我们知道,为了加速页面的加载速度,页面的很多部分都是用JS生成的,而对于用scrapy爬虫来说就是一个很大的问题,因为scrapy没有JS engine,所以爬取的都是静态页面,对于JS生成的动态页面直接使用scrapy的Request请求都无法获得,解决的方法就是使用scrapy-splash。
scrapy-splash加载js数据是基于Splash来实现的,Splash是一个Javascript渲染服务。它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT,而我们使用scrapy-splash最终拿到的response相当于是在浏览器全部渲染完成以后,拿到的渲染之后的网页源代码。
通过Dockers安装splash
docker pull scrapinghub/splashdocker run -p 8050:8050 --name splash scrapinghub/splash
可以看到打印出信息:
2020-05-15 02:30:15+0000 [-] Log opened.2020-05-15 02:30:15.862787 [-] Xvfb is started: ['Xvfb', ':394173637', '-screen', '0', '1024x768x24', '-nolisten', 'tcp']QStandardPaths: XDG_RUNTIME_DIR not set, defaulting to '/tmp/runtime-splash'2020-05-15 02:30:15.952063 [-] Splash version: 3.4.12020-05-15 02:30:16.009290 [-] Qt 5.13.1, PyQt 5.13.1, WebKit 602.1, Chromium 73.0.3683.105, sip 4.19.19, Twisted 19.7.0, Lua 5.22020-05-15 02:30:16.009463 [-] Python 3.6.9 (default, Nov 7 2019, 10:44:02) [GCC 8.3.0]2020-05-15 02:30:16.009546 [-] Open files limit: 10485762020-05-15 02:30:16.009624 [-] Can't bump open files limit2020-05-15 02:30:16.024493 [-] proxy profiles support is enabled, proxy profiles path: /etc/splash/proxy-profiles2020-05-15 02:30:16.024664 [-] memory cache: enabled, private mode: enabled, js cross-domain access: disabled2020-05-15 02:30:16.148110 [-] verbosity=1, slots=20, argument_cache_max_entries=500, max-timeout=90.02020-05-15 02:30:16.148346 [-] Web UI: enabled, Lua: enabled (sandbox: enabled), Webkit: enabled, Chromium: enabled2020-05-15 02:30:16.148725 [-] Site starting on 80502020-05-15 02:30:16.148809 [-] Starting factory <twisted.web.server.Site object at 0x7faf2f65b1d0>2020-05-15 02:30:16.149072 [-] Server listening on http://0.0.0.0:8050
说明slpash服务已经启动,监听8050端口。
浏览器访问 http://localhsot:8050,看到界面:
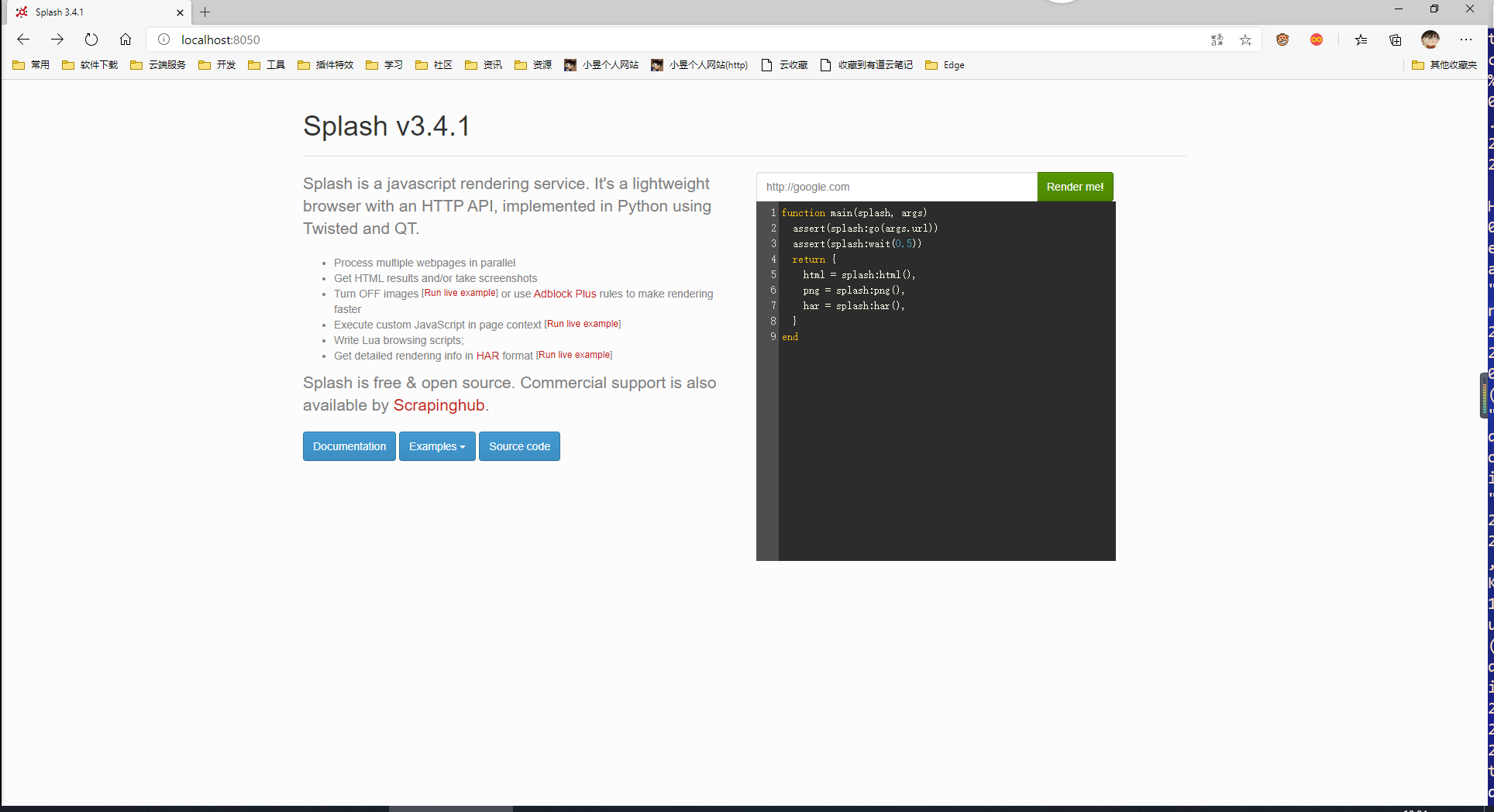
在Python中的准备工作
安装 scrapy-splash
pip install scrapy-splash
创建项目:
scrapy startproject taobao_splash
cd taobao_splash
scrapy genspider taobao s.taobao.com
配置文件 settings.py:
# -*- coding: utf-8 -*-
BOT_NAME = 'taobao_splash'
SPIDER_MODULES = ['taobao_splash.spiders']
NEWSPIDER_MODULE = 'taobao_splash.spiders'
# 渲染服务的url
SPLASH_URL = 'http://localhost:8050'
# 去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
# 使用Splash的Http缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
分析淘宝页面
我们先在Postman中测试一下:
直接访问搜索页面: http://s.taobao.com/search?q=iphone,发现会被重定向到首页,而不是搜索页面,说明需要登录才能进行接下来的操作。
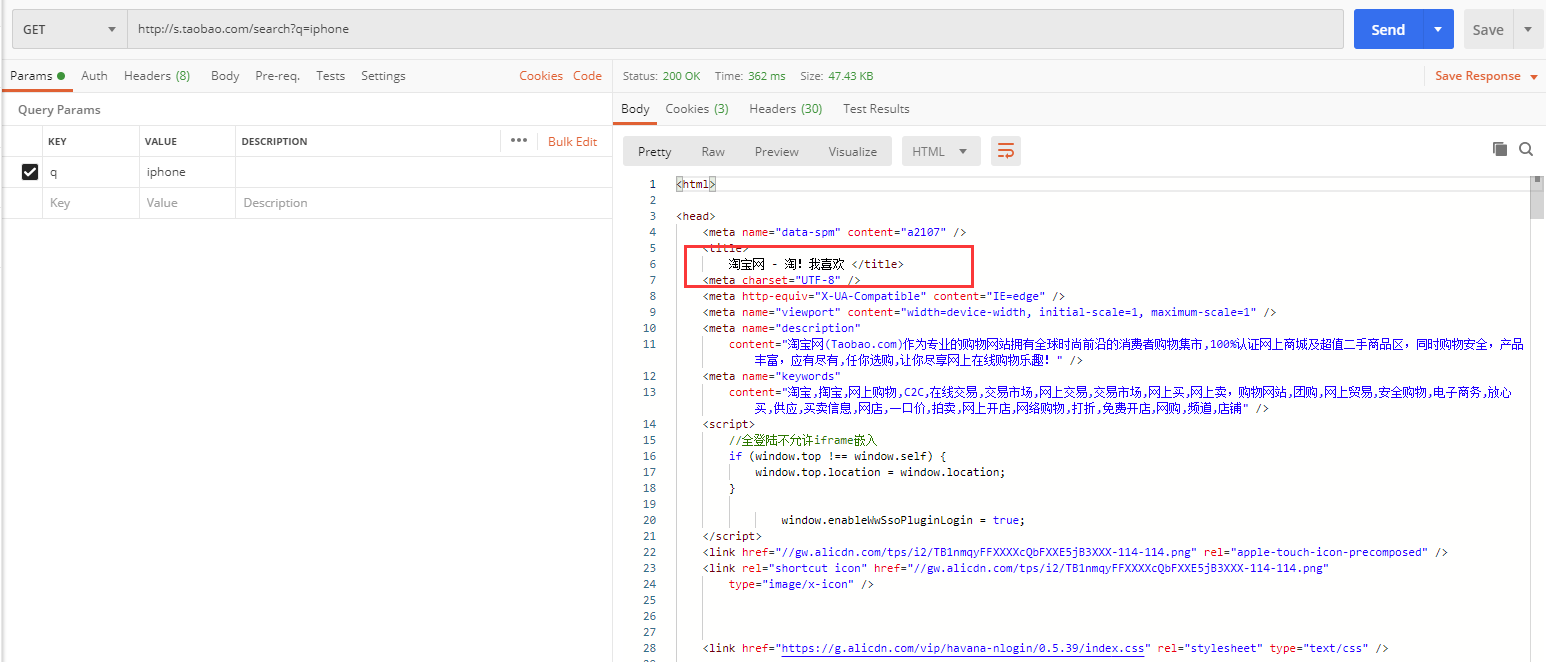
我们到浏览器中找找登录接口:
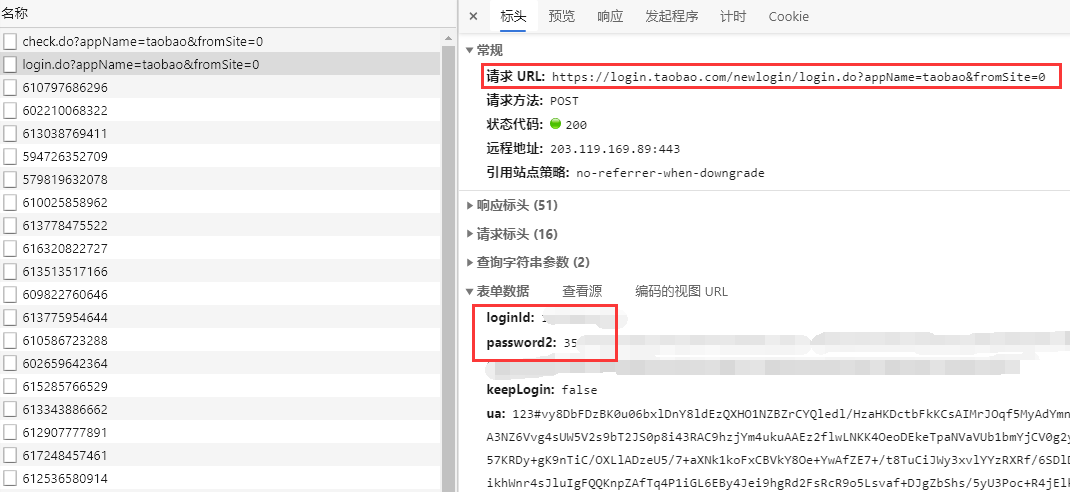
发现是这个接口:https://login.taobao.com/newlogin/login.do?appName=taobao&fromSite=0
我们在Postman中进行登录:
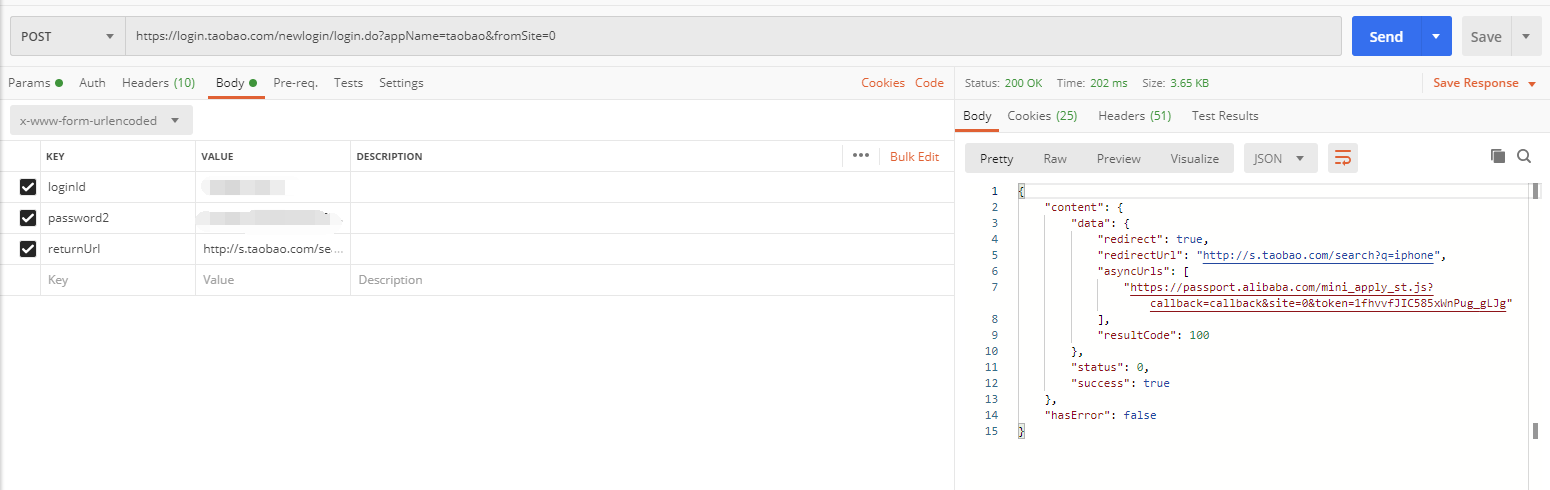
再次访问搜索页面,发现能够正常获取:
爬虫编写
在蜘蛛文件中:
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
class TaobaoSpider(scrapy.Spider):
name = 'taobao'
allowed_domains = ['taobao.com']
def start_requests(self):
loginUrl = "https://login.taobao.com/newlogin/login.do?appName=taobao&fromSite=0"
yield scrapy.FormRequest(loginUrl, formdata={
"loginId": "your phone",
"password2": "your password(已加密)"
}, callback=self.parse)
def parse(self, response):
print(response.body)
url = 'https://s.taobao.com/search?q=iphone'
# 如果直接请求,内容还未来得及渲染就返回了
# yield scrapy.Request(url, callback=self.getContent)
# 通过SplashRequest请求,等待解析0.1秒后返回(时间可适当增加以保证页面完全解析渲染完成)
yield SplashRequest(url, self.getContent, args={'wait': 0.1})
def getContent(self, response):
titles = response.xpath('//div[@class="row row-2 title"]/a/text()').extract()
for title in titles:
print(title.strip())
这个地方使用了SplashRequest,传递了一个参数wait,表示等待splash解析0.1秒后返回解析后的结果,等待时间可以自己适当调整。
如果我们将请求换为普通的 scrapy.Request,则可以看到返回结果为空,说明数据是异步解析加载渲染的。
执行爬虫:
scrapy crawl taobao
发现能够正常返回数据:
参考资料

若有收获,就点个赞吧
0 人点赞
