我在一个网站上抓取到以下几个接口:
http://manage.shianonline.com:8082/main/jc-product/getAllProductListhttp://manage.shianonline.com:8082/main/jc-product-detail/getAllChapterByProductIdhttp://manage.shianonline.com:8082/main/jc-product-detail/getAllSectionByChapterhttp://manage.shianonline.com:8082/main/jc-product-detail/getAllDetailBySection
他们的请求方式如下:
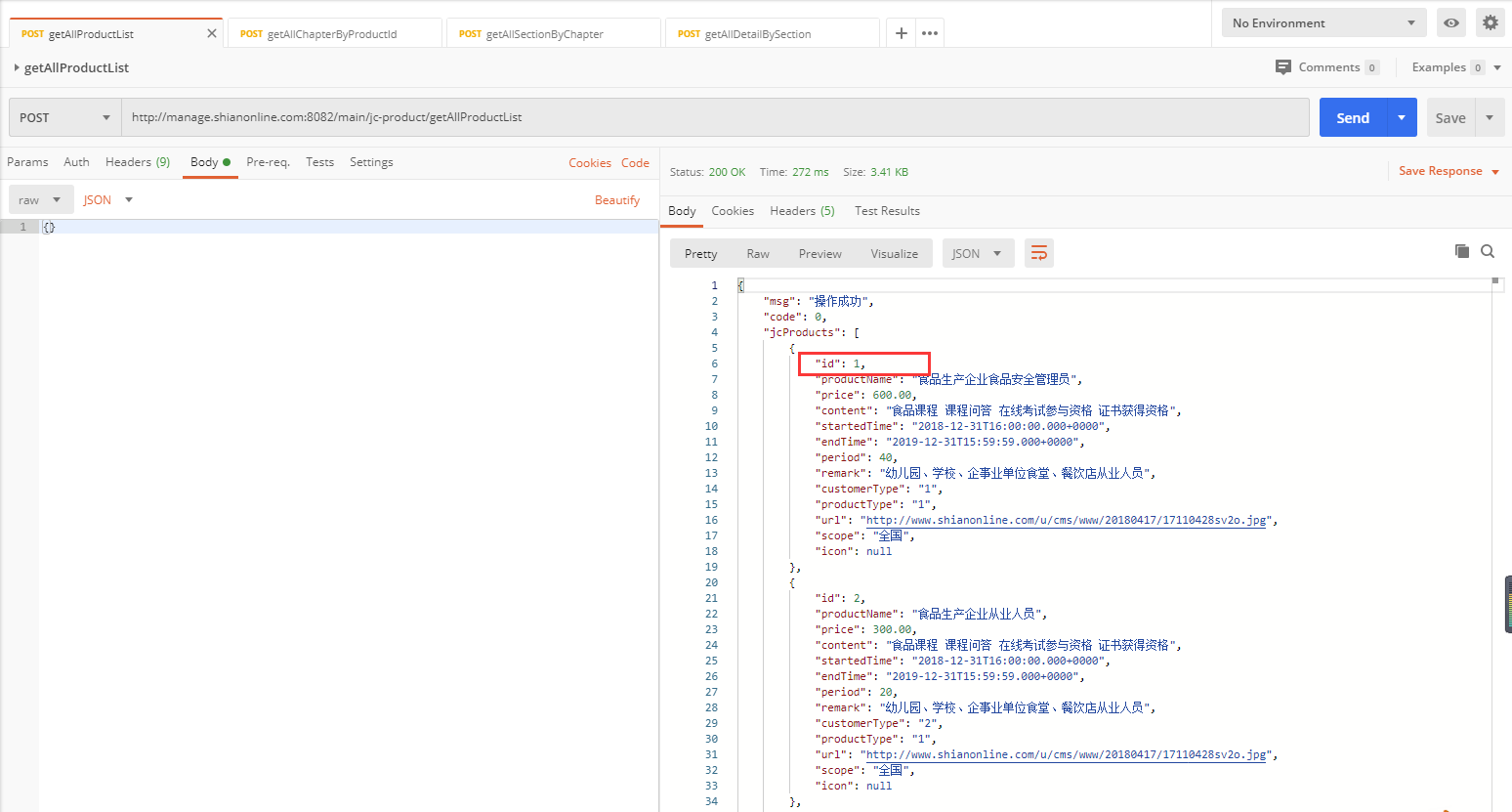
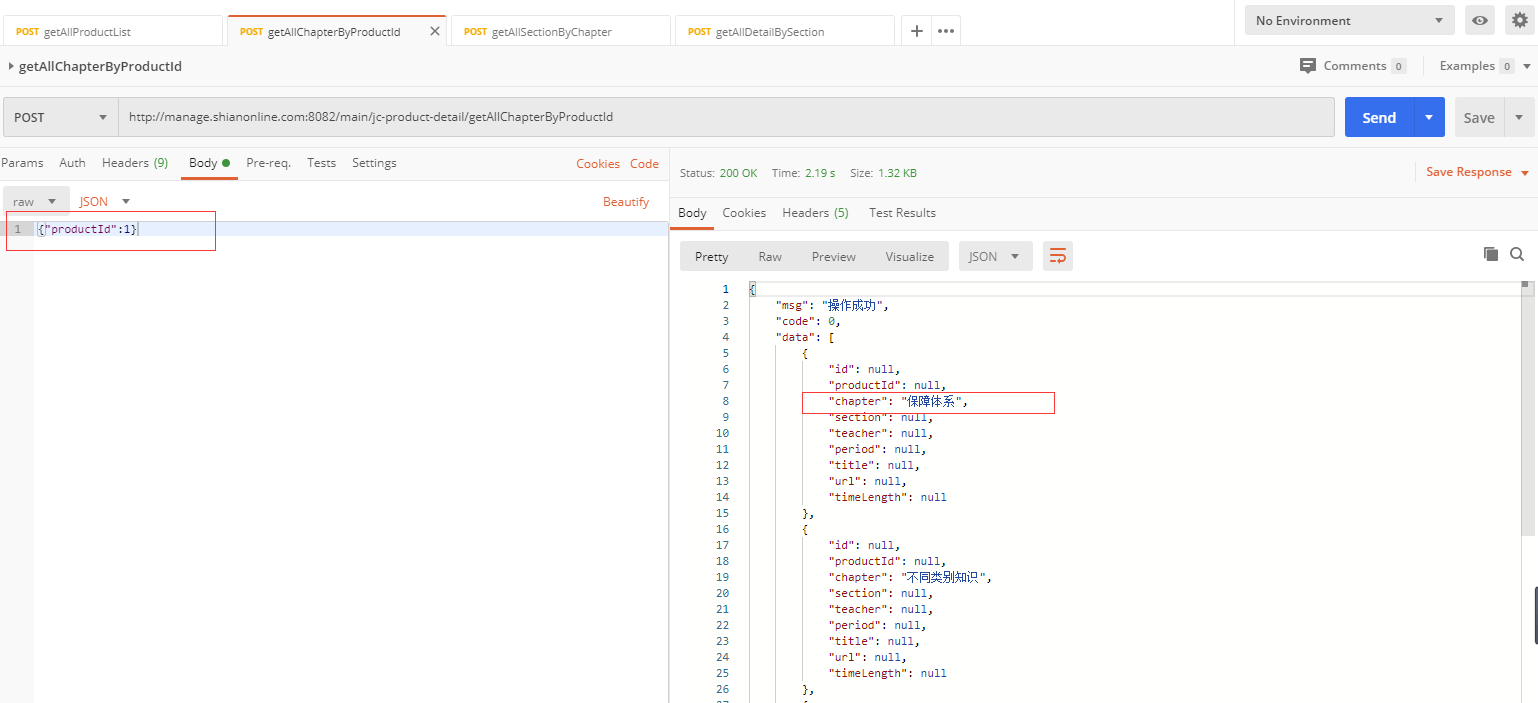
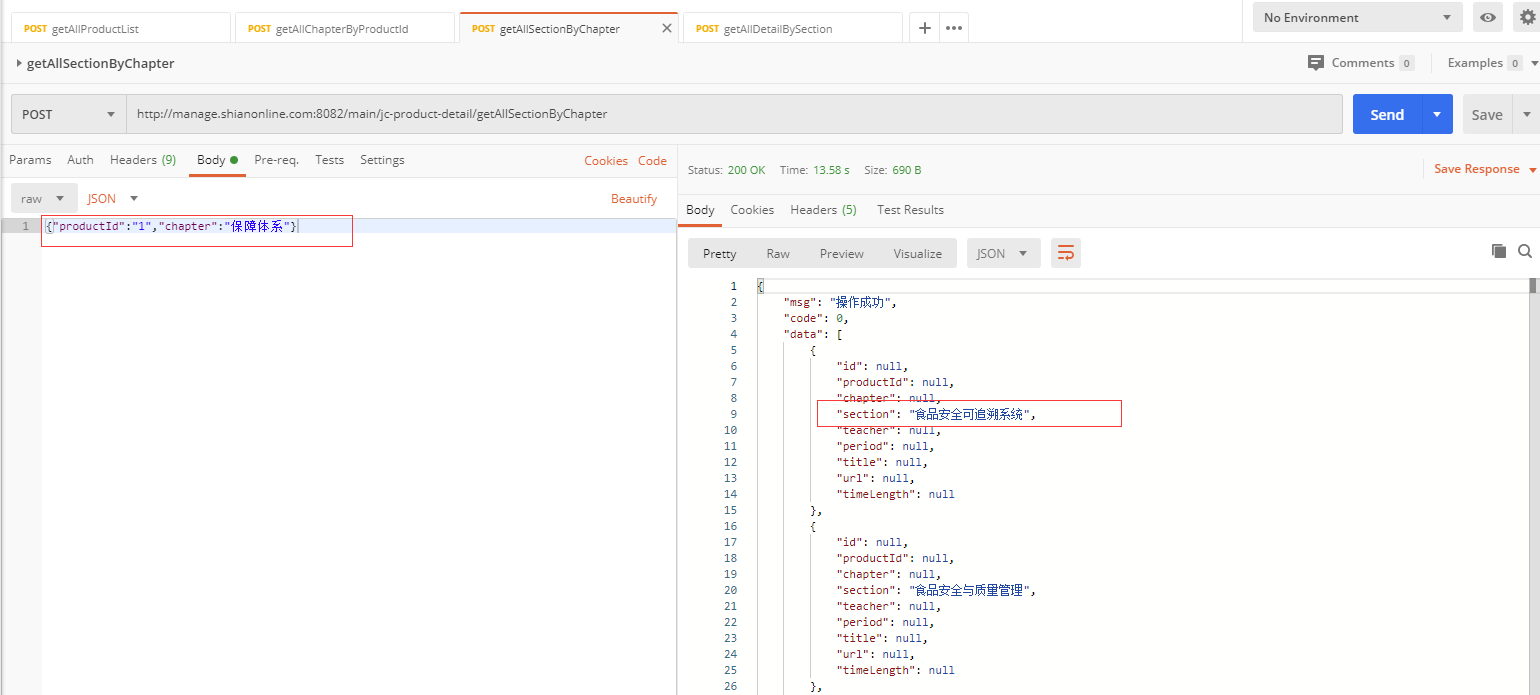
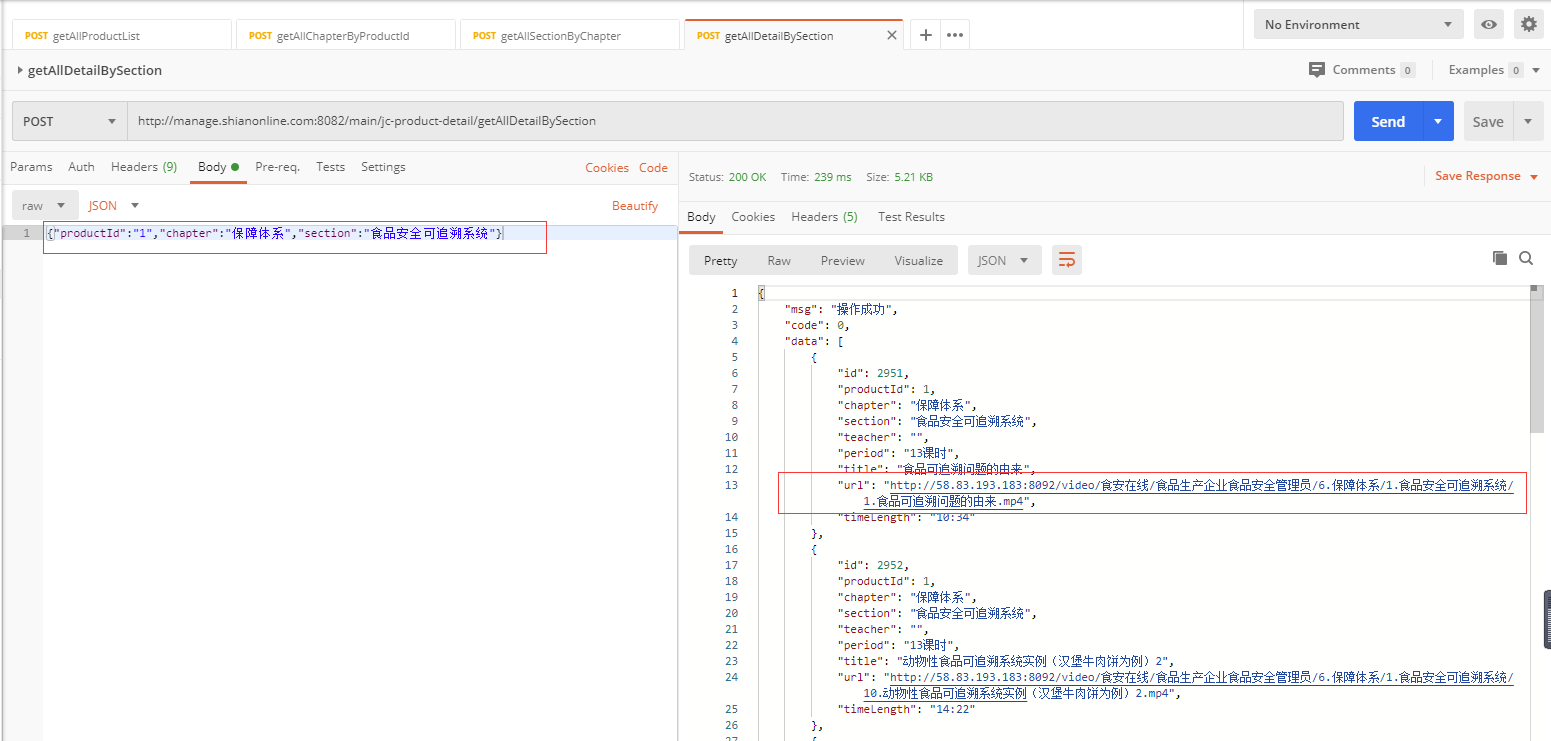
可以看到,第一个接口是获取产品列表,第二个接口是获取章节列表,第三个接口是获取课程列表,第四个接口是获取课程详情,课程详情中包括了课程的视频地址。
通过分析可知,每一个接口都依赖于前一个接口获取到的部分数据。请求方式均为POST,数据以application/json格式传递。
创建scrapy项目
scrapy startproject shianonline
cd shianonline
scrapy genspider videos manage.shianonline.com:8082/main/jc-product/getAllProductList
我们的目的,是提取最后一个接口中的视频资源地址,并保存到txt文件中,每个地址存一行。
编写Items和Pipline
对于items.py,我们只需要添加一个url就行了,用于存取抓取的视频地址:
import scrapy
class ShianonlineItem(scrapy.Item):
url = scrapy.Field()
对于Pipline,我们将抓取的url写入文件即可:
class ShianonlinePipeline(object):
def __init__(self):
with open('videos.txt', 'w', encoding="utf-8") as f:
f.write("")
def process_item(self, item, spider):
url = item['url']
with open('videos.txt', 'a', encoding="utf-8") as f:
f.write("{}\n".format(url))
return item
很简单的代码,没什么好说的
爬取数据
根据上面的分析,我们很容易写出爬取主体数据的代码:
# -*- coding: utf-8 -*-
import scrapy
import json
from shianonline.items import ShianonlineItem
class FullSpider(scrapy.Spider):
name = 'full'
def start_requests(self):
url = 'http://manage.shianonline.com:8082/main/jc-product/getAllProductList/'
yield scrapy.FormRequest(url, method='POST',
callback=self.parse,
headers={'content-type':'application/json'},
body=json.dumps({}))
def parse(self, response):
res = json.loads(response.body.decode())
datas = res['jcProducts']
for item in datas:
url = "http://manage.shianonline.com:8082/main/jc-product-detail/getAllChapterByProductId"
data = {"productId": item['id']}
meta = {"productId": item['id'], "productName": item['productName']}
yield scrapy.FormRequest(url, method='POST',
callback=self.getChapters,
meta=meta,
headers={'content-type': 'application/json'},
body=json.dumps(data))
def getChapters(self, response):
productId = response.meta['productId']
productName = response.meta['productName']
res = json.loads(response.body.decode())
datas = res['data']
for item in datas:
url = "http://manage.shianonline.com:8082/main/jc-product-detail/getAllSectionByChapter"
data = {"productId": productId, "chapter": item['chapter']}
meta = {"productId": productId, "chapter": item['chapter'], "productName": productName}
yield scrapy.FormRequest(url, method='POST',
callback=self.getSections,
meta=meta,
headers={'content-type': 'application/json'},
body=json.dumps(data))
def getSections(self, response):
productId = response.meta['productId']
productName = response.meta['productName']
chapter = response.meta['chapter']
res = json.loads(response.body.decode())
datas = res['data']
for item in datas:
url = "http://manage.shianonline.com:8082/main/jc-product-detail/getAllDetailBySection"
data = {"productId": productId, "chapter": chapter, "section": item['section']}
meta = {"productId": productId, "chapter": chapter, "section": item['section'], "productName": productName}
yield scrapy.FormRequest(url, method='POST',
callback=self.getContent,
meta=meta,
headers={'content-type': 'application/json'},
body=json.dumps(data))
def getContent(self, response):
res = json.loads(response.body.decode())
datas = res['data']
print(datas)
item = ShianonlineItem()
with open('videos.txt', 'a', encoding="utf-8") as f:
for data in datas:
item['url'] = data['url']
yield item
全部都是常规操作,需要说明的一点是,这里使用的是POST请求,所以需要用到:
scrapy.FormRequest(url, method='POST',
callback=self.getChapters,
meta=meta,
headers={'content-type': 'application/json'},
body=json.dumps(data))
注意设置请求头、而且参数传递使用的是body,往下一个callback回调传递的参数放于meta之中。
运行爬虫:
scrapy crawl full
这里一口气把所有的接口全部访问了,提取出了所有的视频地址,并保存到了文件videos.txt:

若有收获,就点个赞吧
0 人点赞
