了解架构
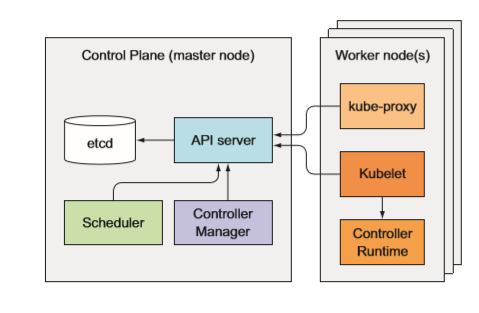
master组件
控制平面负责控制并使得整个集群正常运转。控制平面包含如下组件 :
- etcd 分布式持久化存储
- API 服务器 ·
- 调度器
- 控制器管理器
node组件
运行容器的任务依赖于每个工作节点上运行的组件 :
- Kubelet
- Kubelet 服务代理(kube-proxy)
-
附加组件
除了控制平面(和运行在节点上的组件,还要有几个附加组件,这样才能提供 所有之前讨论的功能。 包含 :
Kubemetes DNS 服务器
- 仪表板
- Ingress 控制器
- 容器集群监控
- 容器网络接口插件
了解 etcd
创建的所有对象——pod、 ReplicationController、服务和私密凭据等, 需要以持久化方式存储到某个地方,这样它们的 manifest 在 API 服务器重启和失败 的时候才不会丢失。 为此, Kubemetes 使用了 etcd。 etcd 是一个响应快、分布式、一致的 key-value 存储。因为它是分布式的,故可以运行多个 etcd 实例来获取高可 用性和更好的性能。
Kubemetes 存储所有数据到 etcd 的 registry下
ETCDCTL_API=3 etcdctl --endpoints="https://192.168.33.101:2379,https://192.168.33.102:2379,https://192.168.33.103:2379" --cert=/etc/kubernetes/pki/etcd/server.crt --key=/etc/kubernetes/pki/etcd/server.key --cacert=/etc/kubernetes/pki/etcd/ca.crt get /registry --prefix --keys-only
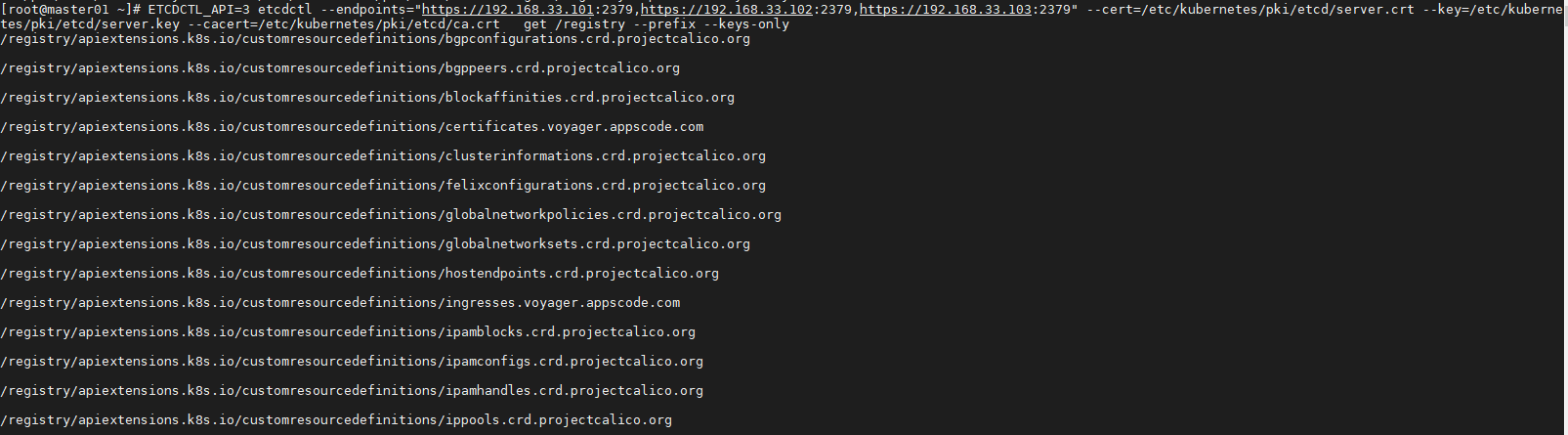
每个条目对应一个单独的 pod。 这些不是目录,而是键值对。
etcd 通常部署奇数个实例。如果只有两个实例时,要求另一个实例必须在线, 这样才能符合超过半数的数量要求。如果有2个岩机, 那么etcd 集群就不能转换到新状态, 因为没有超过半数。两个实例的情况比一个实例的情况更糟。对 比单节点岩机, 在有两个实例的情况下,整个集群挂掉的概率增加了 100%。 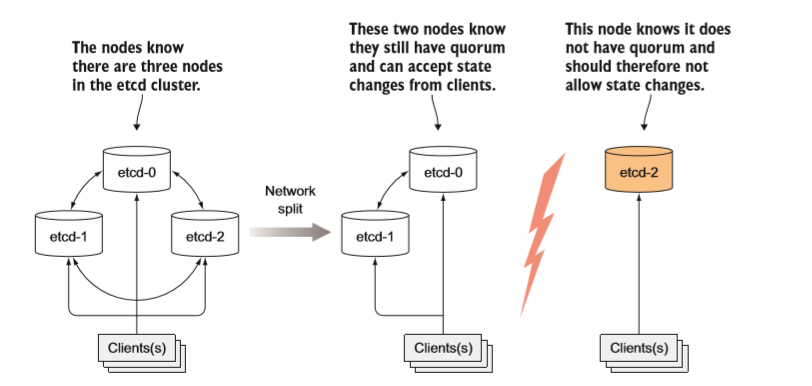
了解调度器
kube-scheduler 是 k8s 系统的核心组件之一,其主要职责就是通过自身的调度算法,为新创建的 Pod 寻找一个最合适的 Node。
主要包含如下几个步骤:
- 通过一组叫做谓词 predicates 的过滤算法,先挑出满足条件的 Node;
- 通过一组叫做优先级 priorities 的打分算法,来给上一步符合条件的每个 Node 进行打分排名;
- 最终选择得分最高的节点,当然如果得分一样就随机一个节点,填回 Pod 的 spec.nodeName 字段。
Predicates
- CheckNodeConditionPred 检查节点是否正常
- GeneralPred HostName(如果pod定义hostname属性,会检查节点是否匹配。pod.spec.hostname)、
- PodFitsHostPorts(检查pod要暴露的hostpors是否被占用。pod.spec.containers.ports.hostPort)
- MatchNodeSelector pod.spec.nodeSelector 看节点标签能否适配pod定义的nodeSelector
- PodFitsResources 判断节点的资源能够满足Pod的定义(如果一个pod定义最少需要2C4G node上的低于此资源的将不被调度。用kubectl describe node NODE名称 可以查看资源使用情况)
- NoDiskConflict 判断pod定义的存储是否在node节点上使用。(默认没有启用)
- PodToleratesNodeTaints 检查pod上Tolerates的能否容忍污点(pod.spec.tolerations)
- CheckNodeLabelPresence 检查节点上的标志是否存在 (默认没有启动)
- CheckServiceAffinity 根据pod所属的service。将相同service上的pod尽量放到同一个节点(默认没有启动)
- CheckVolumeBinding 检查是否可以绑定(默认没有启动)
- NoVolumeZoneConflict 检查是否在一起区域(默认没有启动)
- CheckNodeMemoryPressure 检查内存是否存在压力
- CheckNodeDiskPressure 检查磁盘IO压力是否过大
CheckNodePIDPressure 检查pid资源是否过大
Priorities
least_requested 选择消耗最小的节点(根据空闲比率评估 cpu(总容量-sum(已使用)*10/总容量) )
- balanced_resource_allocation 从节点列表中选出各项资源使用率最均衡的节点(CPU和内存)
- node_prefer_avoid_pods 节点倾向
- taint_toleration 将pod对象的spec.toleration与节点的taints列表项进行匹配度检查,匹配的条目越多,得分越低。
- selector_spreading 与services上其他pod尽量不在同一个节点上,节点上通一个service的pod越少得分越高。
- interpod_affinity 遍历node上的亲和性条目,匹配项越多的得分越高
- most_requested 选择消耗最大的节点上(尽量将一个节点上的资源用完)
- node_label 根据节点标签得分,存在标签既得分,没有标签没得分。标签越多 得分越高。
image_locality 节点上有所需要的镜像既得分,所需镜像越多得分越高。(根据已有镜像体积大小之和)
Scheduler
节点选择器: nodeSelector、nodeName
- 节点亲和性调度: nodeAffinity
- Pod亲和性调度:PodAffinity
- Pod反亲和性调度:PodAntiAffinity
了解控制器
API 服务器只做了存储资源到 etcd 和通知客户端有变更的工作。 调度器则只是给 pod 分配节点,所以需要有活跃的组件确保系统真实状态朝 API 服务器定义的期望的状态收敛。 这个工作由控制器管理器里的控制器来实现。
- Replication 管理器( ReplicationController 资源的管理器)
- ReplicaSet、 DaemonSet 以及 Job 控制器
- Deployment 控制器
- StatefulSet 控制器
- Node 控制器
- Service 控制器
- Endpoints 控制器
- Namespace 控制器
- PersistentVolume 控制器
- 其他
了解kubelet
Kubelet 就是负责所有运行在工作节点上内容的组件。 它第一个任务就是在 API 服务器中创建一个 Node 资源来注册该节点。 然后需要持续监控 API 服务器是否把该节点分配给 pod, 然后启动 pod 容器。 具体实现方式是告知配置好的容器运行时(Docker、 CoreOS 的 Rkt,或者其他一些东西)来从特定容器镜像运行容器。 Kubelet 随后持续监控运行的容器,向 API 服务器报告它们的状态、事件和资源消耗。 Kubelet也是运行容器存活探针的组件,当探针报错时它会重启容器。 最后一点, 当 pod 从 API 服务器删除肘, Kubelet 终止容器,并通知服务器 pod 己经被终止了 。
Kubelet 一般会和 API 服务器通信并从中获取 pod 清单, 它也可以基于本 地指定目录下的 pod 清单来运行 pod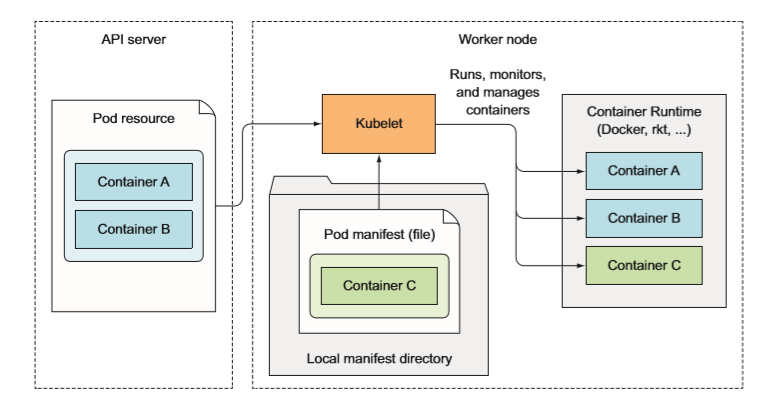


若有收获,就点个赞吧
0 人点赞
