目的:我们制作一个爬虫,用来爬取豆瓣网评分比较高的电影,并保存到文件。
地址:https://movie.douban.com/top250
分析页面结构
主体结构分析
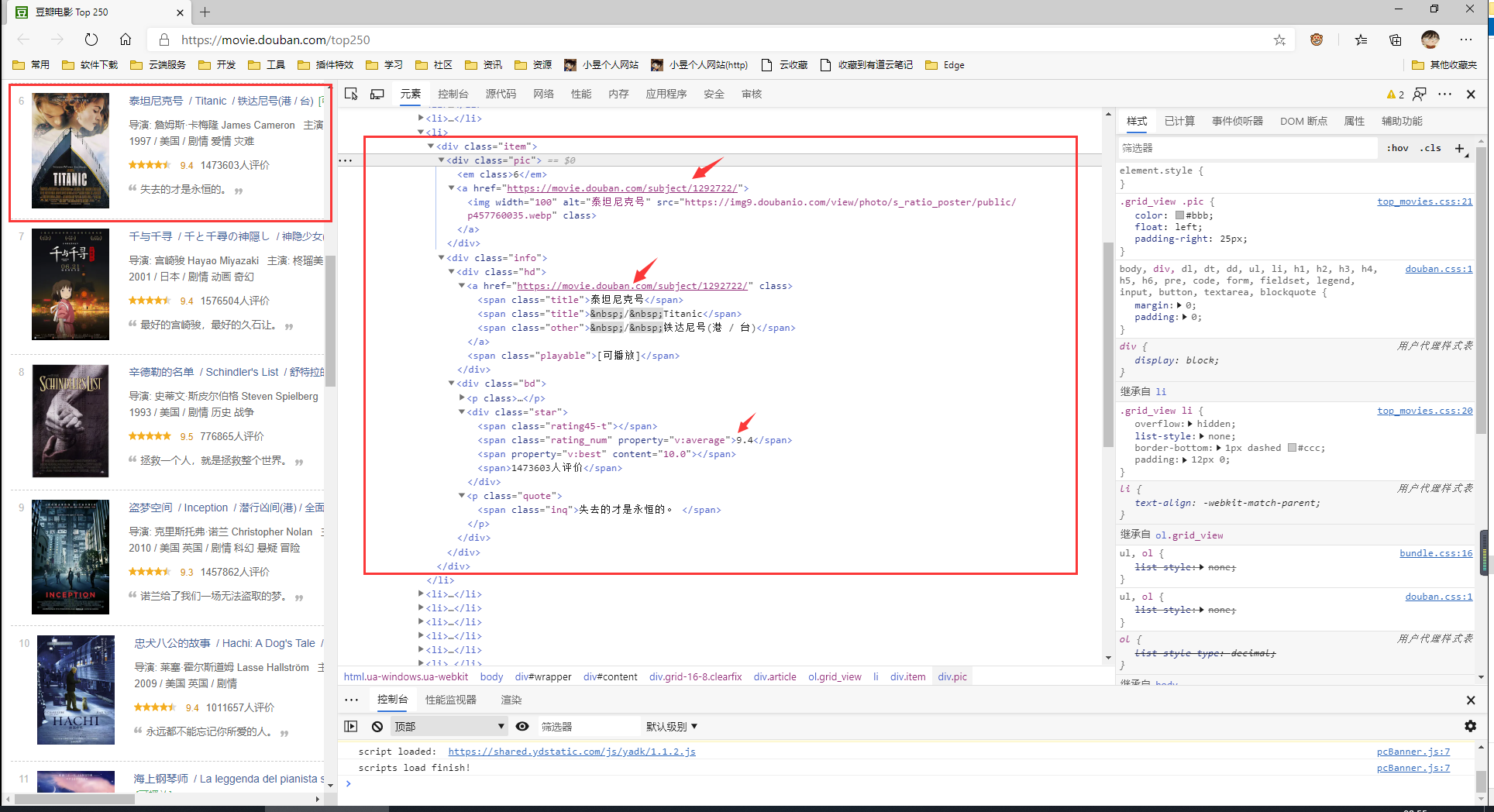
“下一页”按钮分析:
嵌套很明显了,很简单的页面结构,接下来就开始编写爬虫。
创建scrapy项目
scrapy startproject doubancd doubanscrapy genspider top250 movie.douban.com/top250
创建好的项目结构如下:
打开Top250Spider.py可以看到蜘蛛文件如下:
class Top250Spider(scrapy.Spider):name = 'top250'allowed_domains = ['movie.douban.com/top250']start_urls = ['http://movie.douban.com/top250/']def parse(self, response):pass
爬取数据
根据上面的分析,我们很容易写出爬取主体数据的代码:
# -*- coding: utf-8 -*-import scrapyclass Top250Spider(scrapy.Spider):name = 'top250'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250/']def parse(self, response):items = response.xpath('//div[@class="item"]')for item in items:title = item.xpath('.//span[@class="title"]/text()').extract_first()detail_page_url = item.xpath('./div[@class="pic"]/a/@href').extract_first()star = item.xpath('.//span[@class="rating_num"]/text()').extract_first()pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()
我们分析了,页面中存在“下一页”按钮,逻辑是:当“下一页”按钮不存在时,停止爬取,若存在,继续解析:
# -*- coding: utf-8 -*-import scrapyclass Top250Spider(scrapy.Spider):name = 'top250'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250/']def parse(self, response):doubanItem = DoubanItem()items = response.xpath('//div[@class="item"]')for item in items:title = item.xpath('.//span[@class="title"]/text()').extract_first()detail_page_url = item.xpath('./div[@class="pic"]/a/@href').extract_first()star = item.xpath('.//span[@class="rating_num"]/text()').extract_first()pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()next = response.xpath('//div[@class="paginator"]//span[@class="next"]/a/@href').extract_first()if next is not None:next = response.urljoin(next)yield scrapy.Request(next, callback=self.parse)
提取到Items
爬虫主体创建好了,我们需要将其有效信息提取到Item,编写items.py文件如下:
# -*- coding: utf-8 -*-import scrapyclass DoubanItem(scrapy.Item):title = scrapy.Field()detail_page_url = scrapy.Field()star = scrapy.Field()pic_url = scrapy.Field()
修改蜘蛛文件Top250Spider.py:
# -*- coding: utf-8 -*-import scrapyfrom douban.items import DoubanItemclass Top250Spider(scrapy.Spider):name = 'top250'allowed_domains = ['movie.douban.com']start_urls = ['https://movie.douban.com/top250/']def parse(self, response):doubanItem = DoubanItem()items = response.xpath('//div[@class="item"]')for item in items:title = item.xpath('.//span[@class="title"]/text()').extract_first()detail_page_url = item.xpath('./div[@class="pic"]/a/@href').extract_first()star = item.xpath('.//span[@class="rating_num"]/text()').extract_first()pic_url = item.xpath('./div[@class="pic"]/a/img/@src').extract_first()doubanItem['title'] = titledoubanItem['detail_page_url'] = detail_page_urldoubanItem['star'] = stardoubanItem['pic_url'] = pic_urlyield doubanItemnext = response.xpath('//div[@class="paginator"]//span[@class="next"]/a/@href').extract_first()if next is not None:next = response.urljoin(next)yield scrapy.Request(next, callback=self.parse)
编写Pipline
这里,我们使用csv进行表格存取,创建的管道如下:
# -*- coding: utf-8 -*-import csvclass DoubanPipeline:def __init__(self):with open("videos.csv", "w", newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow(["电影名", "详情页", "豆瓣评分", "封面图片"])def process_item(self, item, spider):title = item['title']detail_page_url = item['detail_page_url']star = item['star']pic_url = item['pic_url']with open("videos.csv", "a", newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerow([title, detail_page_url, star, pic_url])return item
当然,如果想要存为txt也很容易,稍微改写一下即可:
# -*- coding: utf-8 -*-import codecsclass DoubanPipeline:def __init__(self):with open("videos.txt", "w", newline='', encoding='utf-8') as f:f.write("{}\r\n".format("电影名, 详情页, 豆瓣评分, 封面图片"))def process_item(self, item, spider):title = item['title']detail_page_url = item['detail_page_url']star = item['star']pic_url = item['pic_url']txt = "{},{},{},{}".format(title, detail_page_url, star, pic_url)with codecs.open("videos.txt", 'a', encoding='utf-8') as f:f.write("{}\r\n".format(txt))return item
最后,别忘了在settings.py中加入这个管道:
...ITEM_PIPELINES = {'douban.pipelines.DoubanPipeline': 300,}
启动爬虫
当然,直接这样爬取会报403,因为豆瓣网禁止了爬虫行为,我们需要在settings.py中配置用户代理,并禁止访问robots.txt文件:
...# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'# Obey robots.txt rulesROBOTSTXT_OBEY = False
ok,开始爬取,执行:
scrapy crawl top250
爬取结果如下:
csv文件: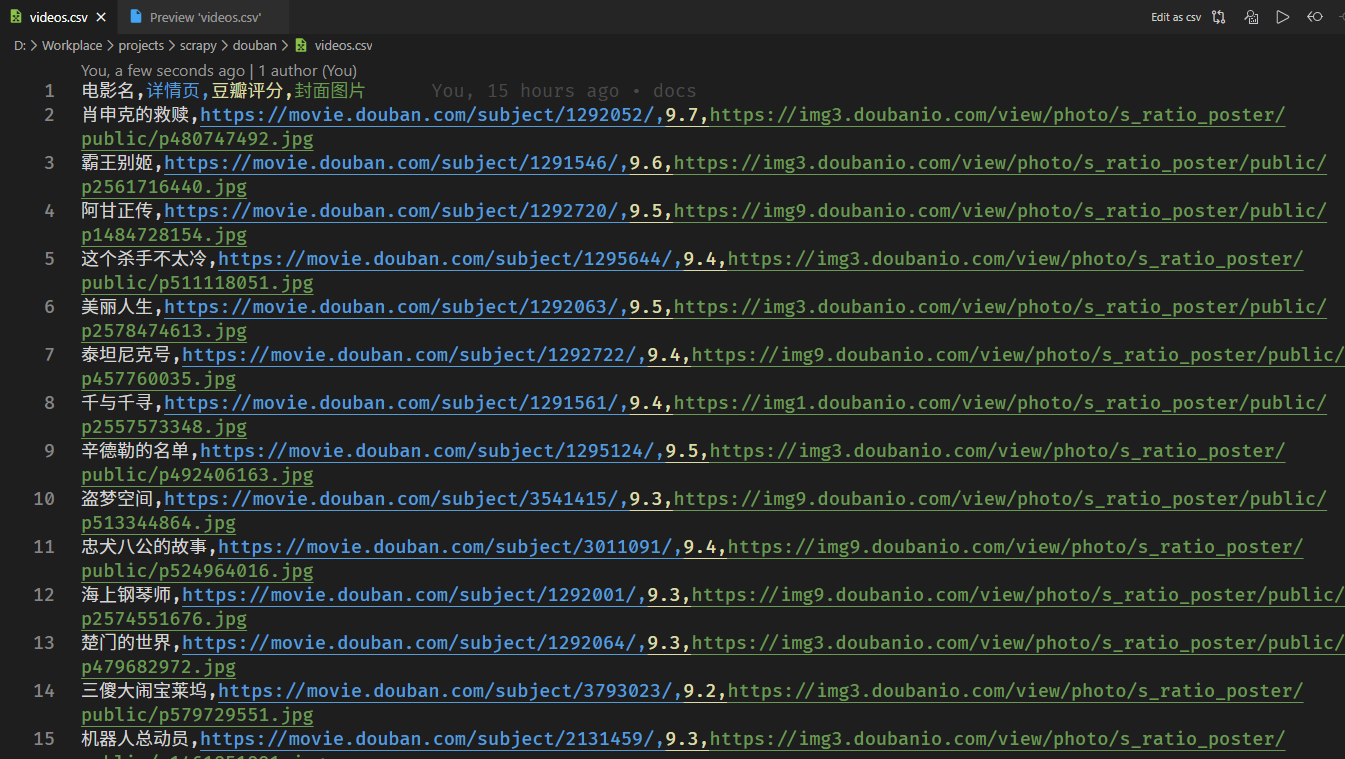
预览csv: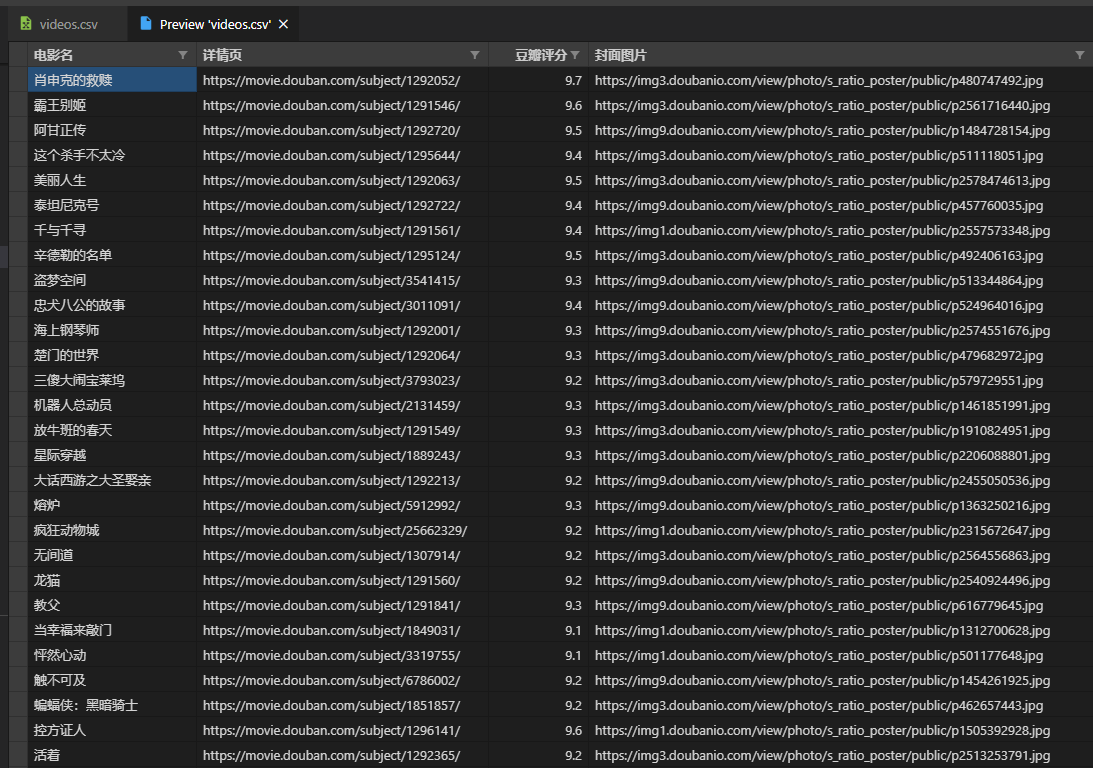

若有收获,就点个赞吧
0 人点赞
