
本质上来看,就是要关注想关注的,而非全部关注。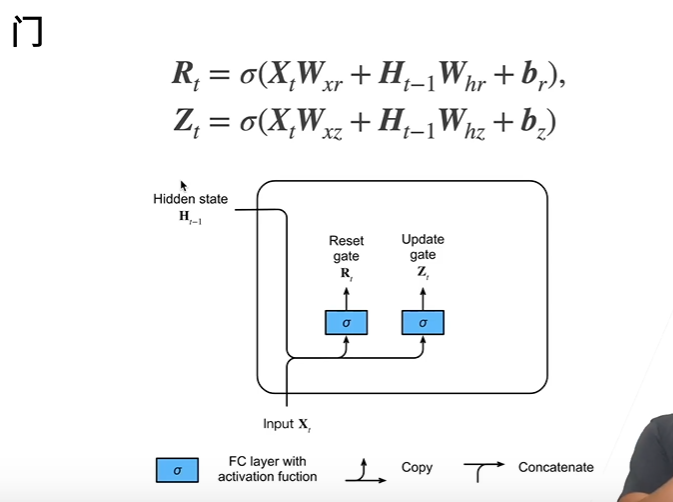
对于RNN,R(t)与Z(t) 与之前计算H(t)隐变量一样,也等价于一个全连接层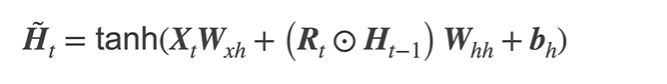
候选隐状态:
按元素做乘法。
R(t)是经过sigmoid处理后的值,取值为(0,1),假设它结果接近于0,说明在忘记上一个隐藏状态h(t-1)
假设它结果接近于1,与RNN类似。但r(t)是不断在学习的,一直在0~1徘徊,是一个软的控制门。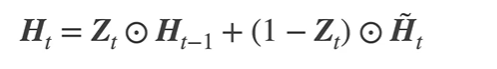
隐状态:
假设Z(t)结果接近于1,说明不更新过去的状态,不要X(t)了,直接把过去的状态拿来用
假设Z(t)结果接近于0,又重新等价于RNN了,只看现在的状态。
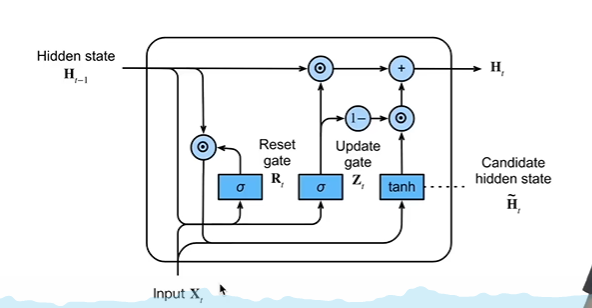
核心思想:1)两个极端情况,要不不看前面的h(t-1)信息,要么全看。

若有收获,就点个赞吧
0 人点赞
