我们创建一个 pod 时,可以指定容器对 CPU 和内存的资源请求量(即 requests),以及资源限制量(即 limits)。 针对每个容器单独指定。 pod 对资源的请求量和限制量是它所包含的所有容器的请求量和限制量之和。
创建包含资源 requests 的 pod
cat > requests-pod.yaml << EOFapiVersion: v1kind: Podmetadata:name: requests-podnamespace: defaultspec:containers:- name: busyboximage: busybox:1.28.4command:- "dd"- "if=/dev/zero"- "of=/dev/null"imagePullPolicy: IfNotPresentresources:requests:cpu: 200mmemory: 10MiEOF
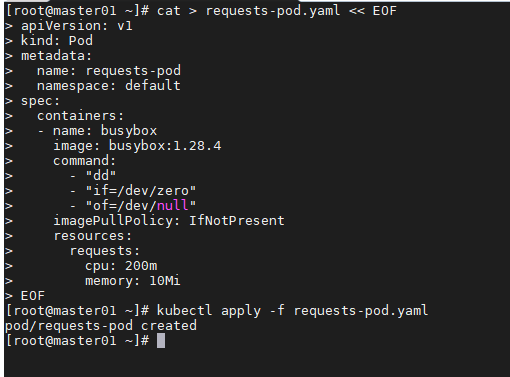
kubectl exec -it requests-pod sh
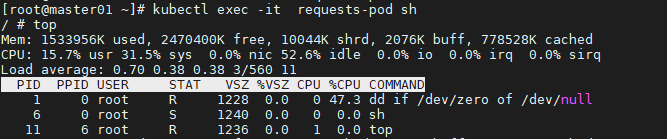
容器实际使用量超过了我们在 pod 定义中申请的 200 毫核。 这是符合预期的,因为 requests 不会限制容器可以使用的 CPU 数量。一般建议requests和limits一起用
调度器如何判断一个 pod 是否适合调度到某个节点
调度器在调度时并不关注各类资源在当前时刻的实际使用量,而只关心节点上部署的所有 pod 的资源申请量之和。尽管现有 pods 的资源实际使用量可能小于它的申请量,但如果使用基于实际资源消耗量的调度算法将打破系统为这些己部署成功的 pods 提供足够资源的保证。
节点上部署了三个 pod。 它们共申请了节点 80%的 CPU 和 60% 的内存资源。但是 pod D 将无法调度到这个节点上,因为它 25% 的 CPU requests 大于节点未分配的 20%CPU。 而实际上,这与当前三个 pods 仅使用 70% 的 CPU没有什么关系。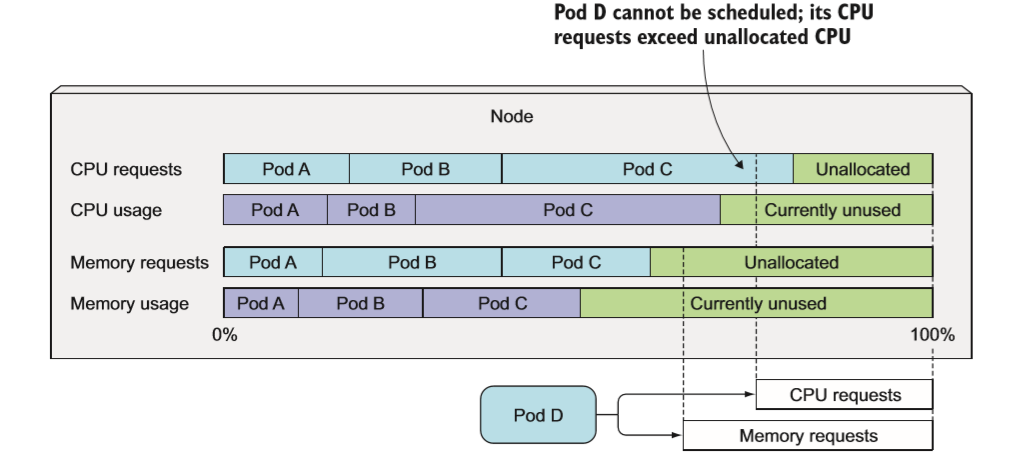
调度器首先会对节点列表进行过滤,排除那些不满足需求的节点,然后根据预先配置的优先级函数对其余节点进行排序。 其中有两个基于资源请求量的优先级排序函数: LeastRequestedPriority 和 MostRequestedPriority。前者优先将 pod 调度到请求量少的节点上(也就是拥有更多未分配资源的节点),而后者相反,优先调度到请求量多的节点(拥有更少未分配资源的节点)。
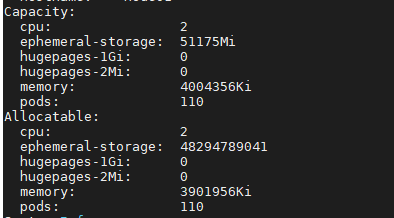
查看节点资源总量
kubectl describe nodes
创建一个带有资源 limits 的 pod
如果不对内存进行限制, 工作节点上的容器(或者 pod)可能会吃掉所有可用内存,会对该节点上所有其他 pod 和任何新调度上来的 pod (记住新调度的 pod 是 基于内存的申请量而不是实际使用量的)造成影响。单个故障 pod 或恶意 pod 几乎可以导致整个节点不可用。为了防止这种情况发生, Kubemetes 允许用户为每个容器指定资源 limits (与设 置资源 requests 几乎相同 )。
只要单个容器尝试使用比自己指定的 limits 更多的资源时也可能会被杀掉。
cat > limits-pod.yaml << EOFapiVersion: v1kind: Podmetadata:name: limits-podnamespace: defaultspec:containers:- name: busyboximage: busybox:1.28.4command:- "dd"- "if=/dev/zero"- "of=/dev/null"imagePullPolicy: IfNotPresentresources:requests:cpu: 200mmemory: 10Milimits:cpu: 400mmemory: 100MiEOF
了解pod QoS等级
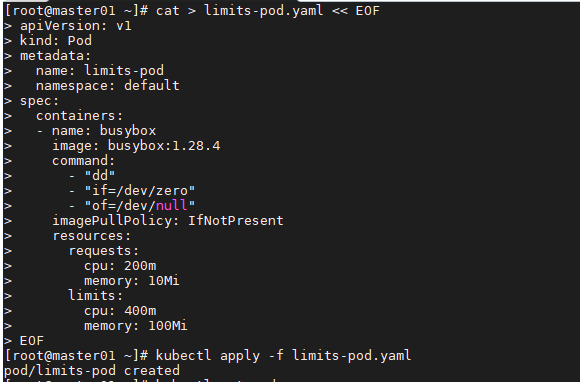
Kubernetes 将 pod 划分为 3 种 QoS 等级 :
- BestEffort (优先级最低)
- Burstable
- Guaranteed (优先级最高)
最低优先级的 QoS 等级是 BestEffort 。 会分配给那些没有(为任何容器) 设置任何 requests 和 limits 的 pod。在这个等级运行的容器没有任何资源保证。 在最坏情况下,它们分不到任何 CPU 时间,同时在需要为其他 pod 释放内存时, 这些容器会第一批被杀死。 不过因为 BestEffort pod 没有配置内存 limits, 当有充足的可用内存时,这些容器可以使用任意多的内存。
Guaranteed 级别的 pod,有以下几个条件:
- CPU 和内存都要设置 requests 和 limits
- 每个容器都需要设置资源量
- 它们必须相等(每个容器的每种资源的 requests 和 limits 必须相等)
Burstable QoS 等级介于 BestEffort 和 Guaranteed 之间。其他所有 的 pod 都属于这个等级。 包括容器的requests 和 limits 不相同的单容器 pod,至少有 一个容器只定义了 requests 但没有定义 limits 的 pod,以及一个容器的 requests,limits 相等,但是另一个容器不指定 requests 或 limits 的 pod。
内存不足时哪个进程会被杀死
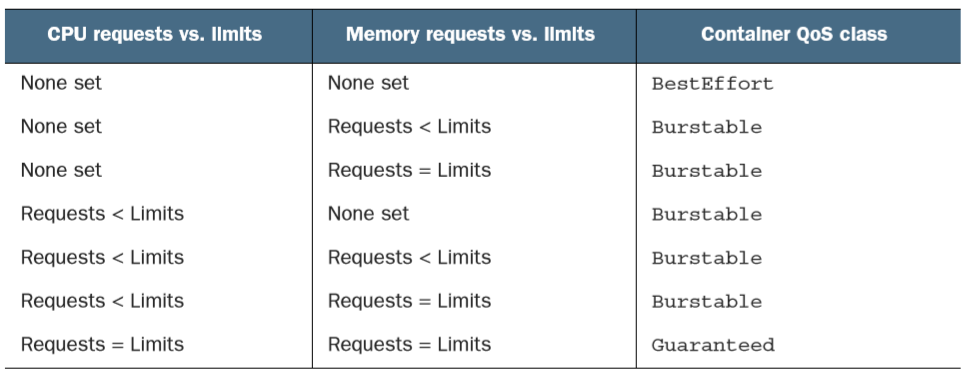
QoS 等级决定着哪个容器第一个被杀掉,这样释放出的资源可以提供给高优先级的 pod 使用 。 BestEffort 等级的 pod 首先被杀掉,其次是 Burstable pod,最后是 Guaranteed pod,Guaranteed pod 只有在系统进程需要内存时才会被杀掉。
为命名空间中的pod设置默认的requests和limits
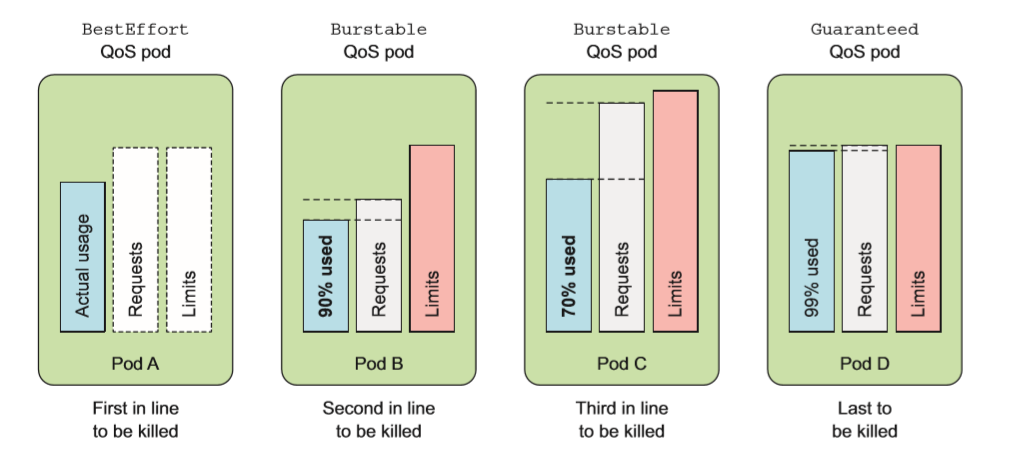
用户可以通过创建一个 LimitRange 资源来避免必须配置每个容器。 LimitRange 资源不仅允许用户(为每个命名空间〉指定能给容器配置的每种资源的最小和最大限额,还支持在没有显式指定资源 requests 时为容器设置默认值。
cat > LimitRange.yaml << EOFapiVersion: v1kind: LimitRangemetadata:name: examplenamespace: defaultspec:limits:- type: Podmin:cpu: 50mmemory: 5Mimax:cpu: 1memory: 1Gi- type: ContainerdefaultRequest:cpu: 100mmemory: 10Midefault:cpu: 200mmemory: 100Mimin:cpu: 50mmemory: 5Mimax:cpu: 1memory: 1GimaxLimitRequestRatio:cpu: 4memory: 10- type: PersistentVolumeClaimmin:storage: 1Gimax:storage: 10GiEOF
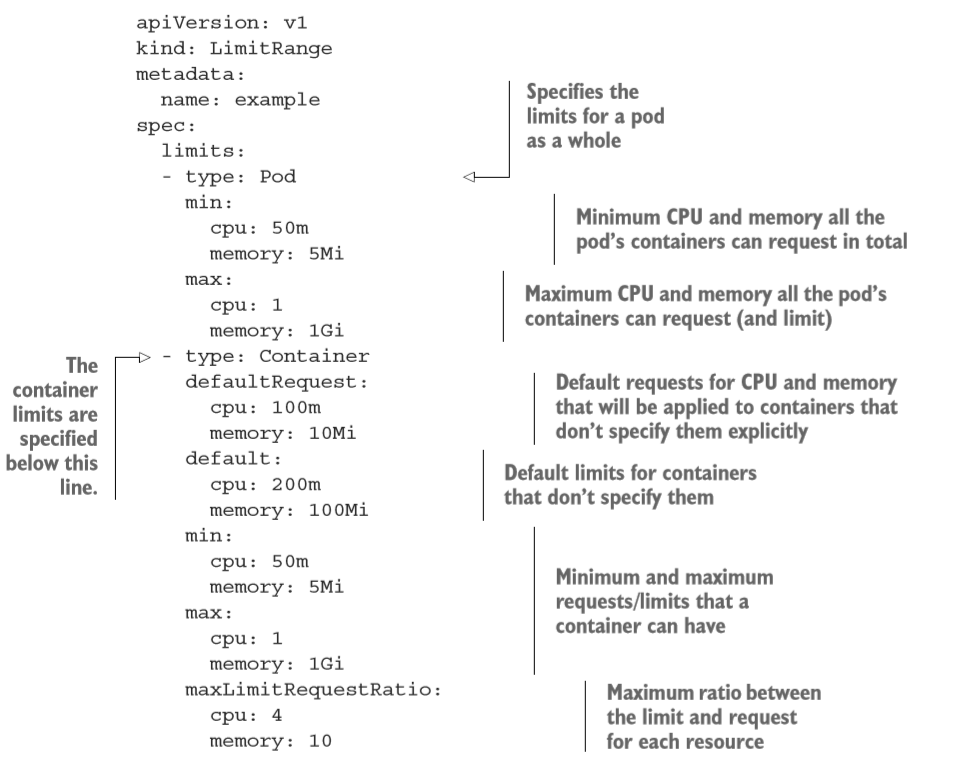
正如在上面例子中看到的,整个 pod 资源限制的最小值和最大值是可以配置的。 它应用于 pod 内所有容器的 requests 和 limits 之和。
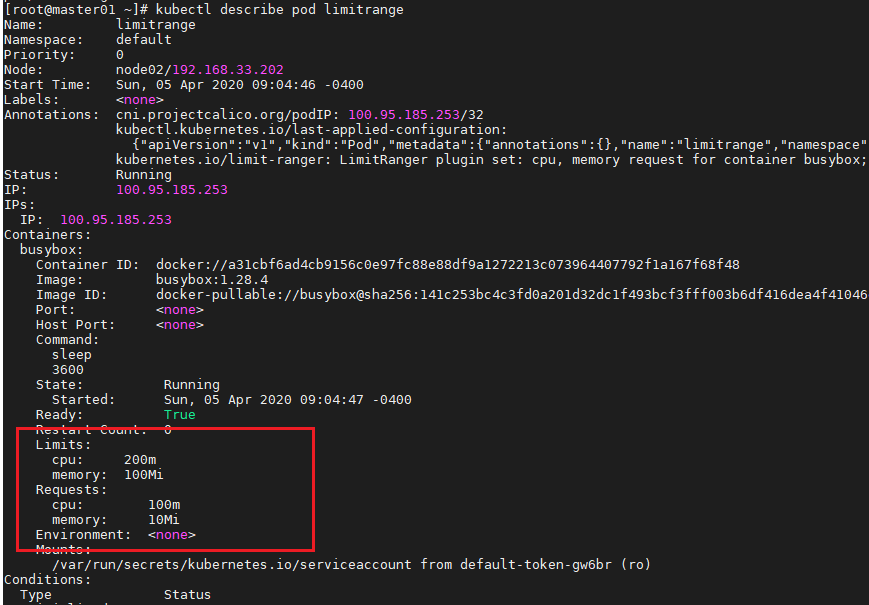
在更低一层的容器级别,用户不仅可以设置最小值和最大值, 还可以为没有显 式指定的容器设置资源 requests (defaul tRequest)和 limits (default)的默认值。
除了最小值、最大值和默认值,用户甚至可以设置 limits 和 requests 的最大比例。 上面示例中设置了 maxLimitRequestRat工O 为 4,表示容器的 CPU limits 不能超 过 CPU requests 的 4 倍。 因此, 对于一个申请了 200 毫核的容器,如果它的 CPU 限 额设置为 801 毫核或者更大就无法创建。 而对于内存,这个比例设为了10。
kubectl get limitranges
由于 LimitRange 对象中配置的校验(和默认值信息在 API 服务器接收到新的 pod 或 PVC 创建请求时执行,如果之后修改了限制,己经存在的 pod 和 PVC 将不会再次进行校验,新的限制只会应用于之后创建的 pod 和 PVC。
再看看如果不指定资源 requests 和 limits, Kubemetes 是否设置默认值
cat<<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: limitrange
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28.4
command:
- sleep
- "3600"
imagePullPolicy: IfNotPresent
restartPolicy: Always
EOF
限制命名空间中的可用资源总量
LimitRange 只应用于单独的 pod,而我们同时也需要一种手段可以限制命名空间中的可用资源总量。这通过创建一个ResourceQuota对象来实现。需要注意的一点是,创建 ResourceQuota 时往往还需要先创建LimitRange 对象。
为 CPU 和内存创建 ResourceQuota
cat > ResourceQuota.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-mem
namespace: default
spec:
hard:
requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 1
limits.memory: 1Gi
EOF
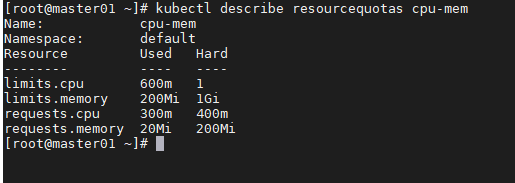
这个 ResourceQuota 设置了命名空间中所有 pod 最多可申请的 CPU 数量为 400 毫核, limits 最大总量为1核。对于内存,设置所有 requests 最大总量为 200MiB, limits 为 1GiB。 LimitRange 应用于单独的 pod,ResourceQuota 应用于命名空间中所有的 pod
kubectl describe resourcequotas cpu-mem
为持久化存储指定配额
cat > storage.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
namespace: default
spec:
hard:
requests.storage: 500Gi
ssd.storageclass.storage.k8s.io/requests.storage: 300Gi
standard.storageclass.storage.k8s.io/requests.storage: 300Gi
EOF
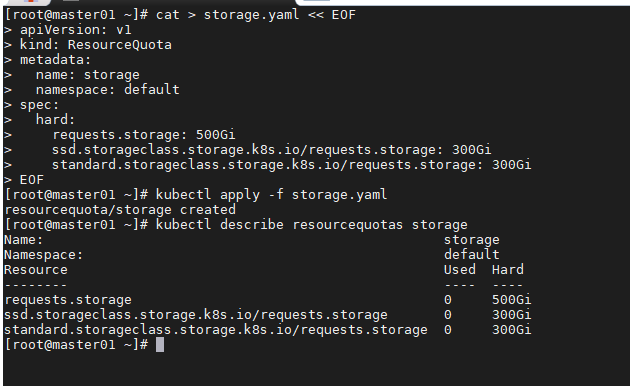
Namespace中所有可申请的 PVC 总量被限制为 500GiB (通过 配额对象中的 requests.storage)。 上面的示例限制了可声明的 SSD 存储(以 ssd 命名的 StorageClass)的总量为 300GiB。 低性能的 standard 存储 (StorageClass standrad) 限制为 1TiB。
限制可创建对象的个数
cat > objects.yaml << EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
namespace: default
spec:
hard:
pods: 100
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 4
services: 5
services.loadbalancers: 1
services.nodeports: 2
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2
EOF
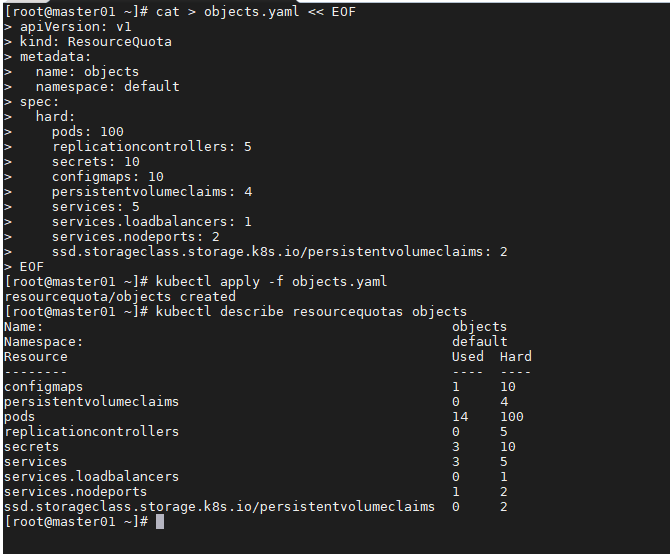
上面的例子允许用户在一个命名空间中最多创建 100个 pod,无论是于动创建还是通过 ReplicationController、 ReplicaSet、 DaemonSet 或者 Job 创建的。 同时限制了 ReplicationController 最大个数为 5, Service 最大个数为 5,其中 LoadBalancer 类型 最多 1 个, NodePort 类型最多 2 个。 与通过指定每个StorageClass来限制存储资源的申请总量类似, PVC 的个数同样可以按照 StorageClass 来限制。
对象个数配额目前可以为以下对象配置 :
- pod
- ReplicationController
- Secret
- ConfigMap
- Persistent Volume Claim
- Service

若有收获,就点个赞吧
0 人点赞
