方法一:通过命令行方式下载
首先看原理:其实迅雷是可以通过命令行直接调用执行下载操作的:
E:\>"C:\Program Files (x86)\Thunder Network\Thunder\Program\Thunder.exe" "http://58.83.123.183/video/内容简介.mp4"
可以看出,在迅雷的exe路径后直接接上下载链接即可执行下载。
OK,知道原理后,直接通过python的os.system调用系统命令即可:
import osurl = "http://58.83.123.183/video/内容简介.mp4"os.system(r'"C:\Program Files (x86)\Thunder Network\Thunder\Program\Thunder.exe" {url}'.format(url=url))
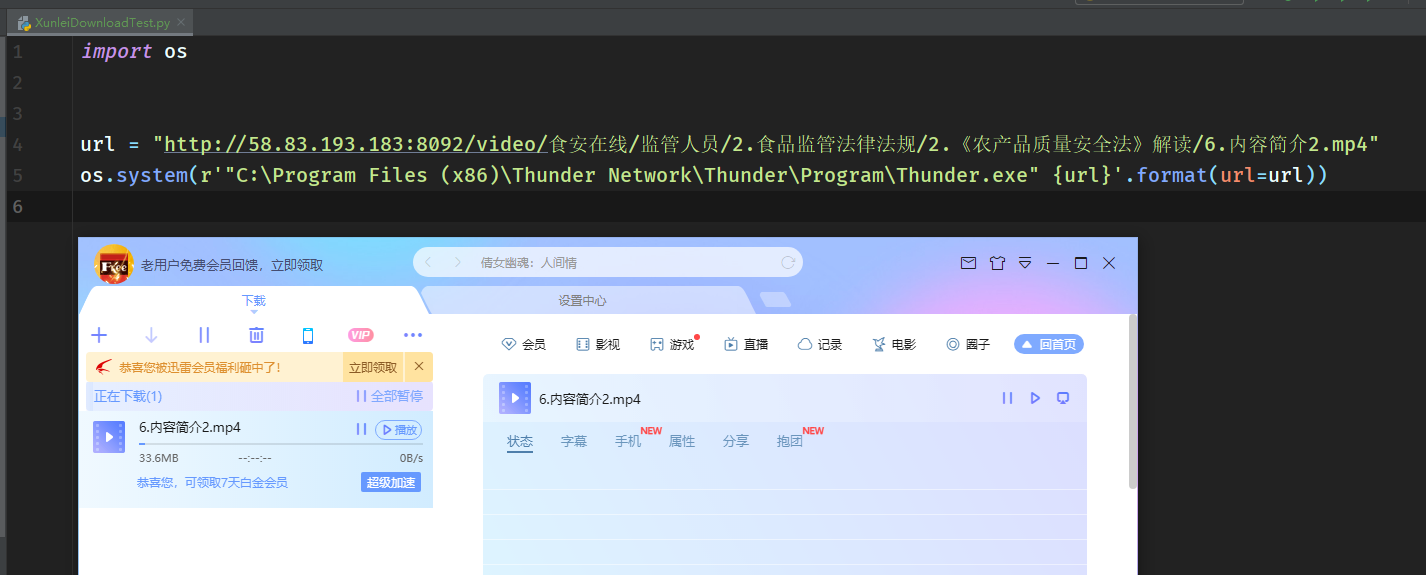
注意,下载时需要设置为静默下载,否则每次执行后会弹出下载确认框: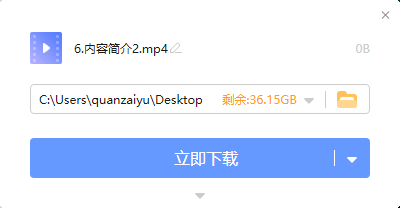
在配置中勾选“一键下载”即可实现静默下载: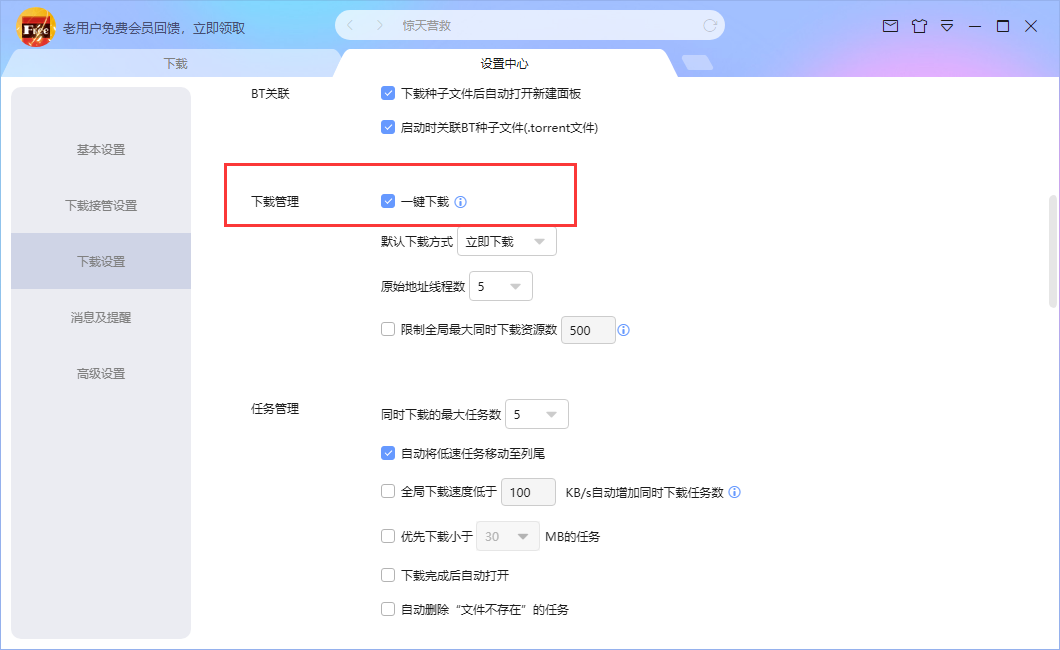
检测任务是否开始
原理是:迅雷下载过程中会创建一个同名的xltd文件,我们判断此文件是否存在即可。
import osdef check_start(filename):cache_file = filename+".xltd"return os.path.exists(os.path.join(save_path,cache_file))
其中save_path就是你设置的迅雷下载地址。
检测任务是否完成
原理是:迅雷下载完毕,xltd文件将被更名为下载的文件名,我们判断此文件是否存在即可
import osdef check_end(fiename):return os.path.exists(os.path.join(save_path,fiename))
完整程序
好了,既然任务开始和结束都已经可以实现监控了,我们将上面的逻辑组装一下:
import osimport timesave_path = "F:\迅雷下载"# 检查下载是否开始def check_start(filename):cache_file = filename + ".xltd"return os.path.exists(os.path.join(save_path, cache_file))# 检查下载是否结束def check_end(filename):return os.path.exists(os.path.join(save_path, filename))# 获取文件名def get_filename(url):return os.path.split(url)[1]# 开始下载def download(url):# 获取文件名filename = get_filename(url)# 判断文件是否已经存在if check_end(filename):print("【{}】 已经存在,不需要重复下载".format(filename))return True"""下载资源返回True表示下载完成 否则失败"""os.system(r'"C:\Program Files (x86)\Thunder Network\Thunder\Program\Thunder.exe" {url}'.format(url=url))# 一定要休眠一段时间,执行命令后要等一会儿迅雷才会新建任务,# 然后还要寻找资源,这都需要时间,大概多久,自己去测试,根据网络、资源不同,寻找资源的速度也不同# 如果没启动迅雷,迅雷还会启动一会儿time.sleep(20)print("正在下载 【{}】".format(filename))# 检测任务是否已开始# 有时候会因为资源不存在,或者迅雷该死的版权问题会下载失败if check_start(filename):while True:# 每分钟检测一次是否下载完成time.sleep(1)if check_end(filename):return Trueelse:return Falsedef main():# 获取所有资源链接urls = ["http://58.83.123.183/video/内容简介.mp4"]# 开始循环下载for url in urls:if download(url):print("======下载完成======")else:print("=======下载失败=====")if __name__ == '__main__':print("=======电影自动下载程序启动=========")main()
上面的程序没有使用scrapy,下载链接列表是写死的,当然依葫芦画瓢,将下载链接来源变为使用scrapy爬取的链接即可。
方法二:通过代理方式下载
先上核心代码:
from win32com.client import Dispatchurl = "http://58.83.123.183/video/内容简介.mp4"filename = "test.mp4"thunder = Dispatch('ThunderAgent.Agent64.1')thunder.AddTask(url, filename)thunder.CommitTasks()
其中,第一行是所需的模块,然后是调度迅雷的代理。这里如果是迅雷9或10的用户,直接使用 ThunderAgent.Agent64.1 就行,其他版本可以尝试 ThunderAgent.Agent.1 。
AddTask 就是这次的主角。费尽千辛万苦也没有找到关于这个函数的说明。在另一篇博文里有提到如下用法:
AddTask("下载地址", "另存为文件名", "保存目录", "任务注释", "引用地址", "开始模式", "只从原始地址下载", "从原始地址下载线程数")
经过测试,第三个参数,也就是 “保存目录” 并不能起到作用。如果你在迅雷的设置中勾选了“自动修改为上次使用的目录”,那么不管这个参数是什么,最终都会下载到上次的下载目标路径;而如果你没有勾选,那么最终会下载到指定的迅雷下载目录。
如果实在是需要将不同的文件下载到特定的目录里,也不是一件难事,只需要用到python的os模块和shutil模块。
首先,在迅雷的设置中将默认的下载目录修改为一个空目录,目的是尽量不要让别的文件影响你的检索。
然后使用os模块定时检索这个目录。定时的功能可以通过新开一个线程,线程里加入一个死循环,每次循环结束等待10分钟(根据个人需要)来实现。如果检索到了你需要的文件,比如以“.mp4”结尾的视频文件,就用shutil模块将其移动到目标路径下即可。
import osimport shutilimport timedef moveVideo(downloadRoot, mediaRoot):# downloadRoot: 迅雷的默认下载目录(例:"D:\\download\\")# mediaRoot: 我希望存储的目标路径(例:"D:\\video\\")while True:files = os.listdir(downloadRoot)for file in files:# 找到视频文件# 在添加下载任务的时候,我将“另存为文件名”这一参数设置成了“n_***.mp4”,n是之后要存放的文件夹名if file.endswith('.mp4'):# 获取该视频文件的完整路径("D:\\download\\n_***.mp4")srcPath = downloadRoot + file# 获取转移路径("D:\\video\\n")videoRoot = mediaRoot + file.split('_')[0]# 如果没有这个目录就建立if not os.path.exists(videoRoot):os.mkdir(videoRoot)# 获取转移后的完整路径("D:\\video\\***.mp4")dstPath = videoRoot + '\\' + file.split('_')[1]# 转移shutil.move(srcPath, dstPath)time.sleep(600)
如此就实现了利用python调用迅雷实现批量下载。
参考资料

若有收获,就点个赞吧
0 人点赞
