己对豆瓣登录页的分析,并没有看到页面包括表单元素,豆瓣的登录是通过Ajax提交的。
登录页地址:https://accounts.douban.com/passport/login
使用Ajax登录豆瓣
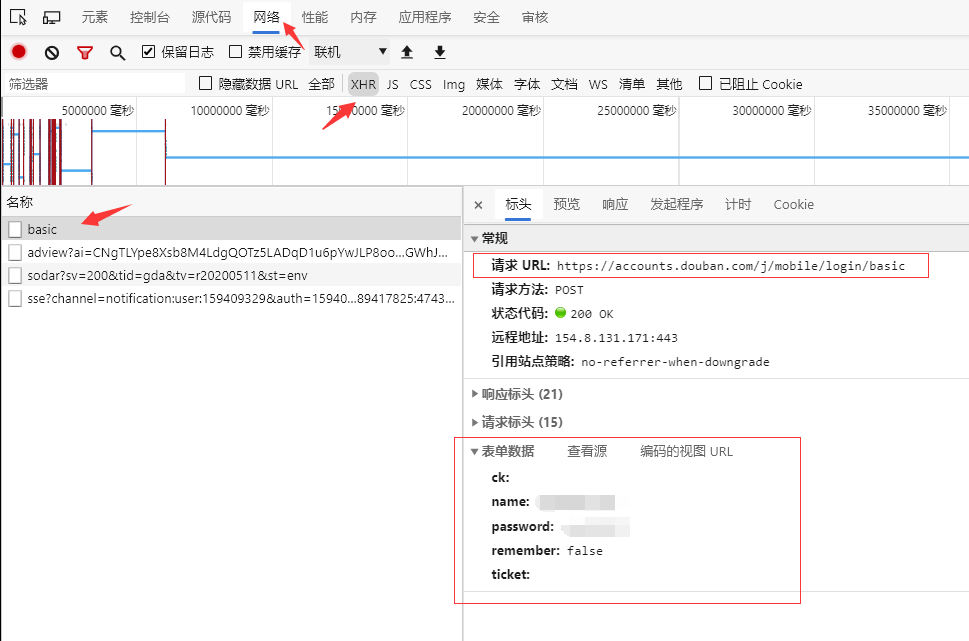
既然找出了登录接口,那么要使用程序登录也不在话下了,我们先使用postman测试一下
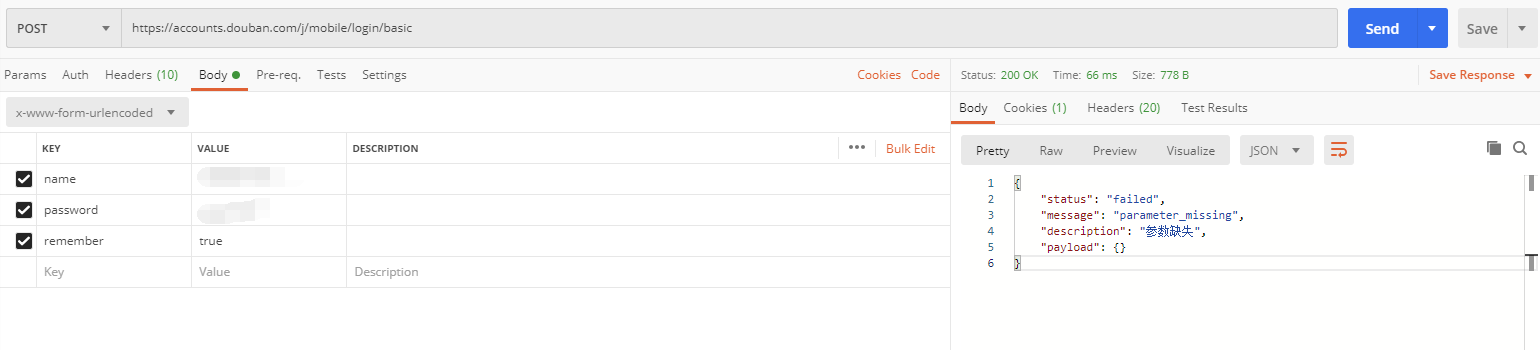
第一次发送请求,服务器返回参数错误,查看了下cookie,发现服务器种了一个cookie:
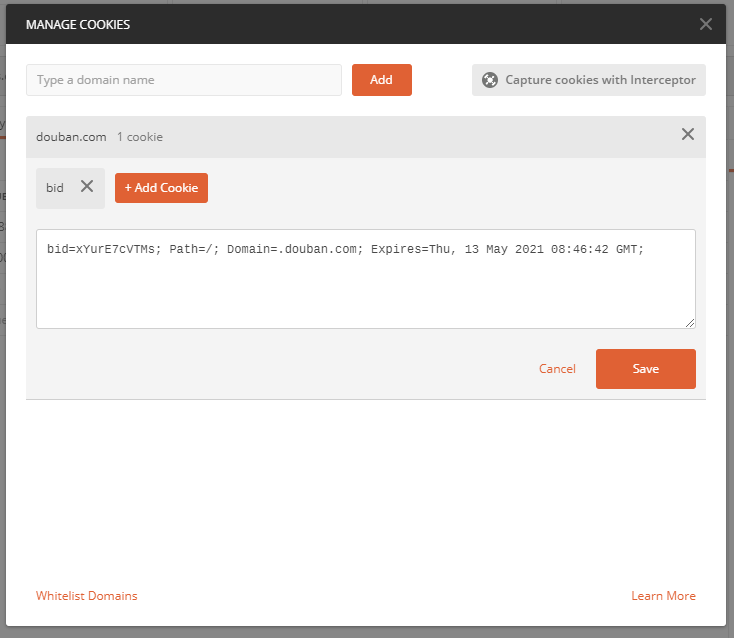
再次发送请求,将会携带这个cookie,发现登录成功了:
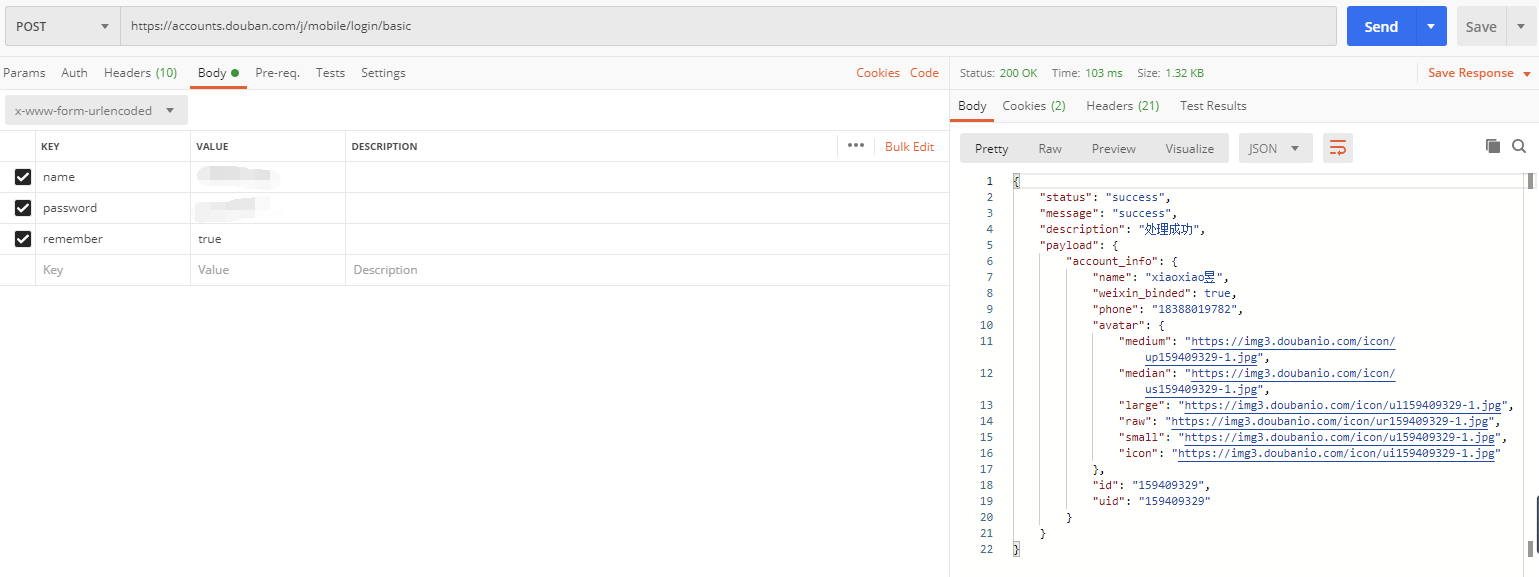
ok,到此,登录逻辑已经捋顺了,需要调用登录接口两次:第一次获取cookie,第二次携带cookie访问
登录接口如下:
https://accounts.douban.com/j/mobile/login/basic
使用POST请求发送,携带以下头部信息:
Content-Type: application/x-www-form-urlencodedCookie: ...Accept: application/jsonUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36 Edg/81.0.416.68
传递以下几个参数:
name 用户名password 密码remember 是否记住密码
登录前后页面分析
我们以豆瓣首页为例:https://www.douban.com/
在登录前访问豆瓣首页,看到页面长这样:
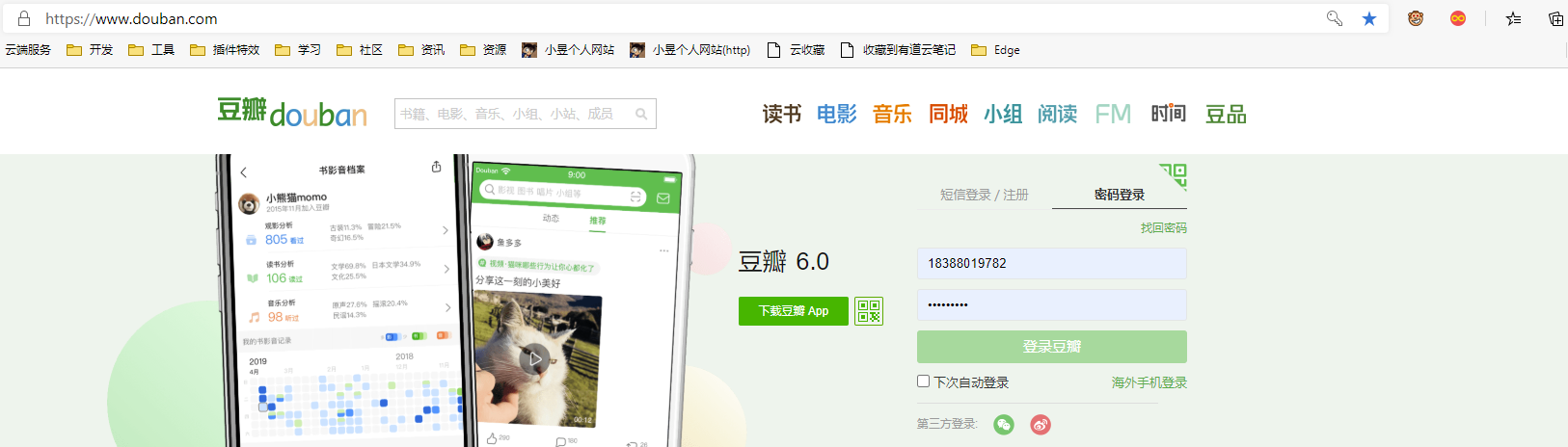
有一个登录框,顶部有一行菜单:“读书”、“电影”等等
在登录后访问豆瓣首页,看到页面长这样:
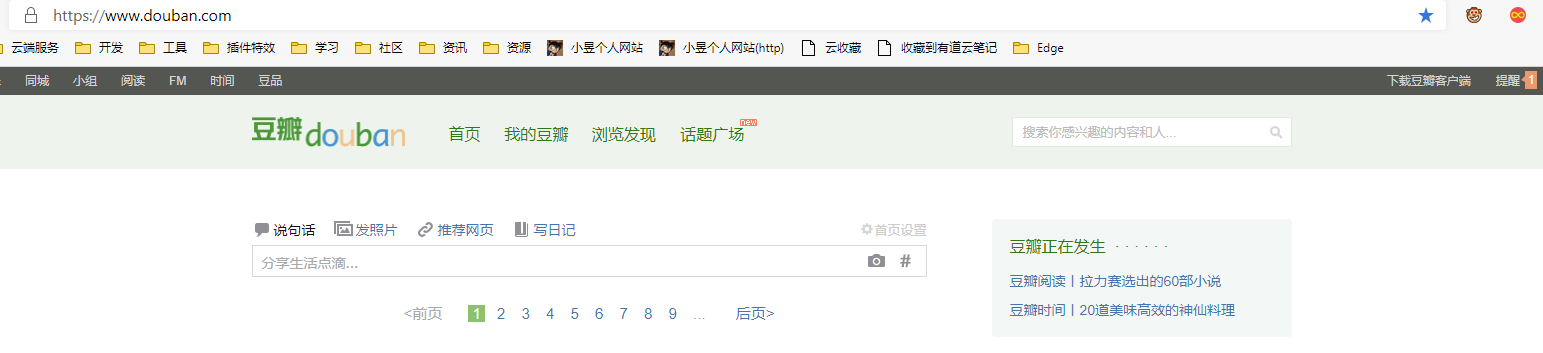
顶部菜单变为了“首页”、“我的豆瓣”等等,没有了输入框
我们点击“我的豆瓣”,可以看到豆瓣个人主页:
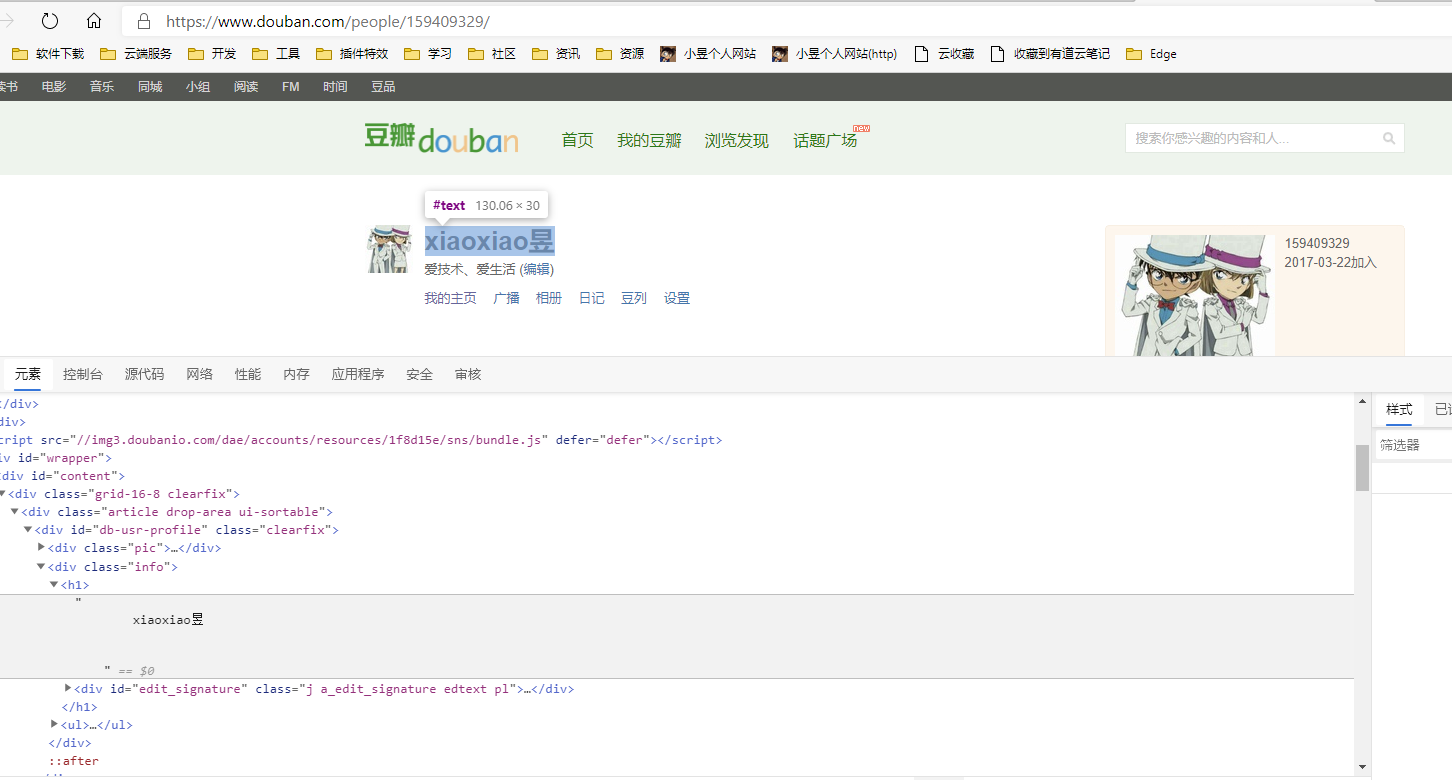
在豆瓣主页中可以看到我们的昵称等信息。
我们退出登录,再次输入个人主页地址:https://www.douban.com/mine/,可以看到会被重定向到登录页面。
好的,所有逻辑都明了了,如果登录,我们跳转到个人主页,看下能不能获取到个人昵称,如果获取得到,说明登录成功了。
具体程序实现
spider程序如下:
# -*- coding: utf-8 -*-import scrapyimport jsonclass LoginSpider(scrapy.Spider):name = 'login'url = 'https://accounts.douban.com/j/mobile/login/basic'data = {'name': 'your name','password': 'your password','remember': "true"}def start_requests(self):# 第一次登录,由于缺少cookie,会返回登录错误,并设置cookieyield scrapy.FormRequest(url=self.url,formdata=self.data,method='POST',callback=self.getCookie)def getCookie(self, response):# scrapy会自动携带上一个请求设置的cookieyield scrapy.FormRequest(url=self.url,formdata=self.data,method='POST',callback=self.parse,# 添加以防止出现:Filtered duplicate requestdont_filter=True)def parse(self, response):res = json.loads(response.body.decode())print("========")print(res)print("========")url = "https://www.douban.com/"yield scrapy.Request(url, callback=self.getHomePage)def getHomePage(self, response):navs = response.xpath("//div[@class='nav-items']//li")for nav in navs:title = nav.xpath(".//a/text()").extract_first().strip()url = nav.xpath(".//a/@href").extract_first()print(title.strip())print(url)if '我的豆瓣' in title:yield scrapy.Request(url, callback=self.getMyPage)def getMyPage(self, response):name = response.xpath("//div[@class='info']//h1/text()").extract_first().strip()print("====start: getMyPage====")print(name)print("====end: getMyPage====")
这里值得说明的是,第一次登录成功后,scrapy会保存获取到的cookie,在第二次访问登录接口的时候,会自动携带cookie访问。
第二次调用登录接口的时候,需要在请求中配置参数dont_filter=True,否则,Scrapy会认为此接口已经访问过了,不需要重新访问,返回一个Debug信息:Filtered duplicate request
登录成功后,获取顶部导航栏菜单,访问“我的豆瓣”,查看是否能够获取到昵称。
运行爬虫,看到控制台打印出以下数据(主要是要看到自己的昵称),说明登录成功了: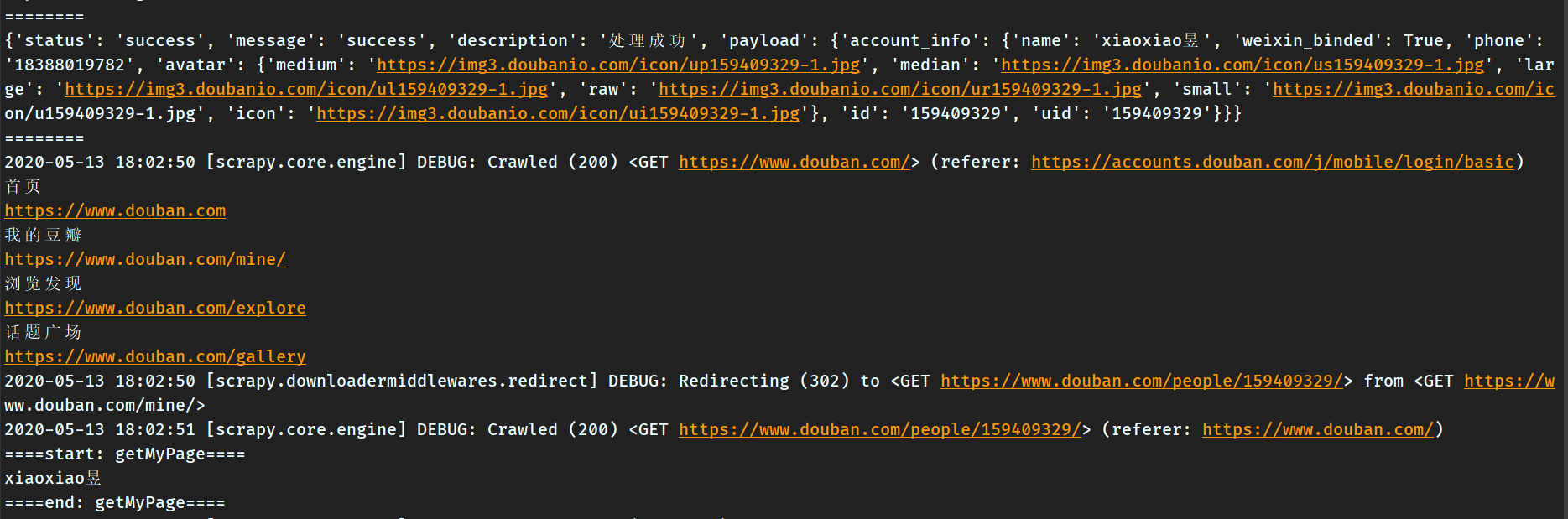
注意需要在settings.py中进行以下配置:
# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'# Obey robots.txt rulesROBOTSTXT_OBEY = False

若有收获,就点个赞吧
0 人点赞
