比赛内容
本次题目围绕电商领域搜索算法,开发者们可以通过基于阿里巴巴集团自研的高性能分布式搜索引擎问天引擎(提供高工程性能的电商智能搜索平台),可以快速迭代搜索算法,无需自主建设检索全链路环境。
本次评测的数据来自于淘宝搜索真实的业务场景,其中整个搜索商品集合按照商品的类别随机抽样保证了数据的多样性,搜索Query和相关的商品来自点击行为日志并通过模型+人工确认的方式完成校验保证了训练和测试数据的准确性。
比赛数据

corpus.tsv
- 介绍:语料库,从淘宝商品搜索的标题数据随机抽取doc,量级约100万。
- 格式:doc_id从1开始编号的,title是是商品标题。 ```java 1 铂盛弹盖文艺保温杯学生男女情侣车载时尚英文锁扣不锈钢真空水杯 2 可爱虎子华为荣耀X30i手机壳荣耀x30防摔全包镜头honorx30max液态硅胶虎年情侣女卡通手机套插画呆萌个性创意 3 190色素色亚麻棉平纹布料 衬衫裙服装定制手工绣花面料 汇典亚麻
<a name="m1YVY"></a>### train.query.txt- 介绍:训练集的query,训练集量级为10万。- 格式:query_id从1开始编号,query是搜索日志中抽取的查询词。```java1 unidays2 溪木源樱花奶盖身体乳3 除尘布袋工业
qrels.train.tsv
- 介绍:训练集的query与doc对应关系,训练集量级为10万。
格式:query_id和doc_id。数据来自于搜索点击日志,人工标注query和doc之间具备高相关性,训练集用来训练模型。
1 282 373 51
dev.query.txt
介绍:测试集的query,测试集量级为1000。
格式:query_id和query,训练集id从1开始编号,测试集id从200001开始编号,query是搜索日志中抽取的查询词。
200001 鈴木雨燕方向機總成200002 福特翼搏1.5l变速箱电脑模块200003 a4红格纸
评价指标
本次比赛采用MRR指标来评测选手基于HA3构建搜索系统的检索效果:
赛题建模
赛题是一个文本检索任务:给定一个搜索查询,我们首先使用一个检索系统来检索得结果。但检索系统可能会检索与搜索查询不相关的文档,整体的任务可以参考已有的文本语义检索。
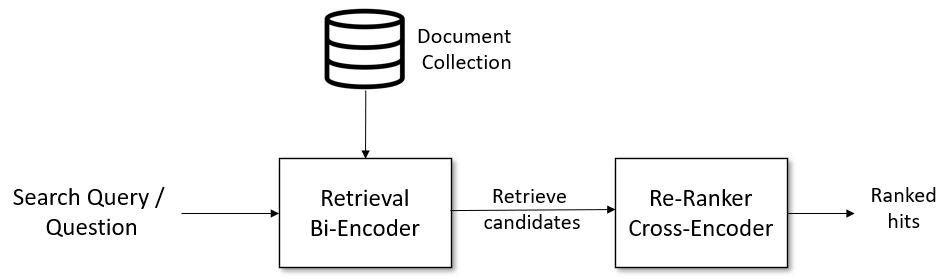
赛题难点分析
赛题的query比较短,属于非对称语义搜索(Asymmetric Semantic Search)任务,有一个简短的查询,希望找到一个较长的段落来回答该查询。赛题的query与corpus的文本可能存在并无重合单词的情况。
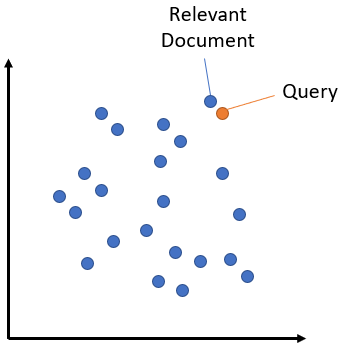
赛题解题思路
思路1:使用关键词匹配,识别出query和corpus中关键词,使用关键词进行编码为向量。
- 思路2:使用sentence-bert结合比赛标注数据进行训练
-
部分代码
文本分词 ```java def title_cut(x): return list(jieba.cut(x))
from joblib import Parallel, delayed
corpus_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in corpus_data[“title”]) train_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in train_data[“title”]) dev_title = Parallel(n_jobs=4)(delayed(title_cut)(title) for title in dev_data[“title”])
- 训练词向量```javafrom gensim.models import Word2Vecfrom gensim.test.utils import common_textsif os.path.exists("word2vec.model"):model = Word2Vec.load("word2vec.model")else:model = Word2Vec(sentences=list(corpus_title) + list(train_title) + list(dev_title),vector_size=128,window=5,min_count=1,workers=4,)model.save("word2vec.model")
句子编码
def unsuper_w2c_encoding(s, pooling="max"):feat = []corpus_query_word = [x for x in s if x not in drop_token_ids]if len(corpus_query_word) == 0:return np.zeros(128)# N * 128feat = model.wv[corpus_query_word]if pooling == "max":return np.array(feat).max(0)if pooling == "avg":return np.array(feat).mean(0)
历年比赛题目:https://mp.weixin.qq.com/s/gxCxv6jUCwYGblFAjSCFQA
参考:https://github.com/datawhalechina

若有收获,就点个赞吧
0 人点赞
