2017年9月6日晚,DTalk邀请到了沈国阳老师,他参与了美团用户画像服务从无到有的过程,进行了一次关于《美团点评沈国阳:我们在谈用户画像的时候到底在谈什么?》的微信群线上主题分享。
分享活动共分成两个部分,第一部分是沈国阳老师分享关于用户画像大家关心的,第二部分是老师和大家的Q&A的互动环节。以下是活动内容的完整文字稿。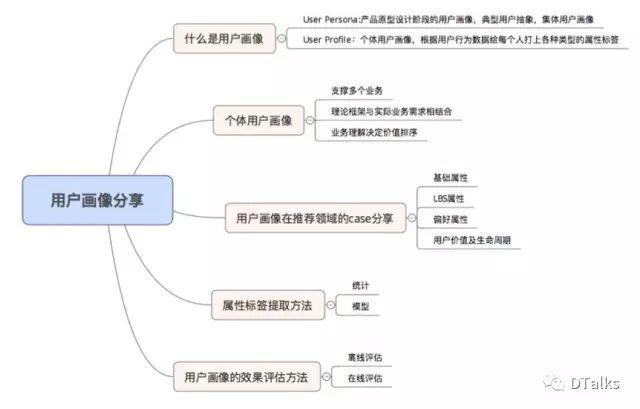
1、通常互联网的用户画像是指什么?
用户画像这个词在互联网公司用得很广泛,但是可能很多人没有注意到,这个词包 含了2种不同的含义。
- User Persona:这是对一个用户群体的整体抽象。产品原型设计阶段的用户画像, 这是在前期的产品研发过程中对目标用户进行定义的过程。这个工作的目标是充分 理解目标用户,从而在产品功能的设计和取舍上作出正确的决策。这种用户画像的 具体执行方法,主要是通过深入用户所在地区进行用户访谈,或者线上的问卷调研 得到。
- User Profile:这是对每一个个体的画像。这是在产品用户量有一定规模以后进行 的,利用用户的行为数据或者填报的资料进行的用户属性标签提取。这时候主要是 从在线数据上去提取标签,或者利用在线数据进行用户标签的预测。这些标签可以 应用到方方面面的工作中去。可以用到哪些方面,具体的特征提取或者挖掘的方法 有哪些,如果评估特征提取的效果,这部分是我们接下来要重点展开介绍的。
2、User Profile 用户画像的业务场景
下面我们就重点谈谈User Profile类型的用户画像(后续简称“用户画像”)。从表面上来说,用户画像主要是标签提取或者标签预测的工作。然而,事实上,选择哪些标签,为什么要选择那些标签去提取,这背后的逻辑才是最重要的。在标签集合的选择上,可以依据一些理论知识和过往经验去建立一套不重不漏的标签体系。但这样建立的标签体系会过于庞杂,必须从中挑选出符合业务目标的标签,按照一定的优先级去逐步实现。在互联网企业里面,需要使用用户画像的业务场景非常多。下面用一个图大致描述一下:
一方面,用户画像可以支持这么多业务,每一个业务方向都是对公司非常重要的方 向,可见用户画像对公司来说是非常重要的。另一方面,这么多方向都需要用户画 像,每个方向都有自己独特的需求,这就要求用户画像团队对支撑的业务要进行深 入的理解,了解什么样的标签对这个业务有帮助,从而做好价值排序,对业务进行 精准支持。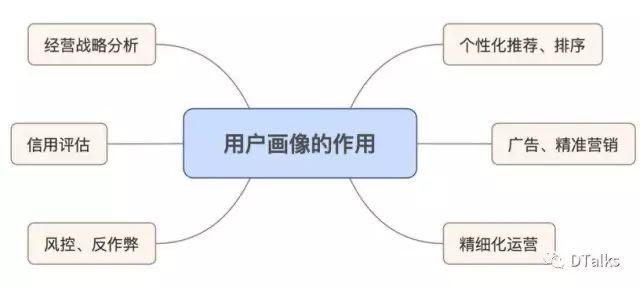
3、美团推荐系统是如何做用户画像的?
首先我们要了解一下推荐系统的业务目标。根据公司业务形态的不同,业务发展阶段的不同,对推荐系统的要求也是不一样的。早期的美团app是以交易为主导的一个本地生活服务平台,因此,对于当时的美团推荐系统而言,我们会非常关注用户的下单率指标,因此在做用户画像的时候,我们关注点也是,用户的哪些属性对达成交易有帮助。用户的品类偏好属性很关键。用户喜欢中餐还是西餐还是日料,喜欢火锅还是自助餐,如果抓不住用户的品类偏好特征,我们的推荐很可能被用户拒绝。
其次,作为一个本地生活服务平台,用户的地理位置也是非常关键的信息。一般来说,我们不能给他推荐离他非常远的餐厅。我们可以在工作日给他们推荐公司附近的餐厅,而周末推荐居住地附近的餐厅。如果他离开了他的常住城市,他很可能需要寻找酒店或者旅游景点。用户的消费水平也是很关键的信息。一个通常只吃20元左右快餐的用户,频繁给他推荐200元大餐,那也是大概率要被拒绝的。最后,用户的一些基础信息,例如年龄、性别、职业类型等,对推荐系统也有一定帮助,这些信息也有一定的必要进行补充。
当然,以上提到的特征是主要的几类特征,事实上对这些特征的还可以做很多的优化,同时还有很多其他的特征可以进一步提取。在团队精力有限的情况下,先把上述的特征做好就可以达到不错的效果。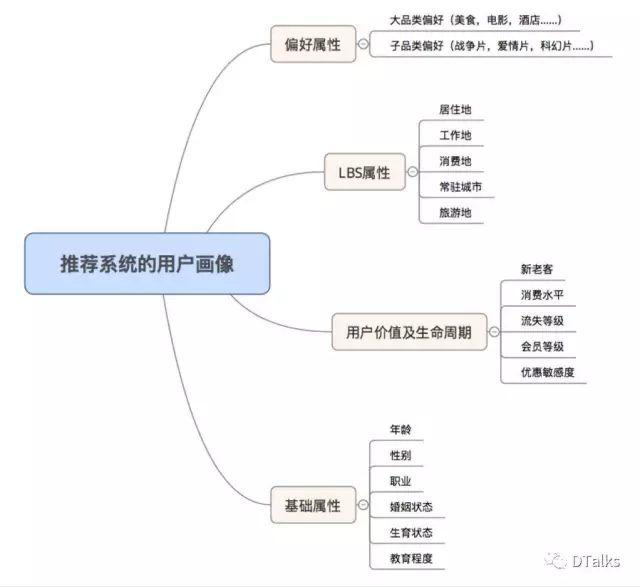
4、属性标签提取的方法
确定需要的用户属性标签以后,对每个属性标签的提取方法,大体分为2类,一类是数据统计的方法;一类是模型预测的方法。
有些标签只需要进行一些数据统计就可以,例如地理位置相关的标签,工作地、居住地、常驻城市等,通常只要统计用户不同时段频繁出没的地点和城市,并辅以一些人工的规则(比如在一个城市停留多久才把这个城市定位常驻城市,什么时段频繁出没算做工作地等)即可。年龄性别的标签,很多公司可能需要通过用户填写的信息或者用户问卷反馈信息来得到一些标注,后期进行模型的训练来对未标注数据进行识别;而对于一些有支付能力的公司,可以从用户填报的身份证信息中获取年龄性别籍贯的信息(当然这里面就存在数据安全这样重大的问题了)。而像前面提到的品类偏好标签,我们有一种提取方法就是用模型去识别的。我们采用的建模方法,是根据用户的历史行为特征来预测他下一次会对哪个品类进行下单,这个品类就是他的品类偏好了。用户的品类偏好实际上是在动态变化的,因此,不能只是统计他过去的下单情况,而要对未来进行预测。
5、效果评估的方法
用户画像团队会开发大量属性标签,这些工作是需要耗费大量的时间和精力的。在追求结果导向的互联网公司,工作量显然不能成为评价工作的指标。那么用户画像的效果如何评价呢?
对于不同的具体任务来说,需要的评估指标是不一样的。这里主要结合推荐系统、广告营销等类型的应用实践来谈谈。用户画像标签在推荐系统、广告营销这类场景上的应用,通常是作为转化(点击、下单等)率预估模型的特征来用。因此,我们主要关心标签加入模型以后,对模型的效果提升有没有帮助。标签建好以后,首先进行离线评估。
对于统计类特征,离线评估有2个重要指标。一是覆盖率指标,就是有多大比例的用户我们能够得到这个属性标签的标签值。通常来说,标签覆盖率如果比较低的话(比如低于50%),这个标签对模型效果的贡献就会受到限制。二是标签有效性指标,这类指标主要目的是衡量特征加入模型以后是否能够在模型中起作用,以及起多大作用。这类指标一般在标签使用方去考虑。但是如果用户画像团队需要主动推动相关业务方使用自己产出的标签的话,自己能计算会有更好的说服力。这个类型的指标较多,有各种相关性指标:余弦相似性、皮尔逊相关系数、卡方检验、互信息等,以及征信评分卡里面喜欢用的IV值等。还可以直接看模型中的特征权重。线性模型(LR,贝叶斯方法等)可以直接得到准确的权重值,树模型一般也能够给出特征权重的参考值(但是并不准确)。对于预测类指标,除了上述2种指标之外,还需要评估预测的准确性。如果是分类问题,例如性别、年龄段、职业类型等,一般用precision,recall,auc等指标;如果是回归问题,则可以根据业务需求选用RMSE,MAPE,MAE等指标。
离线评估完成以后,如果结果符合预期,那么就应该进入线上实验环节了。线上实验一般采用ABtesting的方法。也就是把用户均匀分成2组,一组是使用了该标签的模型或者策略,一组是未使用该标签的模型或者策略,然后看看2组用户的指标差异如何。ABtesting其实是一个挺复杂的工作,从流量分割到数据跟踪到效果评估指标计算,都有很多需要注意的地方。
6、对于非BAT的公司来说,用户画像事情怎么做,怎么衡量投入产 出比?
不管是什么公司,资源都是永远不够的,做任何事情都是需要衡量投入产出比的。用户画像是一个基础工作,因此这个工作是否值得做,主要还是看有没有相关的业务需求,在相关的业务里面能否发挥较大的作用。如果一开始大家判断不好应不应该投入资源到用户画像工作里面去,或者不知道应该投入到用户画像的具体哪个任务里面去,那么可以和做过相关工作的公司或者团队学习,了解用户画像的哪个方向的工作能够产生的价值较大(例如美团的品类偏好属性,LBS属性就对推荐业务产生了很大的作用)。另外一定要多和业务感觉好的同学交流,这样会得到很多有价值的信息,对用户画像的工作会有很好的指导。
以下是沈国阳老师回答提问部分的完整内容
Q1、「黄方胜:在用户比较少的情况,user persona可能比较合适,这个实践能分享下吗?」
回答:这个主要是要找准目标用户,然后去做深入的调研。我在百度移动互联网事业部工作的时候,他们就很重视用户调研,会到广东的工厂去做大量的用户访谈,因为当时移动互联网的主要用户群体之一就是农民工。另外还有一招是把目标用户转化成产品经理,百度早期喜欢从网吧里面寻找产品经理,就是这个道理。所以百度早期产品做得还不错。
Q2、「 王小久-bi-游戏-上海: 想了解一下数据库如何准备?初创团队,目前只有日志的积累,如何迈出最初的第一步?」
【分享嘉宾】有日志的积累,这个就有基础了。迈出第一步,关键就是寻找业务落脚点,你要看你准备在哪个场景用,然后和那个业务场景的负责人,研发人员沟通,看看他们最需要了解用户哪方面的信息
【顾青 DTalk.org创始人】这个话题涉及数据采集(包括前端埋点、后端日志、数据清洗、数据标签产品、数据分析产品、数据可视化产品等),但是首先你需要把数据采集和数据整合做好.
Q3、「 Courage_sen: 征信风控模型建模一般根据什么指标进行建模」
这个用户历史的征信记录是重点,也会利用用户在平台上面的消费行为数据进行分析,还有其他一些独特的特征,不过这种涉及公司安全是不能分享的。4、对于像汽车这类大宗,高额,低频的品类会有哪些标签更重要呢?
Q4、「 张天-博郡汽车-上海: 对于像汽车这类大宗,高额,低频的品类会有哪些标签更重要呢? 」
这个比较专业了,我对这个业务接触得不多。而且需要看具体业务场景。如果是做汽车推荐的话,我建议看看用户的收入水平,消费能力,品牌偏好等
Q5、「 天祺: 怎样保障用户画像的精确度? 」
这个精确度我理解主要指预测类标签的精确度。这种标签的预测依赖于其他的特征/标签,同时需要有准确的标注数据,有足够的数据量,然后用合适的模型来建模预测。
Q6、「 沙沙-会员营销-北京: 上线前如何评价推荐模型优劣?推荐产品和预订产品的命中率?多少算达标呢?」
上线前的评估就是离线评估,离线评估的标注数据其实是来自于线上的真实数据。有了这些标注数据,我们会把模型预测的结果和标注的真实结果进行比较,计算precision,recall,或者auc等指标。推荐的命中率多少算达标应该没有一个标准答案,一般是会给一个简单的策略做baseline,后面迭代过程中不断提高。早期应该会有倍数的提高
Q7、「李静Jing-博郡汽车-上海:沈老师,请问用户画像的“个性”和“共性”怎么有效取舍或者结合?」
userprofile是对用户个性的描述,但是放到模型里面去以后,模型会想办法去把相似的用户放到一起去思考,通过和这个用户有共同特征的用户来预测当前用户的行为,我想这就是一种结合。不知道这是不是你想表达的意思
Q8、「letv-crm-茜茜:用户未来喜好如何做预测?可否分享一下成功案例?」
我们之前做过一版是这样的:把用户过去一段时间(比如60天)的行为记录作为特征(比较简单的方法是把用户对物品的点击或者下单行为做成特征向量),把用户接来下的发生行为的品类(例如:接下来下单的物品的品类) 作为用户未来偏好的标注,这样形成样本作为模型的输入,训练好模型以后,把用户最近60天的行为作为特征输入给模型,就可以预测他下一次行为的偏好了。
Q9、「烽火普天-孙天祺-ImageQ负责人:这是已有数据的用户最难突破的,各种渠道获取的数据都是不一样的格式,也很难做到统一。用户画像也是很多的,一个用户多个画像,怎样确保是用一个人呢?」
确保每个用户都对准确实比较困难,除非每个平台上都用用户的身份证号作为主键。如果没有身份证号,可以利用手机号,银行卡,邮箱等进行关联。
Q10、「烽火普天-孙天祺-ImageQ负责人:关键在于目前用户画像大多都是都是分散的,汇总的也只是大概率是而已。除非征信数据是最靠谱的。除此之外真的好无法打通各自的数据壁垒。」
有赖于各个平台制定统一标准。据我了解,央行征信接口是要求上报证件号的,如果每家都按照央行征信接口的规范来存储数据(不管接入还是不接入央行征信),那么数据打通的问题就解决了。
Q11、「唐浮云:标签的有效性指标中,提到了卡方检验等很多统计学的理论知识,这一部分在实际营销过程中,有没有例子可以参考学习那?谢谢老师~」
关于卡方检验,网上资料比较多。例如:https://segmentfault.com/a/1190000003719712
Q12、「复星大数据-姜辰希Selina:除了第一梯队互联网公司积累了海量数据以外,其他中小型企业数据积累有限。仅从自身场景进行挖掘出的画像或标签是否会存在严重偏差,是否能起到指导运营的效果?是否应着重考虑外部合作?」
我认为还是要立足自身,除非自己有很关键的数据是其他公司需要的,可以进行数据交换的合作,否则很难获得其他公司的数据。据我了解,基本上大部分平台的用户的行为频次都是服从长尾分布的,总有一些头部用户行为比较密集,大部分长尾用户行为很稀疏。所以依赖统计的用户画像标签总是只对部分人效果较好,对很大一部分人效果较差。
Q13、「 人民日报新媒体中心的产品赵宇威: 老师,您好,我的理解是对于用户的喜好偏好实体集很好做,但是预测集就很难了,就像今日头条,他会用数据来训练模型,神经元,二分类,不断矫正系数,但是如果没有那么大量的数据训练模型怎么办?」
线下沟通了解到该用户的实体集是指通过行为数据统计出来的用户画像标签。预测集是指根据用户的历史行为预测他接下来可能喜欢什么。数据量不够确实没法做模型预测,需要不断累积数据。
Q14、「 人民日报新媒体中心的产品赵宇威: 请教老师关于做征信,确定模型后,但是很多个体的数据源各个渠道,比如爬虫啊等等,但是如果有拿不到的数据,那这个指标项在模型里怎么处理呢」
如果所有样本都拿不到这一维度的数据,那就相当于整个模型少了一个维度。只要其他维度还在影响也不大。如果是只有一部分样本拿不到这一维度的数据,那么是可以有缺失值处理的办法的。常用的是中位数,平均数等进行填充。
干货专访和文章
【DTalk精华】网易郑栋:前端数据采集与分析的那些事第一弹: 从数据埋点到AB测试
【DTalk精华】滴滴出行谯洪敏:前端数据采集与分析的那些事第二弹:企业如何选择自动埋点和可视化埋点
【DTalk精华】滴滴出行谯洪敏:前端数据采集与分析的那些事第三弹:埋点需求整理原则于埋点流程规范
【DTalk专访】滴滴谯洪敏:百家争鸣的前端技术时代
【DTalk思考】顾青:互联网团队的数据驱动能力从哪里来?
【DTalk专访】彭圣才:AI超越人类大脑,是一场「別有用心者」的骗局吗?
【DTalk专访】翁嘉颀:AI行业现阶段最需要什么样的人才?
【DTalk专访】赵华:携程怎么把机器学习与实际业务相结合?
【DTalk专访】网易郑栋:BI、可视化数据产品和大数据的几个核心问题
【DTalk回顾】美团点评沈国阳:我们在谈用户画像的时候到底在谈什么?
【DTalk专访】王晔:谷歌数据如何用于决策?
作者:叨叨侠爱叨叨
链接:https://www.jianshu.com/p/f52f898b40c2
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

若有收获,就点个赞吧
0 人点赞
