1.结构
- 以识别手写数字为例,有些地方是简化版
这个图是图片数据的特征维度经过一层一层的变化。
这个图是每一层的核的size,包括输入输出通道的个数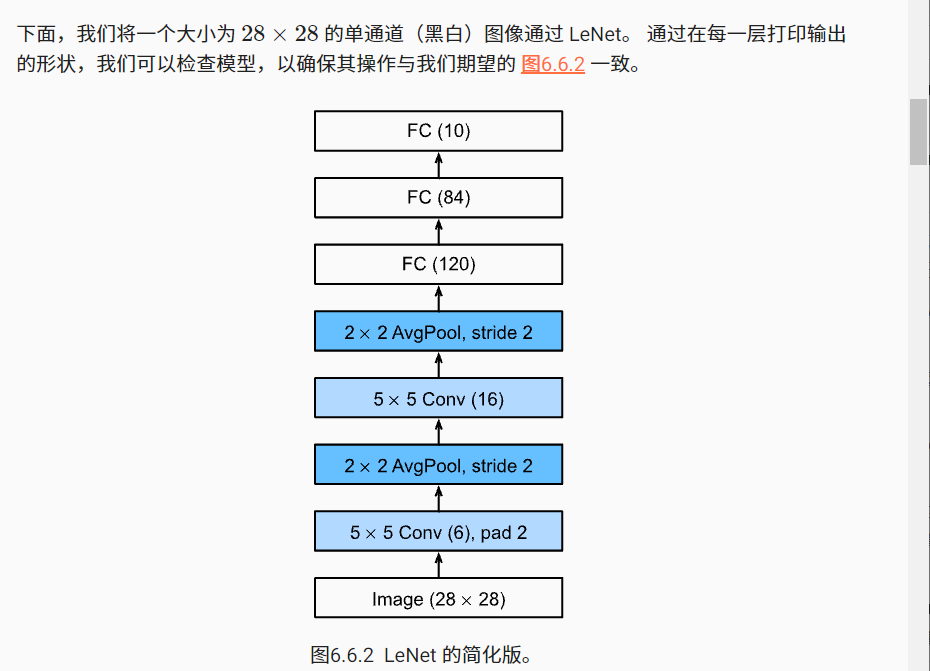
- 第一卷积层,卷积核的size(5 * 5)
输入通道:1
输出通道:6
- 第一层池化层,核的size(2 * 2)
(经过池化层,输入输出通道数没改变)
- 第二卷积层 ,卷积核的size(5 * 5)
输入通道:6
输出通道:16
- 第二层池化层,核的size(2 * 2)
图片数据的特征维度变化:
(2828)——>6(1414)——>6(1010)——>16(55)——>165*5——>84——>10
参数:
class Reshape(torch.nn.Module):def forward(self,x):#为什么用view???return x.view(-1,1,28,28)net=torch.nn.Sequential(Reshape(),#1:输入通道数 6:输出通道数nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),#为什么输出后特征维度变成16*10*10nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),#????flatten()全部展平???nn.Flatten(),#第一个参数:输入特征维度,,,第二个参数:输出特征维度nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))
#1,1分别代表?#打印每个层的结构X=torch.randn(size=(1,1,28,28),dtype=torch.float32)for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)
batch_size = 128train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
#在模型使用 GPU 计算数据集之前,我们需要将其复制到显卡def evaluate_accuracy_gpu(net,data_iter,device=None):"""使用gpu"""if isinstance(net,torch.nn.Module):net.eval()if not device:device=next(iter(net.parameters())).devicemetric=d2l.Accumulator(2)for X,y in data_iter:if isinstance(X,list):X=[x.to(device) for x in X]else:X=X.to(device)y=y.to(device)metric.add(d2l.accuracy(net(X),y),y.numel())return metric[0]/metric[1]
#训练数据def train_ch6(net,train_iter,test_iter,num_epochs,lr,device):def init_weights(m):if type(m)==nn.Linear or type(m)==nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on',device)net.to(device)optimizer=torch.optim.SGD(net.parameters(),lr=lr)loss=nn.CrossEntropyLoss()animator=d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],legend=['train loss','train acc','test acc'])timer,num_batches=d2l.Timer()for epoch in range(num_epochs):# 训练损失之和,训练准确率之和,范例数metric=d2l.Accumulator(3)net.train()for i,(X,y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X,y=X.to(device),y.to(device)y_hat=net(X)l=loss(y_hat,y)l.backward()optimizer.step()with torch.no_grad():metric.add(l*X.shape[0],d2l.accuracy(y_hat,y),X.shape[0])timer.stop()train_l=metric[0]/metric[1]train_acc=metric[1]/metric[2]if (i+1)%(num_batches//5)==0 or i==num_batches-1:animator.add(epoch+(i+1)/num_batches,(train_l,train_acc,None))test_acc=evaluate_accuracy_gpu(net,test_iter)animator.add(epoch+1,(None,None,test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
lr, num_epochs = 0.9, 10train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

若有收获,就点个赞吧
0 人点赞
