安装
下载部署文件
https://github.com/coreos/kube-prometheus.git
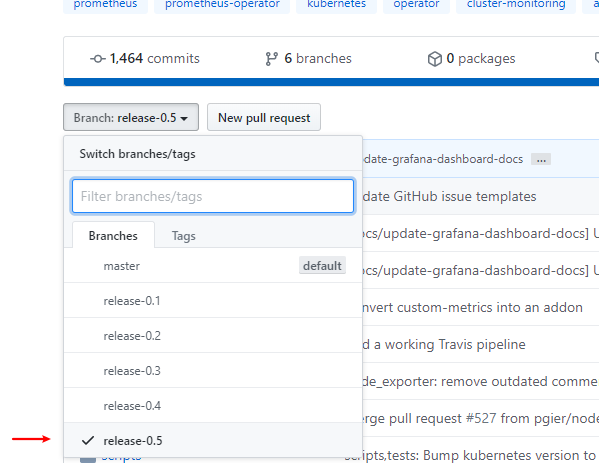
根据版本选择对应的release
| kube-prometheus stack | Kubernetes 1.14 | Kubernetes 1.15 | Kubernetes 1.16 | Kubernetes 1.17 | Kubernetes 1.18 |
|---|---|---|---|---|---|
release-0.3 |
✔ | ✔ | ✔ | ✔ | ✗ |
release-0.4 |
✗ | ✗ | ✔ (v1.16.5+) | ✔ | ✗ |
release-0.5 |
✗ | ✗ | ✗ | ✗ | ✔ |
HEAD |
✗ | ✗ | ✗ | ✗ | ✔ |
查看版本1.18.3 这边选用release-0.5
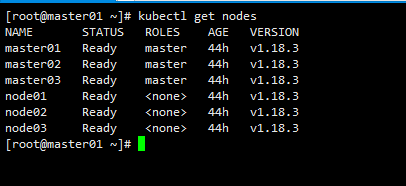
kubectl get nodes
然后下载配置文件
链接: https://pan.baidu.com/s/1y45iI_zJQRh_lM3Ux8qtWQ 提取码: pa5w
解压并配置yaml文件
在master上节点操作即可
unzip /root/kube-prometheus-release-0.5.zip
mkdir /root/prometheus
cp -r /root/kube-prometheus-release-0.5/manifests/* /root/prometheus/
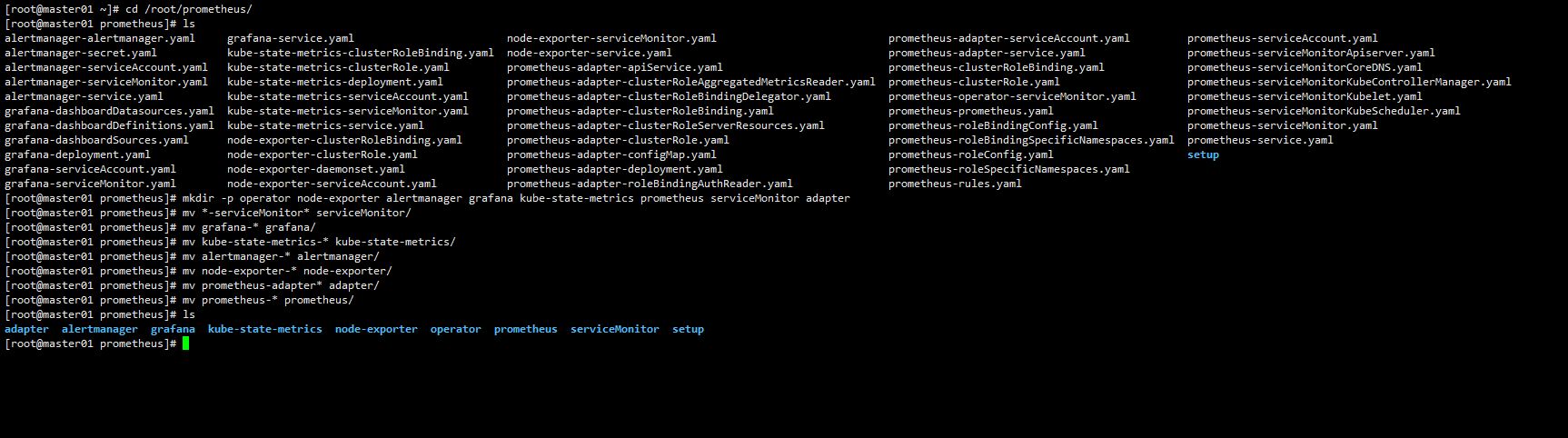
cd /root/prometheus/
mkdir -p operator node-exporter alertmanager grafana kube-state-metrics prometheus serviceMonitor adapter
mv *-serviceMonitor* serviceMonitor/
mv grafana-* grafana/
mv kube-state-metrics-* kube-state-metrics/
mv alertmanager-* alertmanager/
mv node-exporter-* node-exporter/
mv prometheus-adapter* adapter/
mv prometheus-* prometheus/
镜像下载
链接: https://pan.baidu.com/s/1XbCeh4KYUwKpJmwPYfzRCg 提取码: pzi7
quay.io/coreos/prometheus-operator:v0.38.1
quay.io/coreos/kube-rbac-proxy:v0.4.1
jimmidyson/configmap-reload:v0.3.0
quay.io/coreos/k8s-prometheus-adapter-amd64:v0.5.0
quay.io/prometheus/alertmanager:v0.20.0
quay.io/coreos/kube-state-metrics:v1.9.5
quay.io/prometheus/node-exporter:v0.18.1
quay.io/prometheus/prometheus:v2.15.2
grafana/grafana:6.6.0
quay.io/coreos/prometheus-config-reloader:v0.38.1
所以节点导入镜像
docker load -i pro-release-0.5.tar.gz
部署setup
kubectl apply -f /root/prometheus/setup/

部署其他资源
cd /root/prometheus/
kubectl apply -f adapter/
kubectl apply -f alertmanager/
kubectl apply -f node-exporter/
kubectl apply -f kube-state-metrics/
kubectl apply -f grafana/
kubectl apply -f prometheus/
kubectl apply -f serviceMonitor/
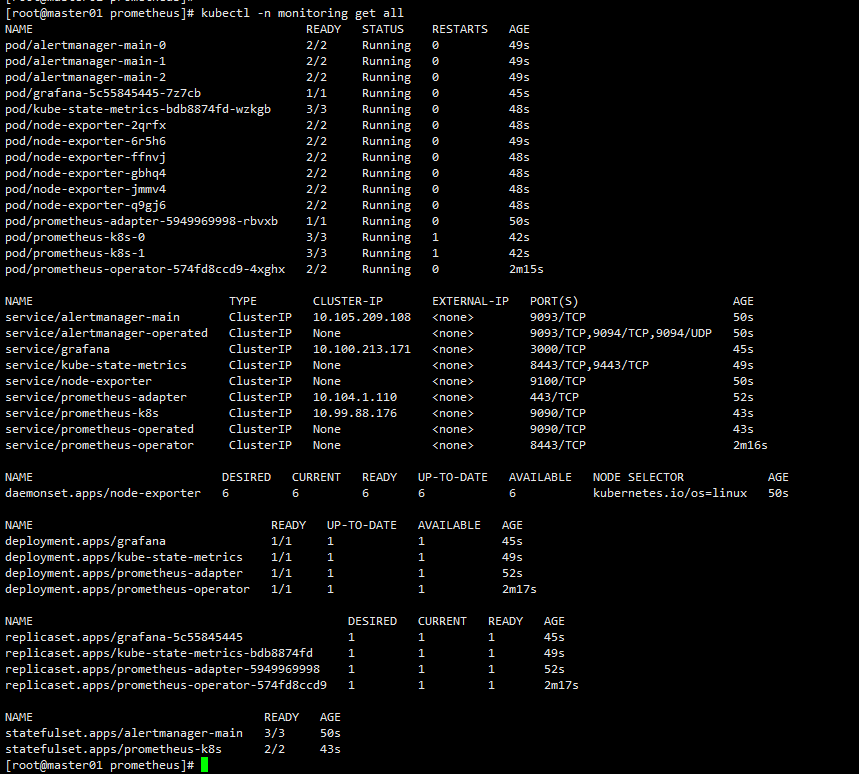
查看整体部署情况
kubectl -n monitoring get all
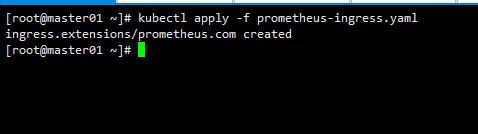
创建ingress
cat > prometheus-ingress.yaml << EOF
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus.com
namespace: monitoring
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: grafana.tk8s.com
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
- host: prometheus.tk8s.com
http:
paths:
- backend:
serviceName: prometheus-k8s
servicePort: 9090
- host: alertmanager.tk8s.com
http:
paths:
- backend:
serviceName: alertmanager-main
servicePort: 9093
EOF
kubectl apply -f prometheus-ingress.yaml
访问prometheus
看下ingress的nodeport是啥
kubectl get svc -n ingress-nginx

C:\Windows\System32\drivers\etc\hosts添加对应的域名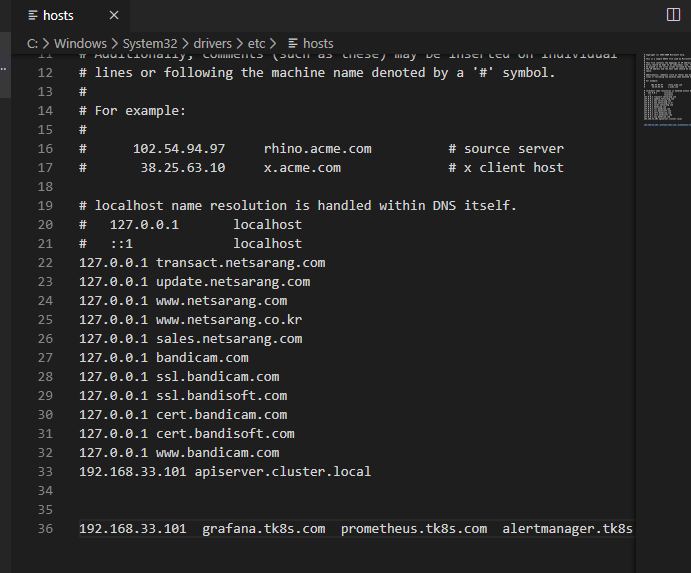
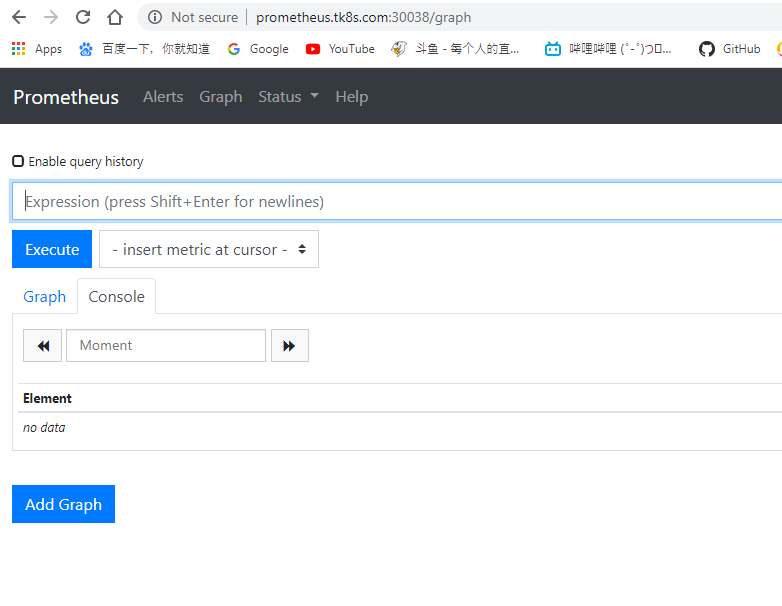
发现kube-controller-manager和kube-scheduler没检测到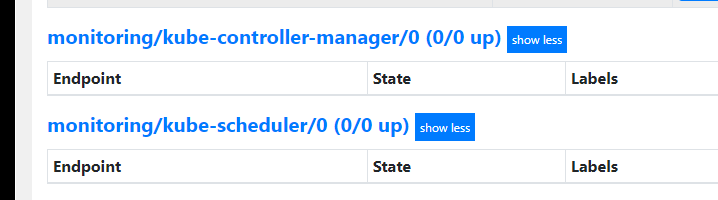
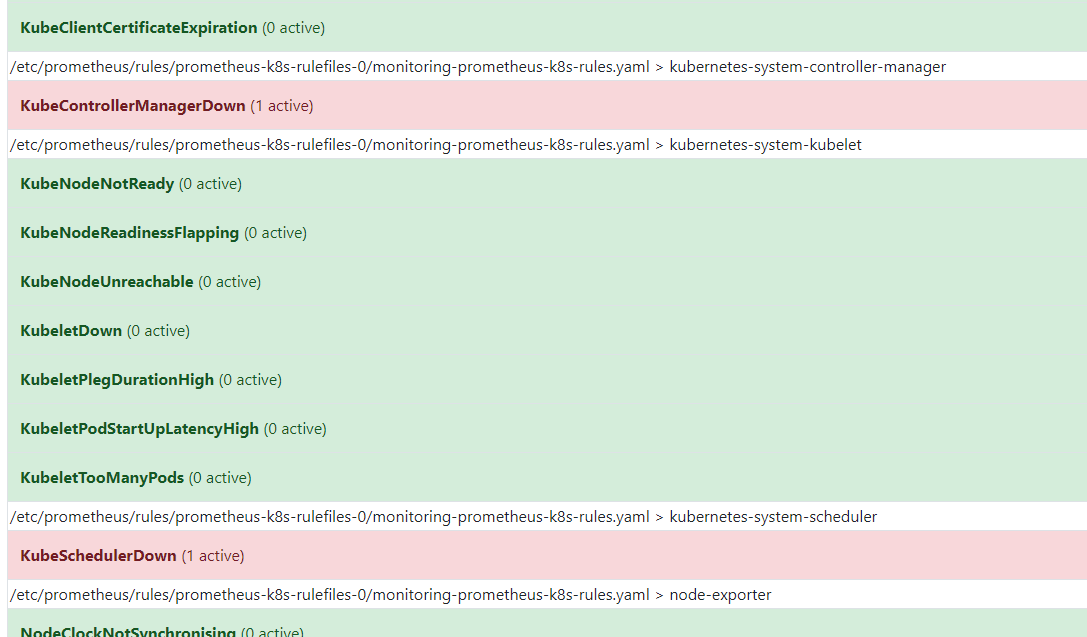
创建kube-controller-manager和kube-scheduler的svc
cat > prom-svc.yaml << EOF
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.33.101
- ip: 192.168.33.102
- ip: 192.168.33.103
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 192.168.33.101
- ip: 192.168.33.102
- ip: 192.168.33.103
ports:
- name: http-metrics
port: 10251
protocol: TCP
EOF

再次刷新即可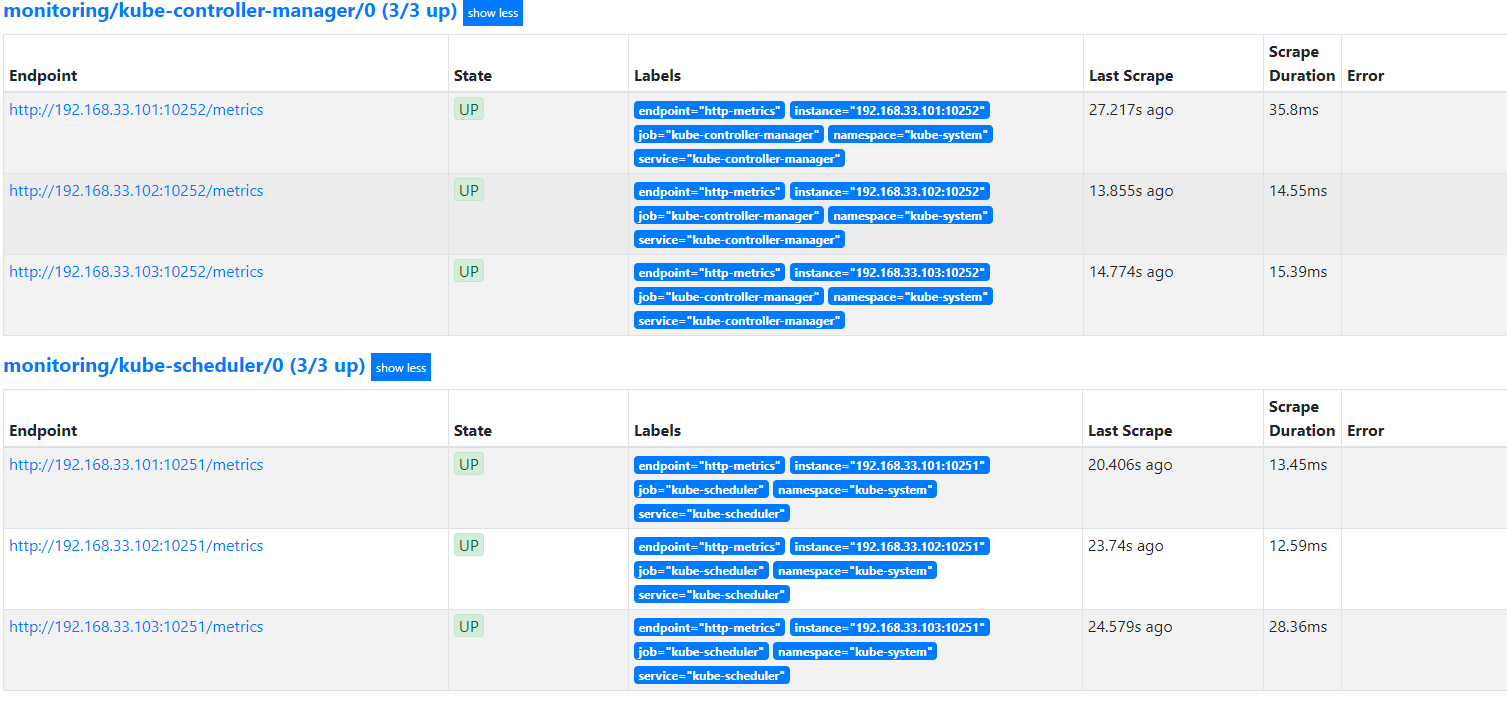
访问grafana
grafana初始用户名和密码都是是admin
官方自带的视图
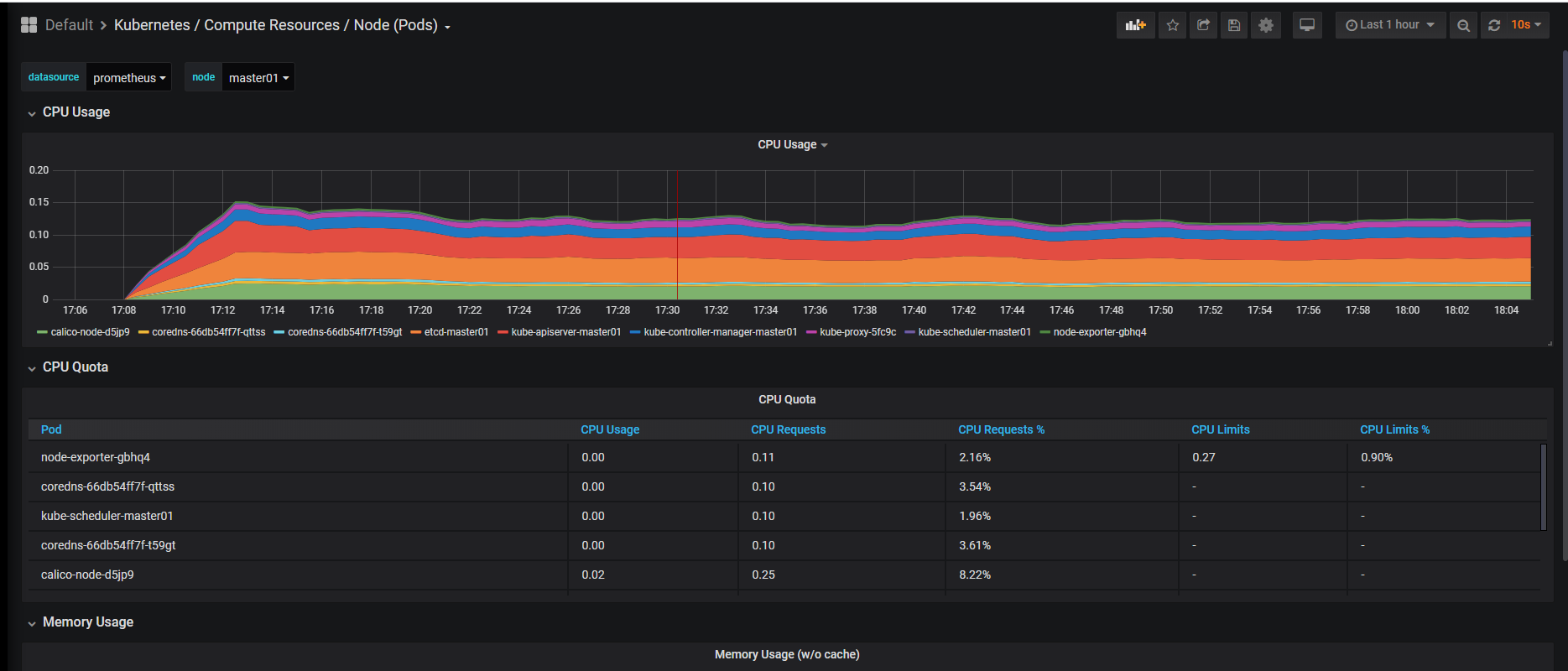
添加插件 DevOpsProdigy KubeGraf
DevOpsProdigy KubeGraf(https://github.com/devopsprodigy/kubegraf/) 是一个非常优秀的 Grafana Kubernetes 插件,是 Grafana 官方的 Kubernetes 插件(https://grafana.com/plugins/grafana-kubernetes-app) 的升级版本,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。
由于插件安装完成后需要重启 Grafana 才会生效前提是需要对插件目录/var/lib/grafana/plugins/做好持久化。
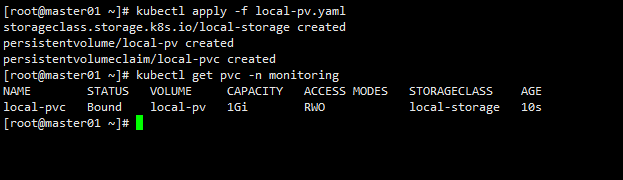
先创建一个local pv。在node01上建立一个目录
mkdir -p /opt/grafana/plugins
chmod 777 /opt/grafana/plugins/
给node01打上label
kubectl label nodes node01 local-pv=node01

建立pv
cat > local-pv.yaml << EOF
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
namespace: monitoring
provisioner: kubernetes.io/no-provisioner
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
namespace: monitoring
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /opt/grafana/plugins
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: local-pv
operator: In
values:
- node01
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: local-pvc
namespace: monitoring
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
storageClassName: local-storage
EOF
kubectl apply -f local-pv.yaml
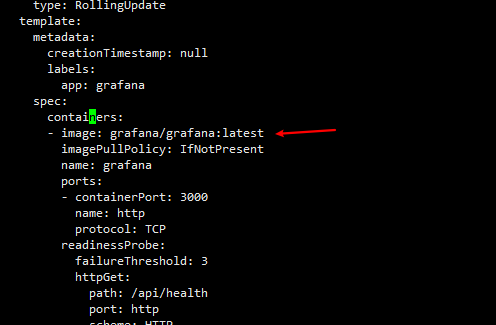
修改grafana
kubectl edit -n monitoring deployments.apps grafana
...;
image: grafana/grafana:latest
....
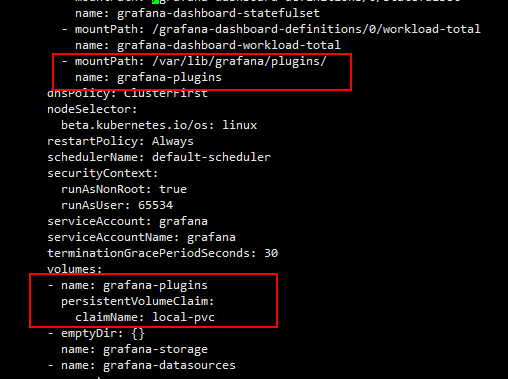
- mountPath: /var/lib/grafana/plugins/
name: Ggrafana-plugins
....
- name: grafana-plugins
persistentVolumeClaim:
claimName: local-pvc
登陆pod
[root@master01 ~]# kubectl get pods -n monitoring | grep grafana
grafana-6567f6fb8d-f6fgq 1/1 Running 0 46s
[root@master01 ~]# kubectl exec -it -n monitoring grafana-6567f6fb8d-f6fgq -- sh
/usr/share/grafana $ grafana-cli plugins install devopsprodigy-kubegraf-app
...
/usr/share/grafana $ grafana-cli plugins install Grafana-piechart-panel
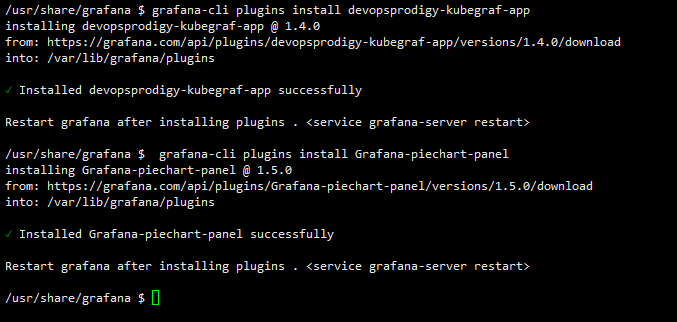
重启grafana
[root@master01 ~]# kubectl delete pod -n monitoring grafana-6567f6fb8d-f6fgq
pod "grafana-6567f6fb8d-f6fgq" deleted
pod启动后打开grafana 找到插件,点击 enable 启用插件。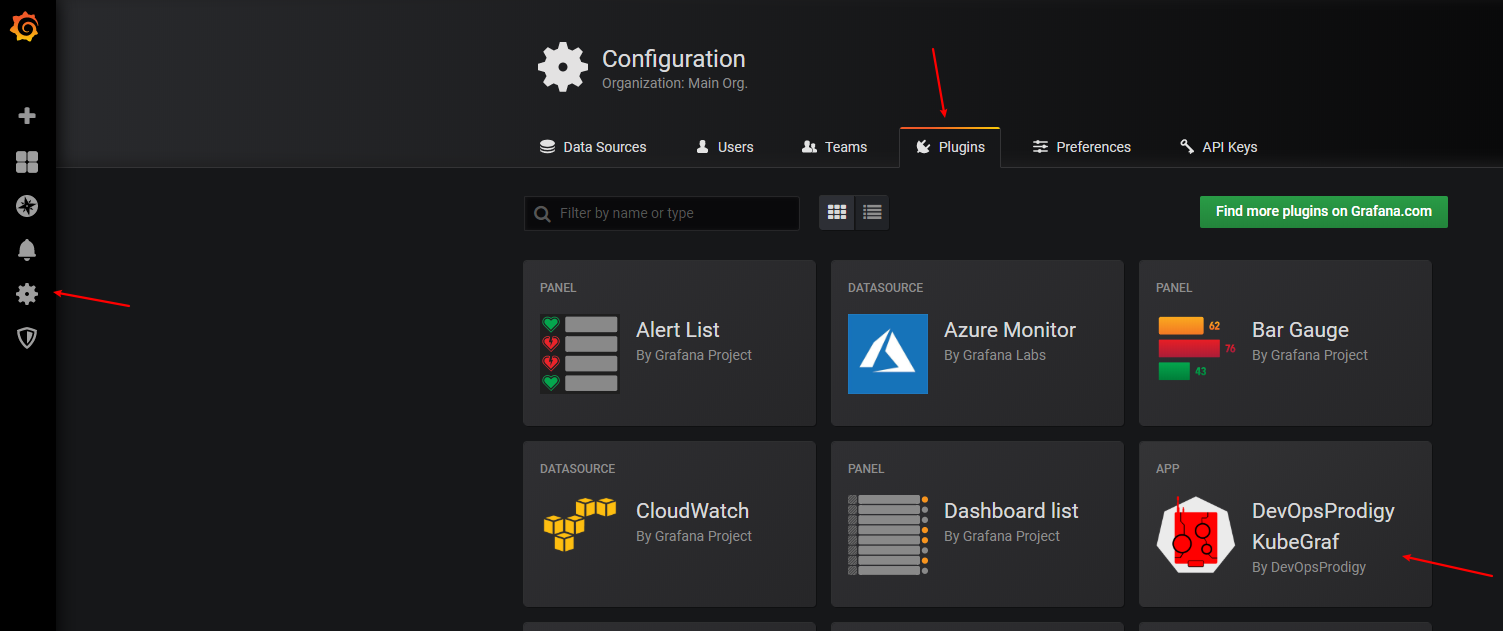
点击 Setup your first k8s-cluster 创建一个新的 Kubernetes 集群:
- URL 使用 Kubernetes Service 地址即可:https://kubernetes.default:443
- Access 访问模式使用:
Server(default) - 由于插件访问 Kubernetes 集群的各种资源对象信息,所以我们需要配置访问权限,这里我们可以简单使用 kubectl 的
kubeconfig来进行配置即可。 - 勾选 Auth 下面的
TLSClientAuth和WithCACert两个选项 - 其中
TLSAuthDetails下面的值就对应kubeconfig里面的证书信息。比如我们这里的kubeconfig文件格式如下所示:
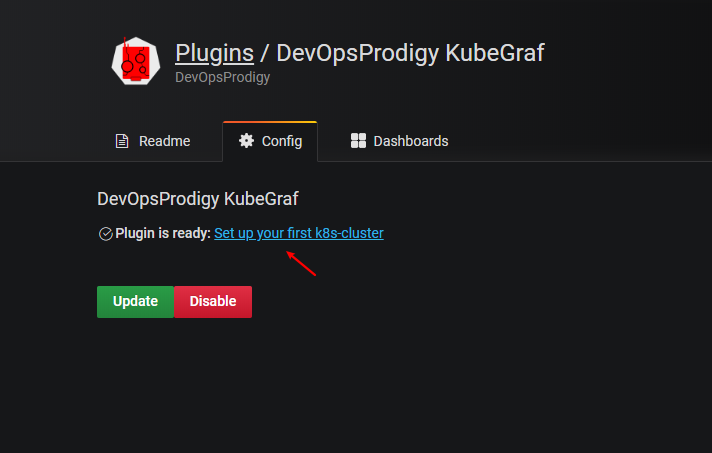
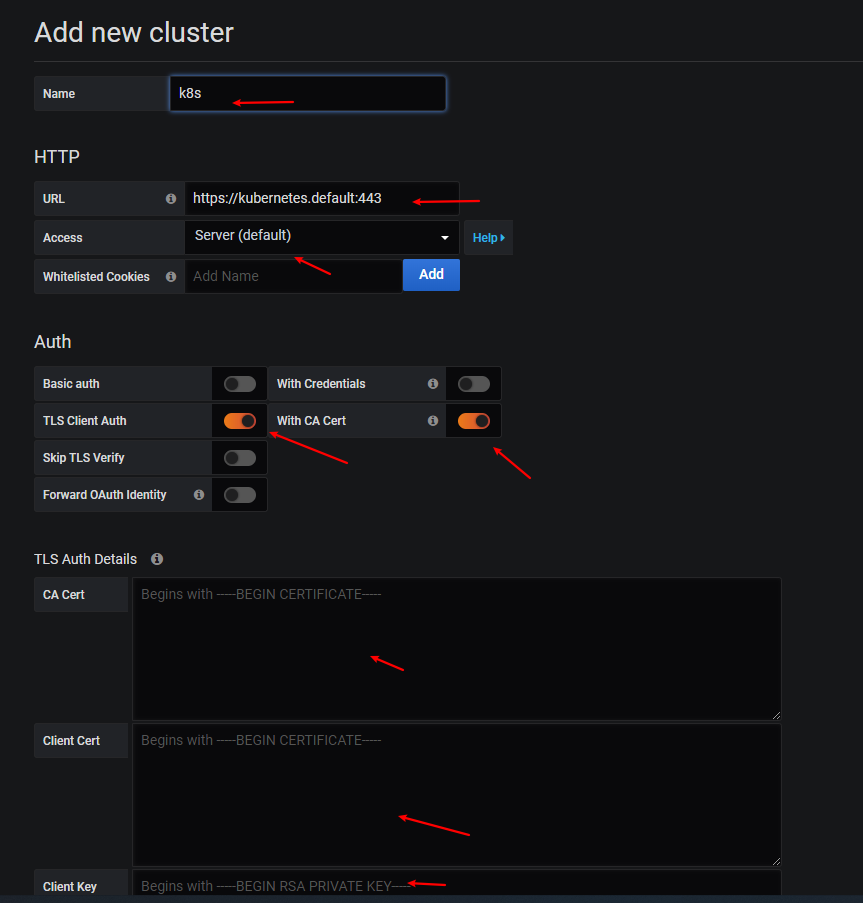
那么 CACert 的值就对应 kubeconfig 里面的 <certificate-authority-data> 进行 base64 解码过后的值;ClientCert 的值对应 <client-certificate-data> 进行 base64 解码过后的值;ClientKey 的值就对应 <client-key-data> 进行 base64 解码过后的值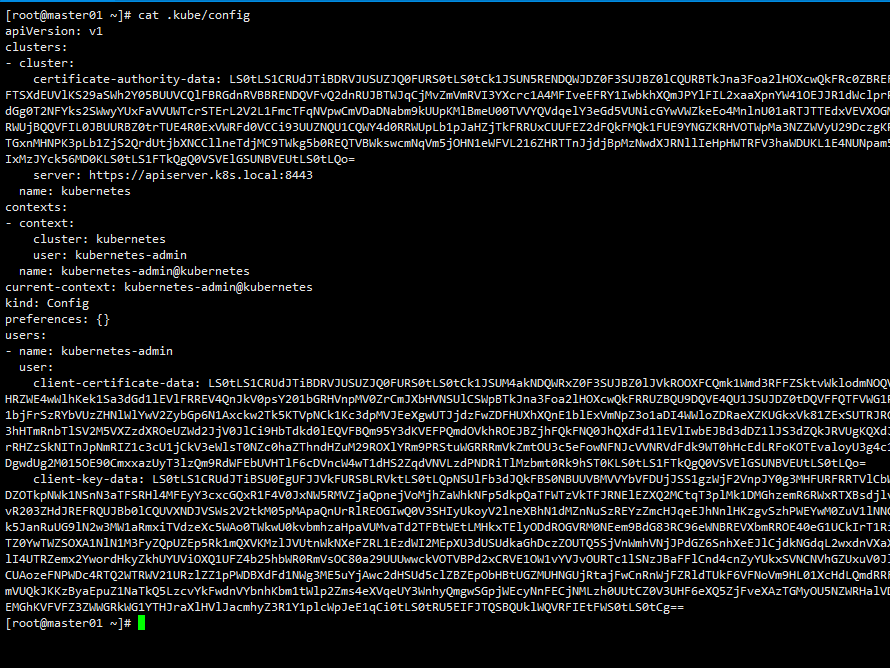
echo `grep client-cert /root/.kube/config |cut -d" " -f 6` | base64 -d > /root/client.pem
echo `grep client-key-data /root/.kube/config |cut -d" " -f 6` | base64 -d > /root/client-key.pem
echo `grep certificate-authority-data /root/.kube/config |cut -d" " -f 6` | base64 -d > /root/ca.pem
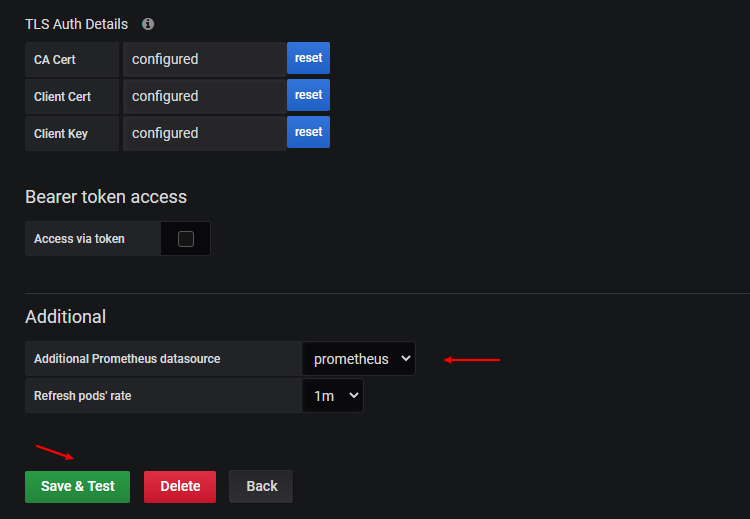
- 最后在
additional datasources下拉列表中选择 prometheus 的数据源。 - 点击
Save&Test正常就可以保存成功了
自定义告警规则
举例添加etcd告警规则
由于etcd默认没有target,所以先添加对应的target
etcd使用的证书都在对应节点的/etc/kubernetes/pki/etcd/目录下面
ls /etc/kubernetes/pki/etcd

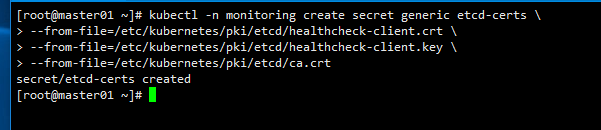
先将需要使用的证书通过secret对象保存到集群中
kubectl -n monitoring create secret generic etcd-certs \
--from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt \
--from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key \
--from-file=/etc/kubernetes/pki/etcd/ca.crt
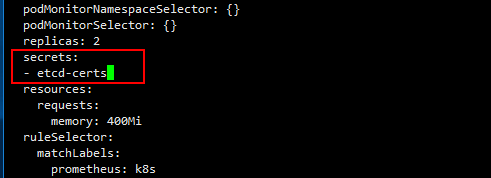
将创建etcd-certs对象配置到prometheus资源对象中,直接更新:
kubectl edit prometheus k8s -n monitoring
...
replicas: 2
secrets:
- etcd-certs
 tmj
tmj
添加etcd的target
cat > etcd-target.yaml << EOF
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: etcd-k8s
name: etcd-k8s
namespace: monitoring
spec:
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: etcd
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: etcd
name: etcd-k8s
namespace: kube-system
spec:
ports:
- name: port
port: 2379
protocol: TCP
type: ClusterIP
clusterIP: None
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.33.101
nodeName: master01
- ip: 192.168.33.102
nodeName: master02
- ip: 192.168.33.103
nodeName: master03
ports:
- name: port
port: 2379
protocol: TCP
EOF
kubectl apply -f etcd-target.yaml
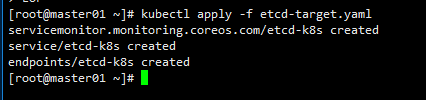
此时刷新prometheus发现etcd的target有了
然后添加自定义告警规则
cat > prometheus-etcdRules.yaml << EOF
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: etcd-rules
namespace: monitoring
spec:
groups:
- name: etcd
rules:
- alert: EtcdClusterUnavailable
annotations:
summary: etcd cluster small
description: If one more etcd peer goes down the cluster will be unavailable
expr: |
count(up{job="etcd"} == 0) > (count(up{job="etcd"}) / 2 - 1)
for: 3m
labels:
severity: critical
EOF
kubectl apply -f prometheus-etcdRules.yaml
去 Prometheus Dashboard 的 Alert 页面下面就可以查看到上面我们新建的报警规则了: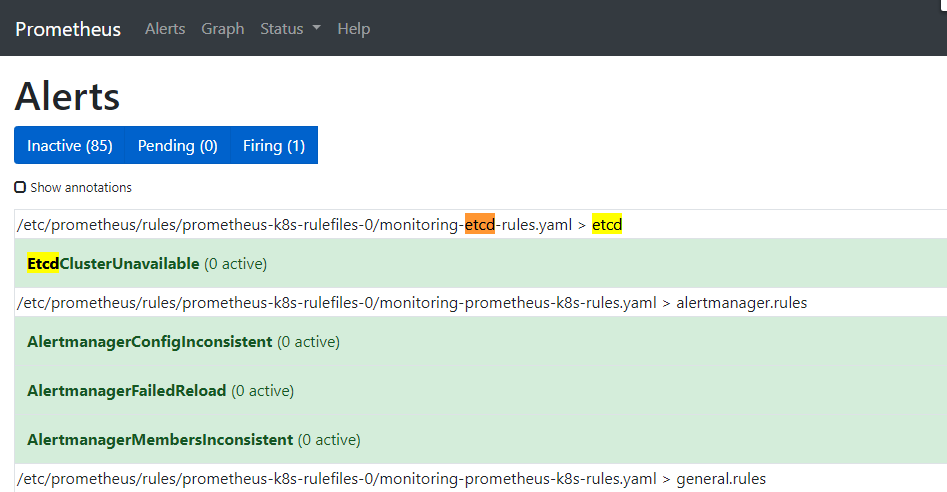
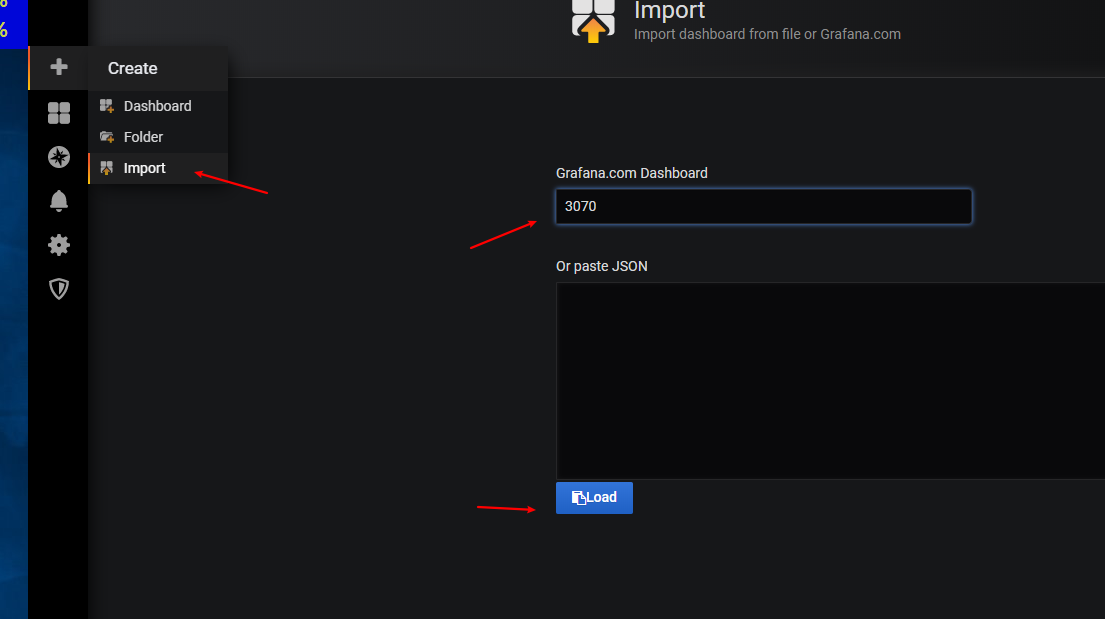
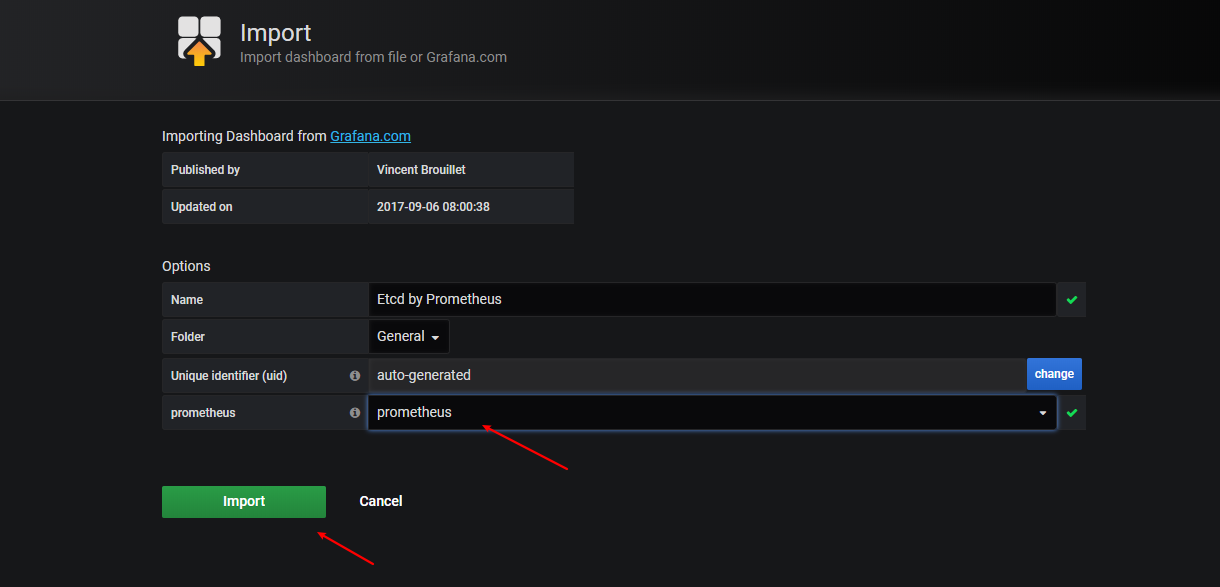
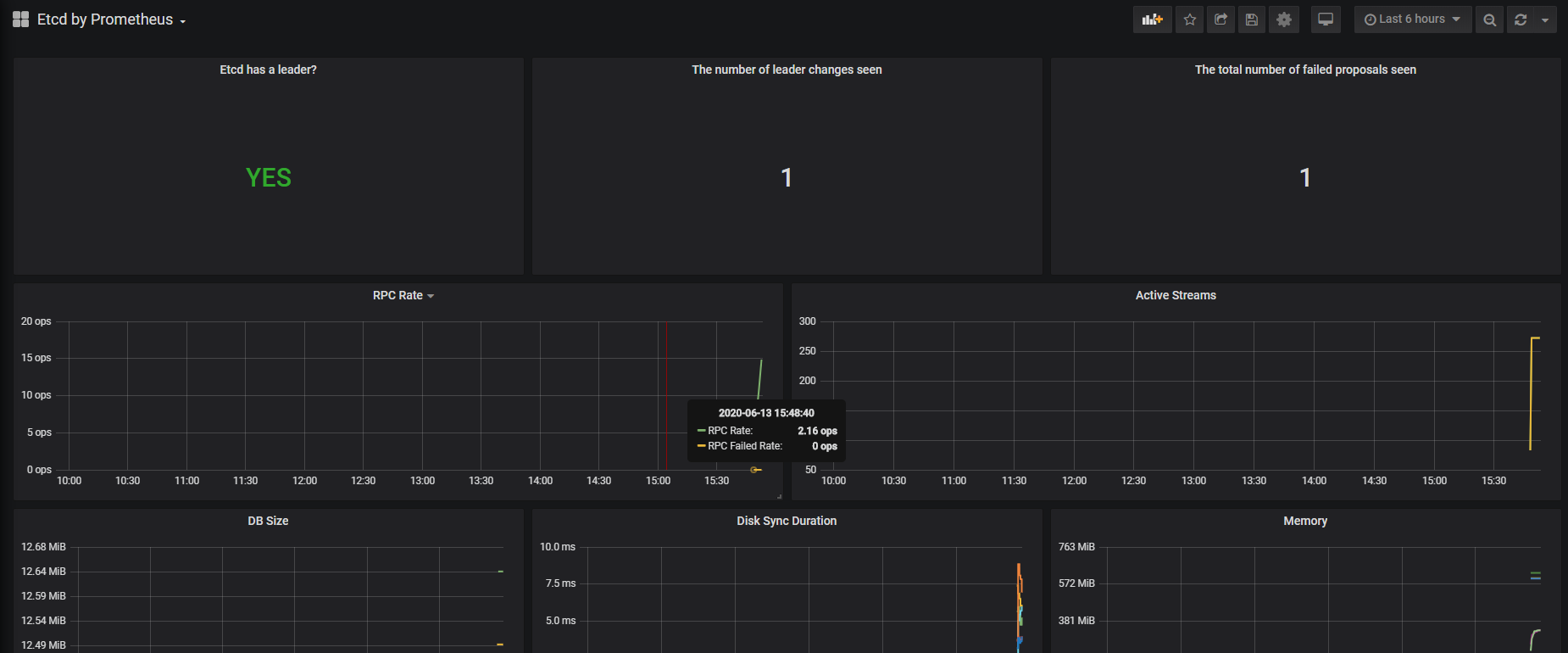
钉钉告警
获取钉钉群机器人token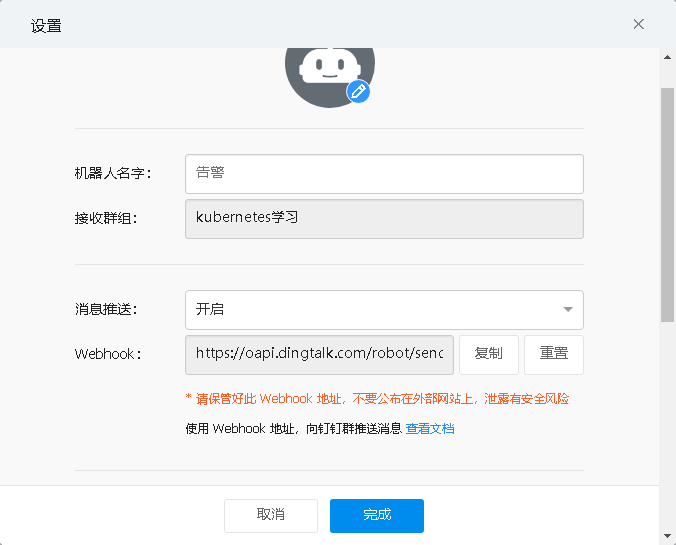
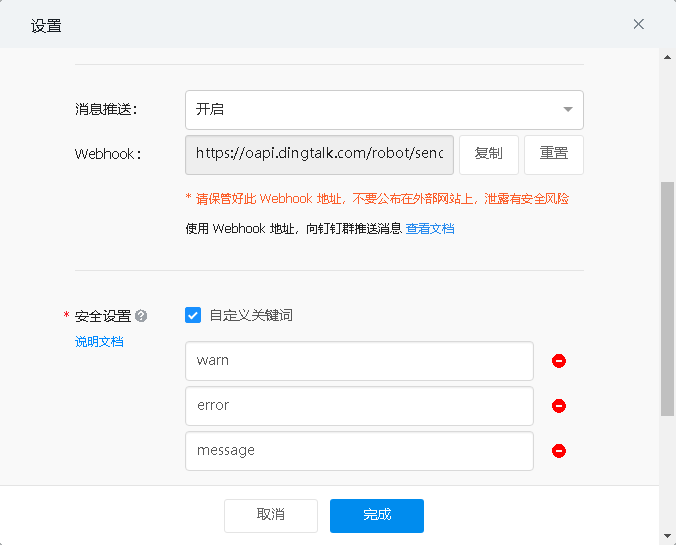
创建钉钉机器人pod
cat > dingtalk-webhook.yaml << EOF
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
run: dingtalk
name: webhook-dingtalk
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
run: dingtalk
template:
metadata:
name: webhook-dingtalk
labels:
run: dingtalk
spec:
containers:
- name: dingtalk
image: timonwong/prometheus-webhook-dingtalk:v0.3.0
imagePullPolicy: IfNotPresent
args:
- --ding.profile=webhook1=https://oapi.dingtalk.com/robot/send?access_token=0cf1e39a09c01a50e9f9fc2000b97689aafba157752dbda524624cd75608671c
ports:
- containerPort: 8060
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
labels:
run: dingtalk
name: webhook-dingtalk
namespace: monitoring
spec:
ports:
- port: 8060
protocol: TCP
targetPort: 8060
selector:
run: dingtalk
sessionAffinity: None
EOF
kubectl apply -f dingtalk-webhook.yaml
创建alertmanager接收器
cat > alertmanager.yaml << EOF
global:
resolve_timeout: 5m
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: webhook
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://webhook-dingtalk.monitoring.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true
EOF
替换原有secret
kubectl delete secret alertmanager-main -n monitoring
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
此时prometheus上有个告警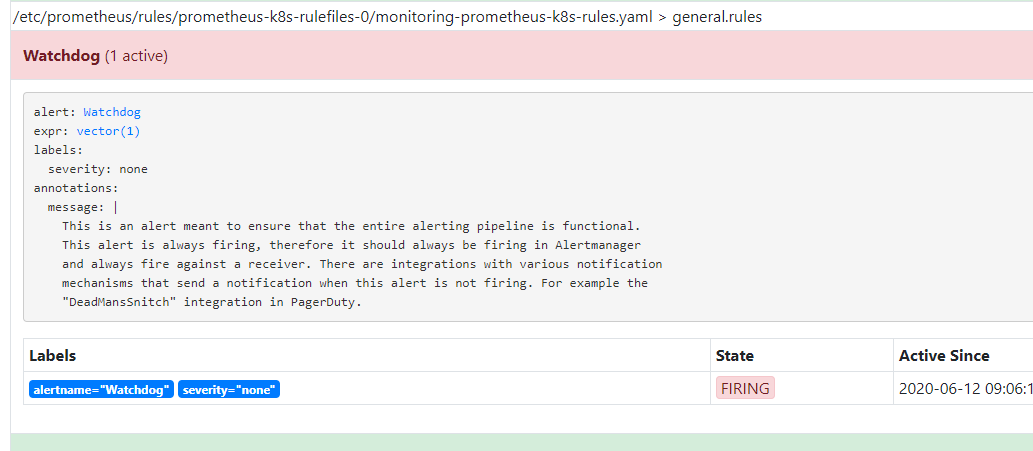
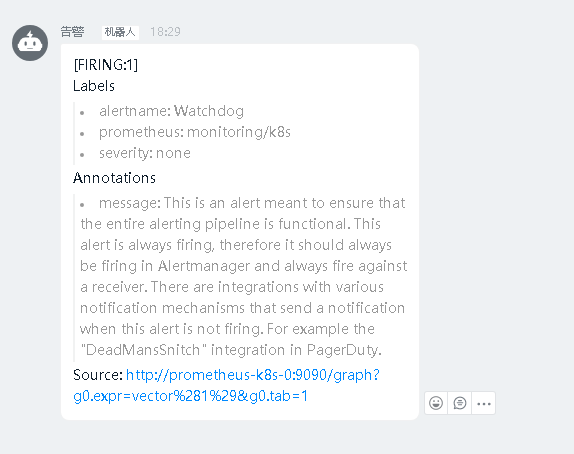
企业微信告警
配置微信告警
需要corp_id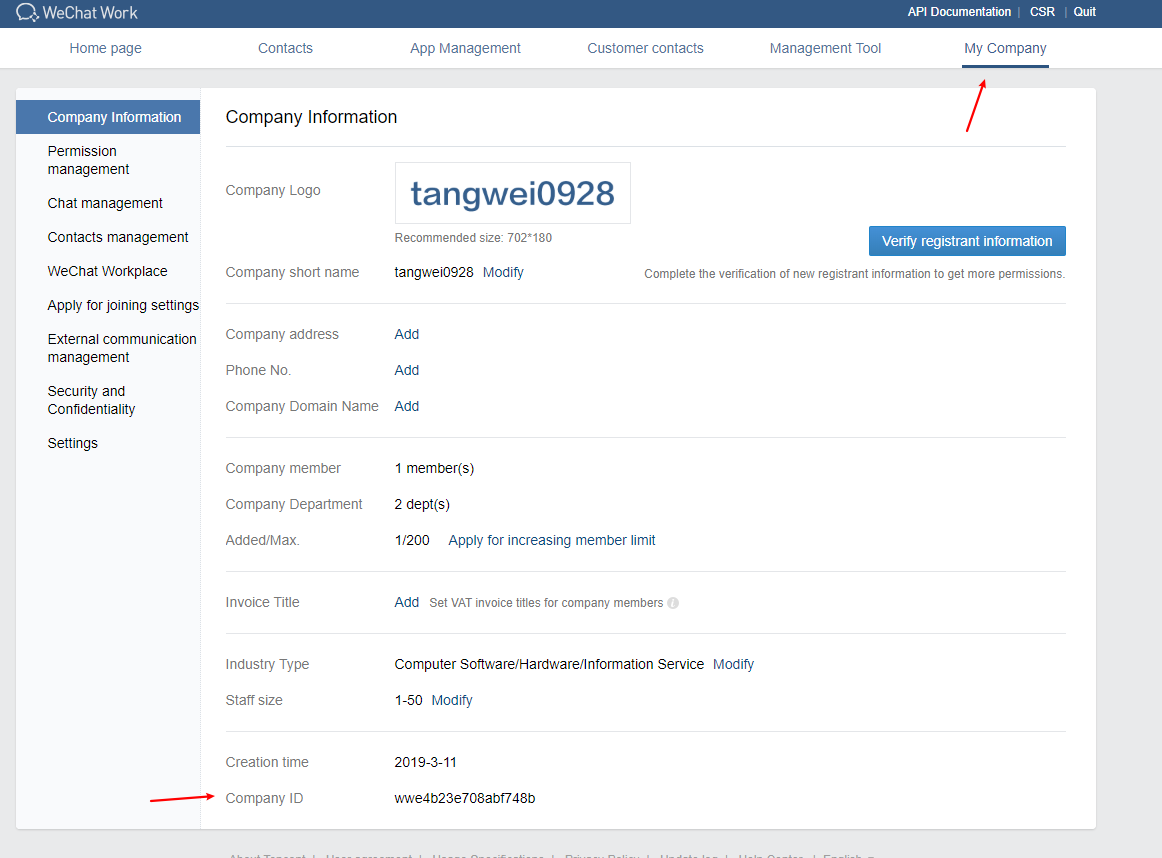
需要agent id和apisecret在自定义的机器人中
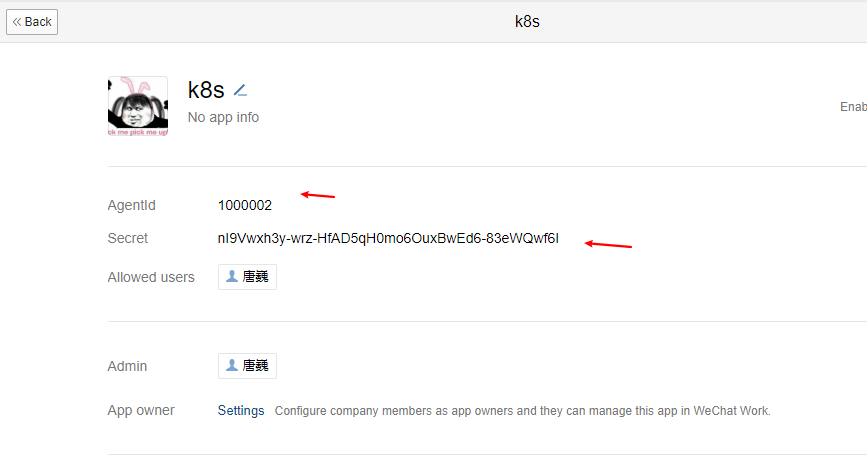
cat > alertmanager.yaml <<EOF
global:
resolve_timeout: 10m
wechat_api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
wechat_api_secret: 'nI9Vwxh3y-wrz-HfAD5qH0mo6OuxBwEd6-83eWQwf6I'
wechat_api_corp_id: 'wwe4b23e708abf748b'
templates:
- '/etc/alertmanager/config/wechat.tmpl'
route:
group_by:
- job
- alertname
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: "wechat"
receivers:
- name: 'wechat'
wechat_configs:
- send_resolved: true
corp_id: 'wwe4b23e708abf748b'
to_user: '@all'
agent_id: '1000002'
api_secret: 'nI9Vwxh3y-wrz-HfAD5qH0mo6OuxBwEd6-83eWQwf6I'
EOF
cat > wechat.tmpl << EOF
{{ define "wechat.default.message" }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
====异常告警====
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警exporter:{{ $alert.Labels.job }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
{{- if eq $index 0 }}
====异常恢复====
告警类型: {{ $alert.Labels.alertname }}
告警级别: {{ $alert.Labels.severity }}
告警exporter:{{ $alert.Labels.job }}
告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}};{{$alert.Annotations.summary}}
故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {{ $alert.Labels.instance }}
{{- end }}
{{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {{ $alert.Labels.namespace }}
{{- end }}
{{- if gt (len $alert.Labels.node) 0 }}
节点信息: {{ $alert.Labels.node }}
{{- end }}
{{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {{ $alert.Labels.pod }}
{{- end }}
============END============
{{- end }}
{{- end }}
{{- end }}
{{- end }}
EOF
kubectl delete secrets -n monitoring alertmanager-main
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml --from-file=wechat.tmpl -n monitoring

邮件告警
cat > alertmanager.yaml <<EOF
global:
resolve_timeout: 5m
smtp_smarthost: 'smtp.exmail.qq.com:465'
smtp_from: 'tangwei@tk8s.com'
smtp_auth_username: 'tangwei@tk8s.com'
smtp_auth_password: '密码'
smtp_hello: 'tk8s.com'
smtp_require_tls: false
route:
receiver: email
group_wait: 30s
group_interval: 1m
repeat_interval: 5h
group_by: ['job']
receivers:
- name: email
email_configs:
- to: 1247549534@qq.com
send_resolved: true
EOF
替换原有secret
kubectl delete secret alertmanager-main -n monitoring
kubectl create secret generic alertmanager-main --from-file=alertmanager.yaml -n monitoring
查看告警
部署black-exporter
cat > black-exporter.yaml <<EOF
apiVersion: v1
data:
config.yml: |
modules:
http_2xx:
prober: http
timeout: 5s
http:
method: GET
preferred_ip_protocol: "ip4"
http_post_2xx:
prober: http
timeout: 5s
http:
method: POST
preferred_ip_protocol: "ip4"
tcp:
prober: tcp
timeout: 5s
ping:
prober: icmp
timeout: 3s
icmp:
preferred_ip_protocol: "ip4"
dns_k8s:
prober: dns
timeout: 5s
dns:
transport_protocol: "tcp"
preferred_ip_protocol: "ip4"
query_name: "kubernetes.default.svc.cluster.local"
query_type: "A"
kind: ConfigMap
metadata:
name: blackbox-exporter
namespace: monitoring
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
containers:
- image: prom/blackbox-exporter:v0.16.0
name: blackbox-exporter
ports:
- containerPort: 9115
volumeMounts:
- name: config
mountPath: /etc/blackbox_exporter
args:
- --config.file=/etc/blackbox_exporter/config.yml
- --log.level=info
volumes:
- name: config
configMap:
name: blackbox-exporter
---
apiVersion: v1
kind: Service
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
selector:
app: blackbox-exporter
ports:
- name: http
port: 9115
targetPort: 9115
EOF
kubectl apply -f black-exporter.yaml
编辑service monitor,利用http_2xx模块监控一个url
cat > black-sm.yaml <<EOF
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
app: blackbox-exporter
name: blackbox-exporter
namespace: monitoring
spec:
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
app: blackbox-exporter
endpoints:
- interval: 15s
port: http
path: /probe
relabelings:
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __meta_kubernetes_service_label_cluster
targetLabel: cluster
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __param_module
targetLabel: module
- action: replace
regex: (.*)
replacement: $1
sourceLabels:
- __param_target
targetLabel: target
params:
module:
- http_2xx
target:
- http://ucenter-svc.test:8083/healthCheck
EOF
kubectl apply -f black-sm.yaml

添加告警规则
cat > http-rules.yaml << EOF
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: black-exporter-rules
namespace: monitoring
spec:
groups:
- name: black-exporter
rules:
- alert: httpServerError
annotations:
message: http server {{ $labels.target }} lost, please check http server.
expr: |
probe_success{module="http_2xx"} == 0
for: 3m
labels:
severity: critical
EOF
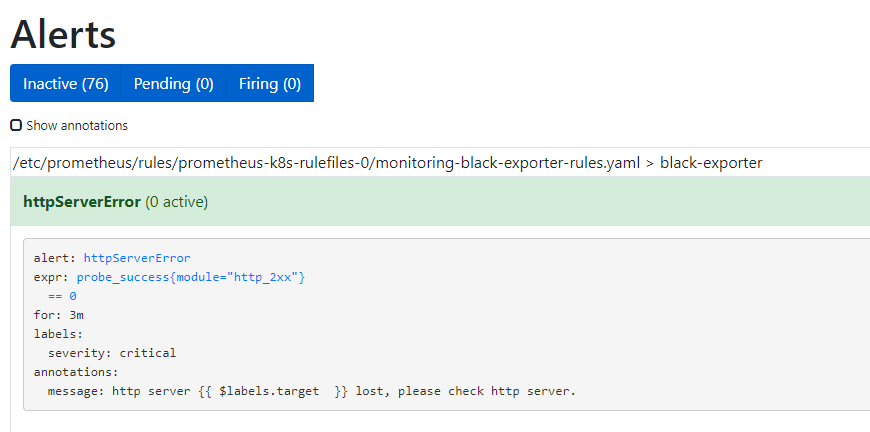
grafana中导入json
blackbox-exporter_rev1.json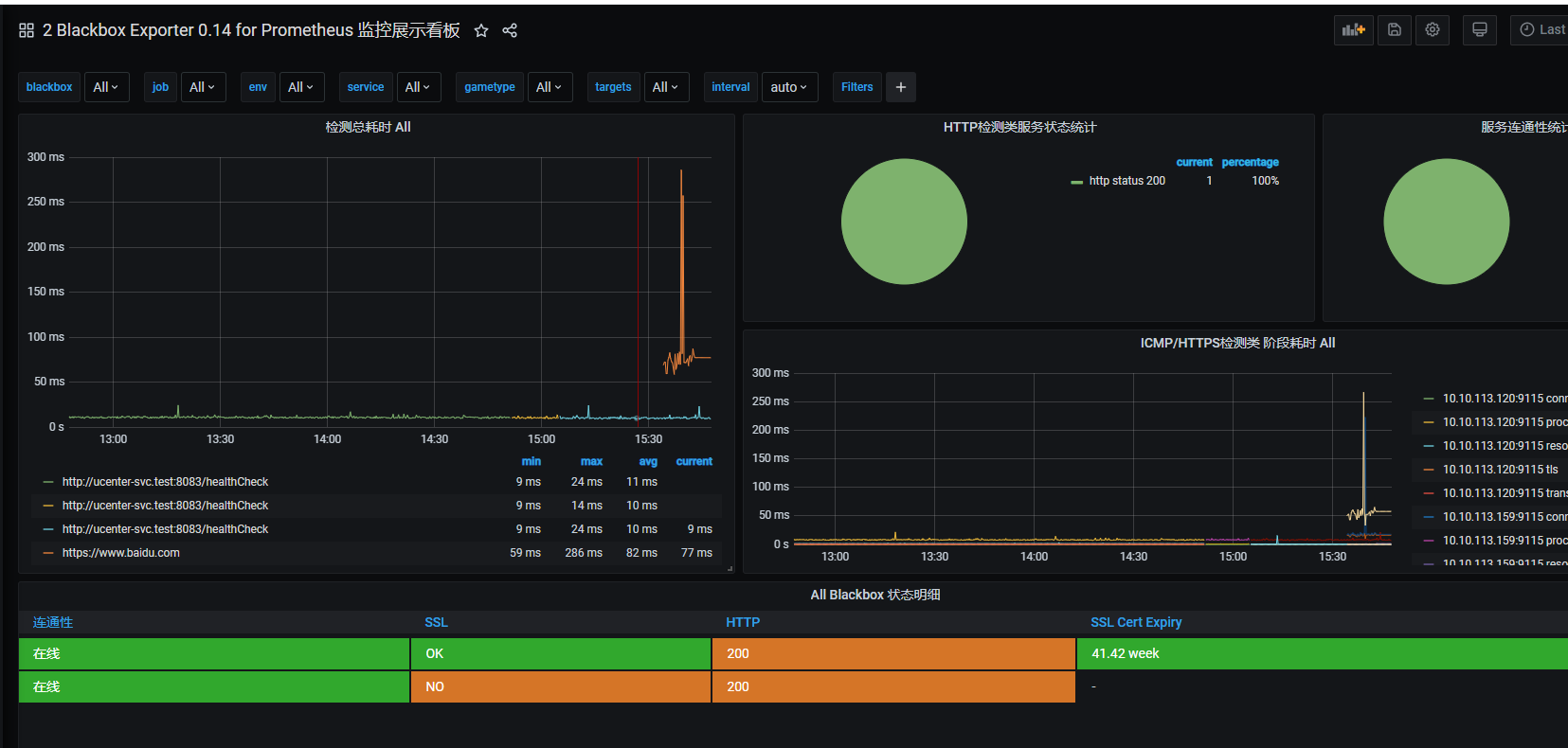
部署es-exporter
helm repo add braedon https://braedon.github.com/helm
helm repo update
helm install es7-exporter braedon/prometheus-es-exporter -n monitoring --set elasticsearch.cluster=10.1.0.20:9200 --set image.tag=0.14.0
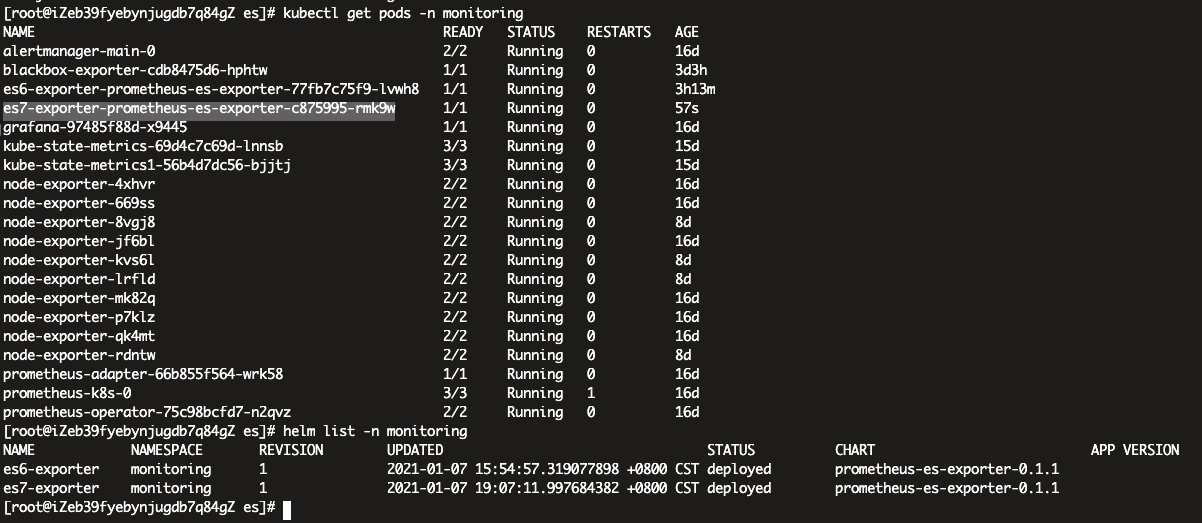
vim > es7-sm.yaml << EOF
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: es7
name: es7
namespace: monitoring
spec:
endpoints:
- port: prometheus
interval: 30s
scheme: http
jobLabel: k8s-app
namespaceSelector:
matchNames:
- monitoring
selector:
matchLabels:
app: prometheus-es-exporter
release: es7-exporter
EOF
kubectl apply -f es7-sm.yaml

grafana加载模版ElasticSearch-1611991918318.json
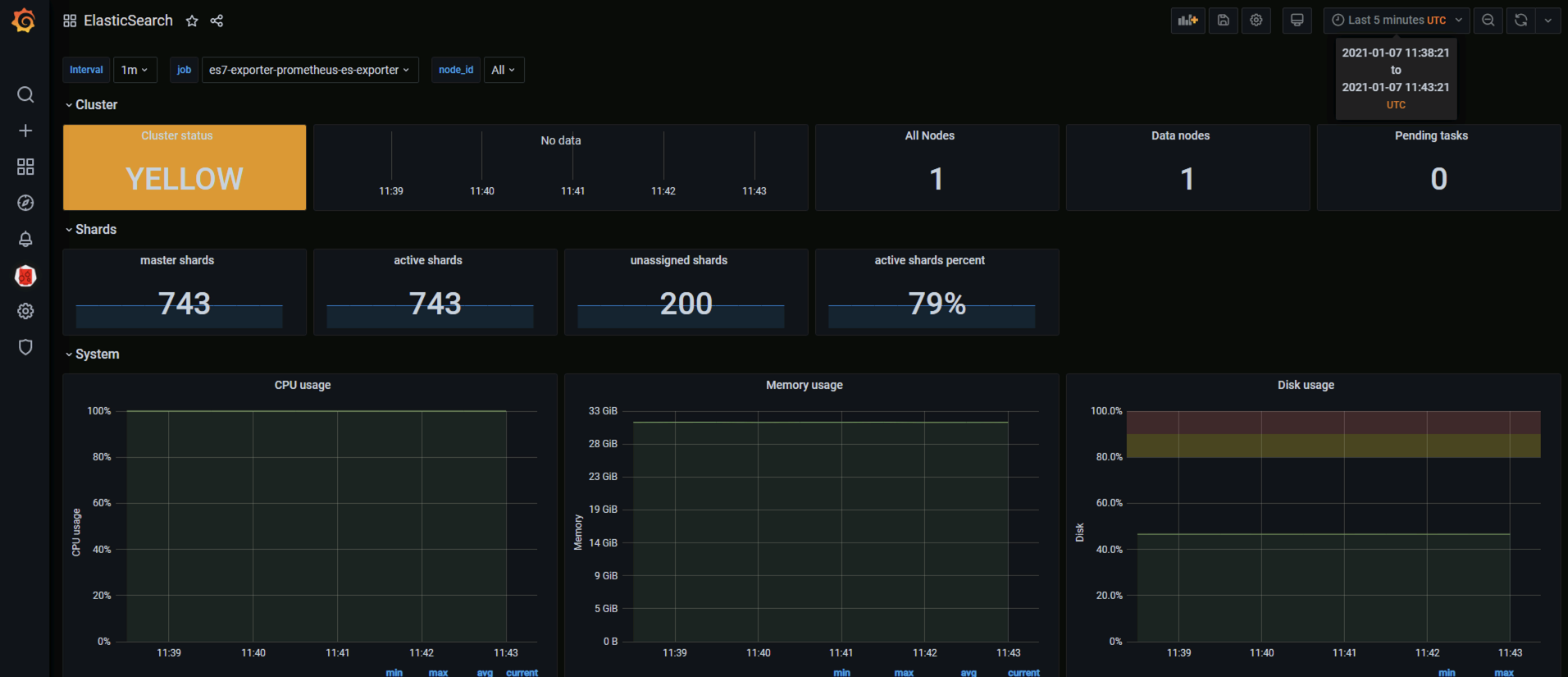

若有收获,就点个赞吧
0 人点赞
