近日,爱奇艺研发了适用于影视剧配音场景的智能配音系统:奇声(IQDubbing)影视剧智能配音系统。该解决方案基于多种自研 AI 技术,并以 Voice Conversion 为核心技术,提供了多语种、多音色的 AI 配音功能,具有高表现力、高自然度等优点,已经落地于情感丰富的影视剧配音场景,多部影片已成功上线爱奇艺国内国外站点。
系统的亮点
1、多语种:已支持包括中文普通话、泰语、越南语在内的多个语种配音;
2、多音色:根据影视剧角色类型,已支持男女全年龄段,同时支持多个不同人设音色,如干练女强人、知性淑女、磁性霸总、阳光男孩等多达 50 多种不同音色的模型;
3、高表现力:对于影视剧场景中常见的喜怒哀乐抑扬顿挫可以高细腻度还原;
4、高自然度:媲美真人的高保真音质和自然度,很好地保留输入的情感和内容。
01
项目背景
奇声的研发基于实际的业务场景需要,团队深入了解了配音行业,发现有很多亟待解决的问题:
1、待配音的影视剧数量大
经过调研,近 5 年来,我国从国外引入的电影超过 2000 部,而仅有极少数院线电影有中文配音版本,而国内有大量的用户有中文普通话的观影需求。另一方面,国内几家主要的视频平台,都有出海的策略,巨大数量的优秀国产影视剧集需要出海,需要做本地化配音,如泰语、越南语等。这两方面的需求加起来是一个巨大的工作量和巨大的成本。
2、音色难匹配
一部电影通常有很多角色,角色稍微丰富些的可以达到 20 多个,而电视剧的角色则更加丰富。为这些影视剧角色寻找合适的配音音色是一件困难的工作,而为小语种配音寻找合适的音色则是难上加难。
3、配音员稀缺
影视剧配音在要求配音演员音色符合角色的人设外,还要求对角色有很好的情感演绎能力,这点比有声书配音的要求高了不少,从而导致符合要求的影视剧配音演员成为稀缺资源。而优秀的小语种配音演员则更加稀缺。
4、国际声问题
国际声是制作影视剧配音的前提,而很多影片并没有国际声,因此如何获取或者制作国际声则成为制约配音影片的重要因素。
为了解决业务面临的问题,我们研究并开发了奇声(IQDubbing)智能配音系统,自研了多个 AI 模型,并通过配音管理平台将多个 AI 模型嵌入到配音业务的流程中,为业务赋能。
02
解决思路
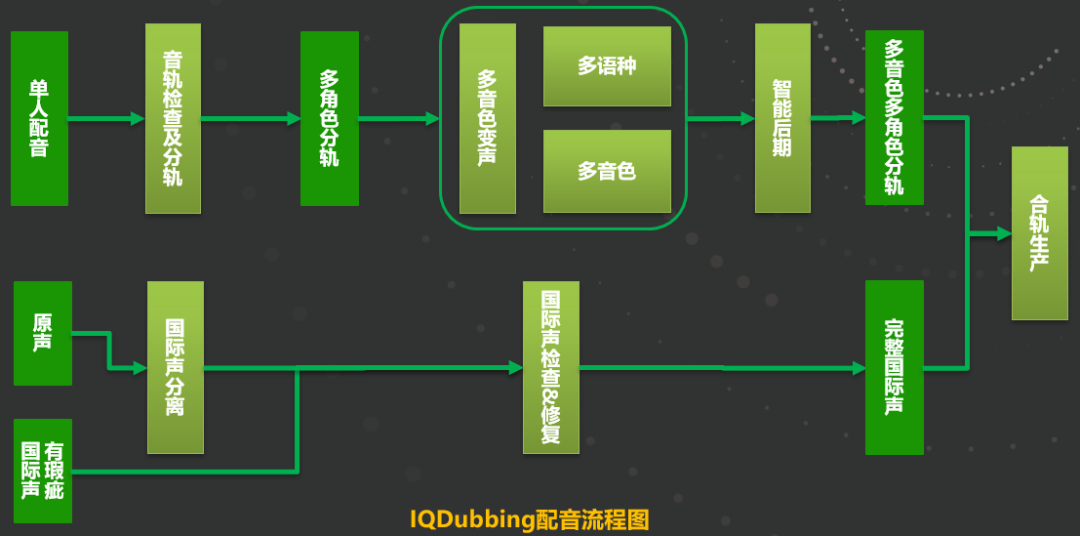
系统流程
1、对白轨制作:使用单人配音员进行单人配音,得到单人音轨后,使用奇声音轨检查及分轨工具,对音轨进行初步处理。该功能包含了多个智能化功能,如分轨检查等。通过检查后,得到了按照角色的分轨,并使用该系统的核心功能,多语言多音色的变声模型,根据所选择的音色模型,将原始的单音色音轨变声为对应的多角色音轨;
2、国际声制作:对于没有符合要求的国际声,我们通过AI模型进行修复和制作,使得国际声达到上线标准;
3、合轨生产:将制作好的对白轨和国际声进行合轨生产,同时进行音画同步等必要的检查。
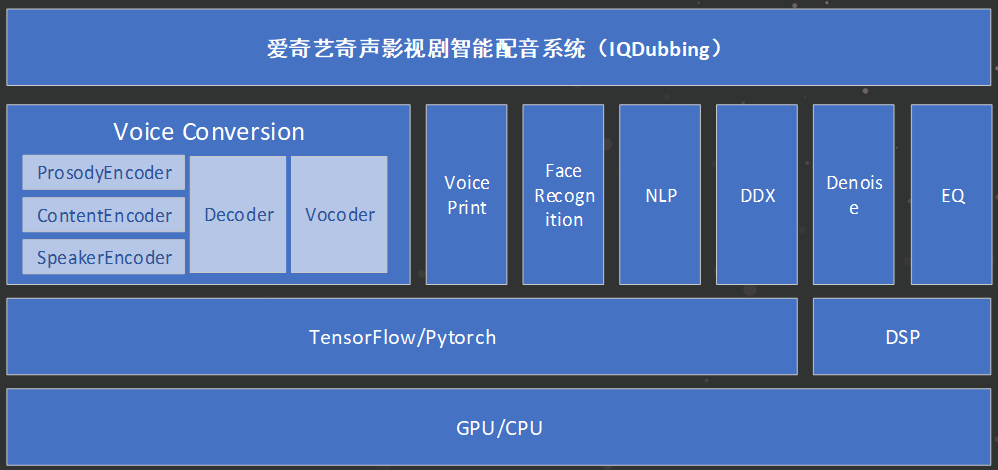
奇声技术框架
- 硬件层:根据不同的需求以及所运行的算法模型,整个系统可同时支持使用GPU和CPU;
- 框架层:整个系统包含了多个AI模型,在框架上则使用了TensorFlow和Pytorch,同时也使用了传统的数字信号处理;
- 应用算法层:算法层包含了多个AI模型,其中核心模型是基于深度学习的AI变声模型。另外,基于场景需求,奇声系统还包含了如声纹识别、人脸识别、NLP等多种算法,同时还包含了如降噪、EQ等多个传统的DSP算法;
- 系统层:通过对业务逻辑的调研,我们将AI配音的业务逻辑流程化,可实现“一键质检”、“一键选音”、“一键制作”等。
03
算法介绍
VC 技术介绍
奇声配音系统的核心算法是 Voice Conversion(VC)模型,和传统的基于 DSP 变声不同,AI 变声是基于深度学习来实现声音转换,可对声音进行定制,并极大程度地保留原始音色和情感。
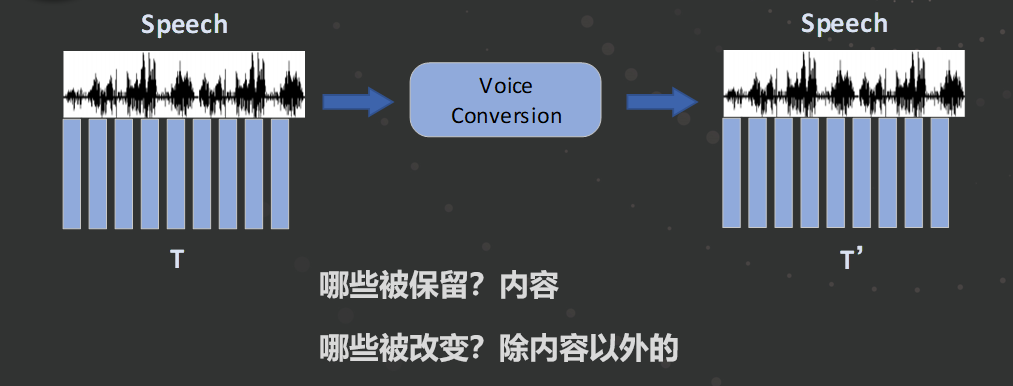
Voice Conversion 如上图所示,是将一种语音变换成另外一种语音,在变换过程中,说话的内容被保留,其他信息都是可以被改变的。而在奇声配音 VC 中,说话人的内容和韵律均被保留下来,从而达到一人配多人的效果。
奇声 VC 介绍
奇声 VC 主要针对影视剧的配音场景,因此,其关注点与其他变声模型有所不同。奇声 VC 更加关注对输入说话人的情感和韵律的还原,而对于音色的还原度要求并不高。针对此特殊情况,我们对模型和语料都进行了针对性地处理。
- 语料优化
对于配音音色语料,我们根据使用场景进行了设计:
1、有效地利用原有 TTS 语料:大量使用原有的 TTS 的neutral 语料和情感语料,作为基础语料用于声码器训练;
2、针对性地设计配音音库:针对影视剧中不同类型的音色需求,挑选不同角色、不同风格类型、不同情绪的对白作为语料,如干练女强人、阳光男孩、磁性霸总等多种不同音色,同时对每种类型的音色录制不同情感的语料。
- 模型优化
配音变声模型有别于其他的变声模型,如娱乐向的变声模型可能更加注重对原始音色的还原度,比如定制某个用户的音色。但是配音变声模型更加注重对于情感和韵律的还原度,因此我们的变声模型进行了多轮的迭代。
第一代框架:整体上基于 recognition-synthesis 框架,通过基于 Tacotron 合成框架进行变声模型的训练。为了实现变声效果,模型对说话人信息、内容等特征进行了分离,并将音色进行了替换。我们发现,声码器对于最后的输出效果有着至关重要的作用,特别是音质,常见的声码器有 STRAIGHT,Griffim Lim,MelGAN 等。我们尝试了多种声码器,最后决定使用基于 GAN 的声码器进行语音重建,得到了较好的效果。
第二代框架:通过对第一代框架在实际场景中的使用效果的观察,我们发现,第一代框架最明显的问题在于表现力较弱,韵律的还原度较差。因此,我们在第一代框架的基础上,对韵律和情感的细腻程度进行了有效的优化:
1. 在原有框架上对韵律建模进行了增强。通过对比试验发现,优化后的模型在情感表现力方面有了明显的增强。
2. 对语音处理的颗粒度进行了增强,提高了时间分辨率。通过对比试验发现,优化后的模型在情感的细腻程度和发音准确性有了很大的提高。
通过对不同语种、不同风格的音库进行优化,奇声在中文普通话、泰语、越南语的影视剧AI配音效果上都得到了很好的提升。
《鲨卷风5》中文普通话AI配音
《赘婿》越南语AI配音
《青簪锁三千》泰语AI配音
04
奇声测评体系
影视剧配音质量高低主观感受占主要因素,因此,我们在技术和业务两个维度建立了测评体系:
1、技术维度测评
- 测评角度:纯技术角度测评
- 测评方式:
- 中文普通话、泰语、越南语的Local Speaker进行听测
- 采用MOS打分机制
- 测试集:
- 设计了多维度的测试集
- 多语种:中文普通话、泰语、越南语
- 多分类:性别、年龄、音色风格、情绪
- 数据来源:影视剧集
2、业务维度
- 测评角度:普通用户角度测评
- 测评方式:
- 对应语种的普通用户听测
- 对普通用户可感知的错误进行测评:如发音错误、情感不到位等
- 测试内容:
- 待上线的AI配音影视剧
05
总结
在实际使用过程中,我们根据业务反馈反复优化音色模型,使得配音效果逐步提高,同时在音库种类上也逐步丰富。现在已支持中文普通话、泰语、越南语三种语言音色,每种语言音色模型除了支持男女老少分类外,还支持各种类型细分类,如干练女强人、知性淑女、活泼萝莉、阳光男孩等多种影视剧常见类型。
多种 AI 配音音色
在实际使用中,我们还发现真人配音常常出现原声与角色人设不匹配的情况,使用奇声配音系统可以对真人音色进行“美化”。
音色美化前
音色美化后
上线效果
奇声智能配音系统发布后,已经有超过60部电影以及200多集电视剧分别在爱奇艺中文电影频道和爱奇艺海外站上线,收到了很好的观影效果。

007 大战皇家赌场
007黑日危机
唐门 美人江湖泰语版
老九门 青山海棠 泰语版
获得的奖项
在奇声配音系统的研究过程中,已经收获了包括 ICASSP,InterSpeech 会议在内的 3 篇语音类顶级会议论文,10+ 个发明专利,5 个软件著作权。同时,也获得了 ChinaMM2022 “中国多媒体企业创新产品”奖,得到了业界的认可。
参考文献:
[1] Skerry-Ryan R J, Battenberg E, Xiao Y, et al. Towards end-to-end prosody transfer for expressive speech synthesis with tacotron[C]//international conference on machine learning. PMLR, 2018: 4693-4702.
[2] Lian Z, Zhong R, Wen Z, et al. Towards fine-grained prosody control for voice conversion[C]//2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP). IEEE, 2021: 1-5.
[3] Baevski A, Schneider S, Auli M. vq-wav2vec: Self-supervised learning of discrete speech representations[J]. arXiv preprint arXiv:1910.05453, 2019.
[4] Huang W C, Wu Y C, Hayashi T. Any-to-one sequence-to-sequence voice conversion using self-supervised discrete speech representations[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 5944-5948.
[5] Watanabe S, Hori T, Karita S, et al. Espnet: End-to-end speech processing toolkit[J]. arXiv preprint arXiv:1804.00015, 2018.
[6] Wang Z, Zhou X, Yang F, et al. Enriching source style transfer in recognition-synthesis based non-parallel voice conversion[J]. arXiv preprint arXiv:2106.08741, 2021.
[7] Li Z, Tang B, Yin X, et al. Ppg-based singing voice conversion with adversarial representation learning[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 7073-7077.
[8] Kim J H, Lee S H, Lee J H, et al. Fre-GAN: Adversarial frequency-consistent audio synthesis[J]. arXiv preprint arXiv:2106.02297, 2021.
[9] Yamamoto R, Song E, Kim J M. Parallel WaveGAN: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram[C]//ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 6199-6203.
[10] Z. Wang, W. Ge, X. Wang, S. Yang,W. Gan, H. Chen, H. Li, L. Xie and X. Li. Accent and Speaker Disentanglement in Many-to-many Voice Conversion[C]// 2021 12th International Symposium on Chinese Spoken Language Processing (ISCSLP)
[11] Z. Wang, X. Zhou, F. Yang,T. Li, H. Du,L. Xie,W. Gan, H. Chen and H. Li. Enriching Source Style Transfer in Recognition-Synthesis based Non-Parallel Voice Conversion[C]// InterSpeech 2021
[12] Q. Xie, X. Tian, G. Liu, K. Song, L. Xie, Z. Wu, H. Li,S. Shi, H. Li, F. Hong, H. Bu, X. Xu. THE MULTI-SPEAKER MULTI-STYLE VOICE CLONING CHALLENGE 2021[C]// 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)

若有收获,就点个赞吧
0 人点赞
