Forbidden by robots.txt
开启爬虫,可能会遇到 Forbidden by robots.txt
解决方法很简单,只需要在settings.py中添加以下配置即可
ROBOTSTXT_OBEY = False
robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
访问一下 https://www.baidu.com/robots.txt,最后我们可以看见
User-agent: *Disallow: /
简单来说,就是百度禁止一切爬虫。当然,尊不遵守君子协定就看你个人了。
DNS lookup failed:no results for hostname lookup
错误详情:
DNS lookup failed: no results for hostname lookup: ....
错误原因:Scrapy先去看了眼robots.txt,发现网站设置为不允许爬虫访问,则终止访问
解决方案:修改setting.py文件,将ROBOTSTXT_OBEY的True改为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
crawl Unknown command
错误详情:
$ scrapy crawl zys201811
Scrapy 2.1.0 - no active project
Unknown command: crawl
Use "scrapy" to see available commands
错误原因:scrapy.cfg文件丢失
解决方案:创建scrapy.cfg即可
scrapy.cfg:
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = shianonline.settings
[deploy]
#url = http://localhost:6800/
project = shianonline
注意把文件中的default和project改成自己的工程名: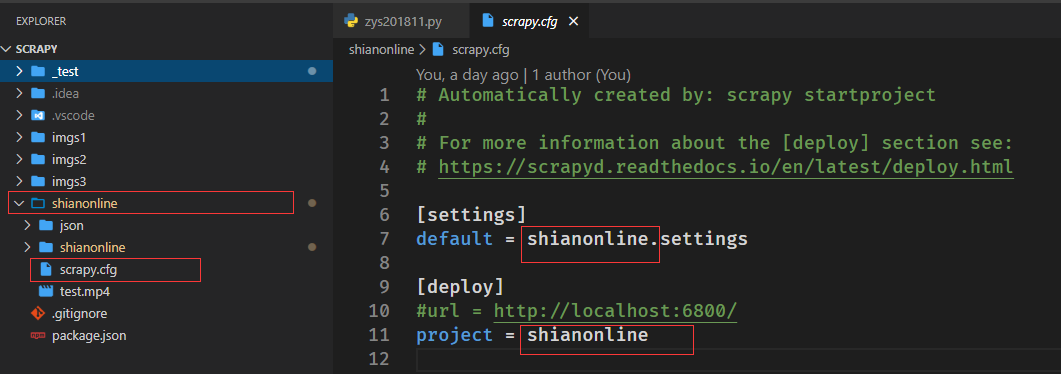
Filtered duplicate request
错误详情:
[scrapy] DEBUG:Filtered duplicate request:<GET:xxxx>-no more duplicates will be shown
这个的问题是CrawlSpider结合LinkExtractor\Rule在提取链接与发链接的时候,出现了重复的连接、重复的请求,出现这个DEBUG
或者是yield scrapy.Request(xxxurl,callback=self.xxxx)中有重复的请求
其实scrapy自身是默认有过滤重复请求的
让这个DEBUG不出现,可以在Request中添加 dont_filter=True 解决
yield scrapy.Request(url,callback=self.xxxx,dont_filter=True)
Filtered offsite request to
错误详情
2020-05-15 13:49:13 [scrapy.spidermiddlewares.offsite] DEBUG: Filtered offsite request to 's.taobao.com': <GET https://s.taobao.com/search?q=iphone>
错误原因:二级域名被过滤掉了
解决办法一:
yield scrapy.Request(url=detail_url, meta={'item': item}, callback=self.parse_info, dont_filter=True)
原理:忽略allowed_domains的过滤
解决办法二:
将 allowed_domains = ['www.taobao.com'] 更改为 allowed_domains = ['taobao.com'] 即更换为对应的一级域名
Connection to the other side was lost in a non-clean fashion: Connection lost
错误详情:
<twisted.python.failure.Failure twisted.internet.error.ConnectionLost: Connection to the other side was lost in a non-clean fashion: Connection lost.>
解决方案:将start_url 中的https改为http,或将http改为https,一般都能解决。
比如:
修改之前:
start_urls = ['https://2020.ip138.com']
修改之后:
start_urls = ['http://2020.ip138.com']
抓取结果为中文时保存为文件时的编码问题
抓取JSON格式数据示例:
有一个test.json文件如下:
{"k":"086,05,11,35,34,45,03,28,087,08,04,六,21点30分","t":"1000"}
spider如下:
# -*- coding: utf-8 -*-
import scrapy
import json
import codecs
class Zys201811Spider(scrapy.Spider):
name = 'zys201811'
allowed_domains = ['zys201811.oss-cn-shenzhen.aliyuncs.com']
start_urls = [
"https://zys201811.oss-cn-shenzhen.aliyuncs.com/test/test.json"
]
def parse(self, response):
# 调用body_as_unicode()是为了能处理unicode编码的数据
sites = json.loads(response.body_as_unicode())
# 读取JSON数据
numbers = sites['k'].split(',')
print(numbers)
# 存取JSON数据
fileName = 'd:/test.json'
with codecs.open(fileName, 'w+', encoding='utf-8') as f:
json.dump(sites, f, ensure_ascii=False)
爬取豆瓣返回403错误
错误详情:
2020-05-11 17:14:05 [scrapy.core.engine] DEBUG: Crawled (403) <GET http://movie.douban.com/top250/> (referer: None)
2020-05-11 17:14:05 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 http://movie.douban.com/top250/>: HTTP status code is not handled or
not allowed
2020-05-11 17:14:05 [scrapy.core.engine] INFO: Closing spider (finished)
解决方案:设置用户代理
在setting.py文件中增加USER_AGENT配置:
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
再次爬取发现已经200了:
2020-05-11 17:15:31 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://movie.douban.com/top250/> from <GET http://movie.doub
an.com/top250/>
2020-05-11 17:15:31 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (301) to <GET https://movie.douban.com/top250> from <GET https://movie.doub
an.com/top250/>
2020-05-11 17:15:31 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://movie.douban.com/top250> (referer: None)
2020-05-11 17:15:31 [scrapy.core.engine] INFO: Closing spider (finished)

若有收获,就点个赞吧
0 人点赞
