(1)IK分词插件安装与验证
分词器地址:
https://github.com/medcl/elasticsearch-analysis-ik
拼音分词:
https://github.com/gitchennan/elasticsearch-analysis-lc-pinyin
1.IK analyzer插件包的下载地址:https://elasticsearch.cn/download/
2.插件安装过程
进入到/opt/modules/elasticsearch/plugins目录下
创建ik目录mkdir ik
将下载好的插件解压到ik目录下unzip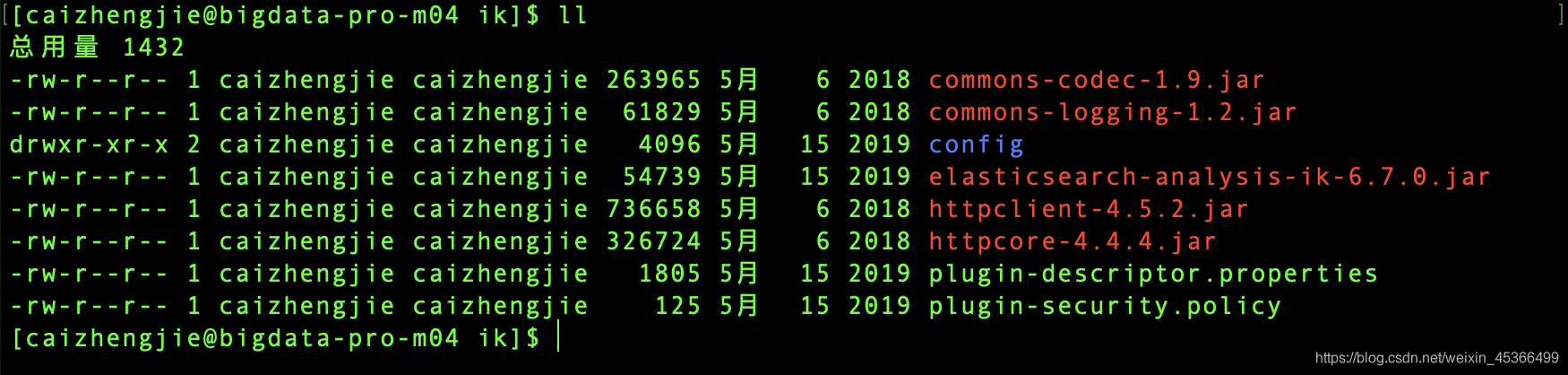
3.重启ES服务
bin/elasticsearch
4.启动kibana服务进行IK分词器的验证
测试词:中华人民共和国
ES分词器搜索效果: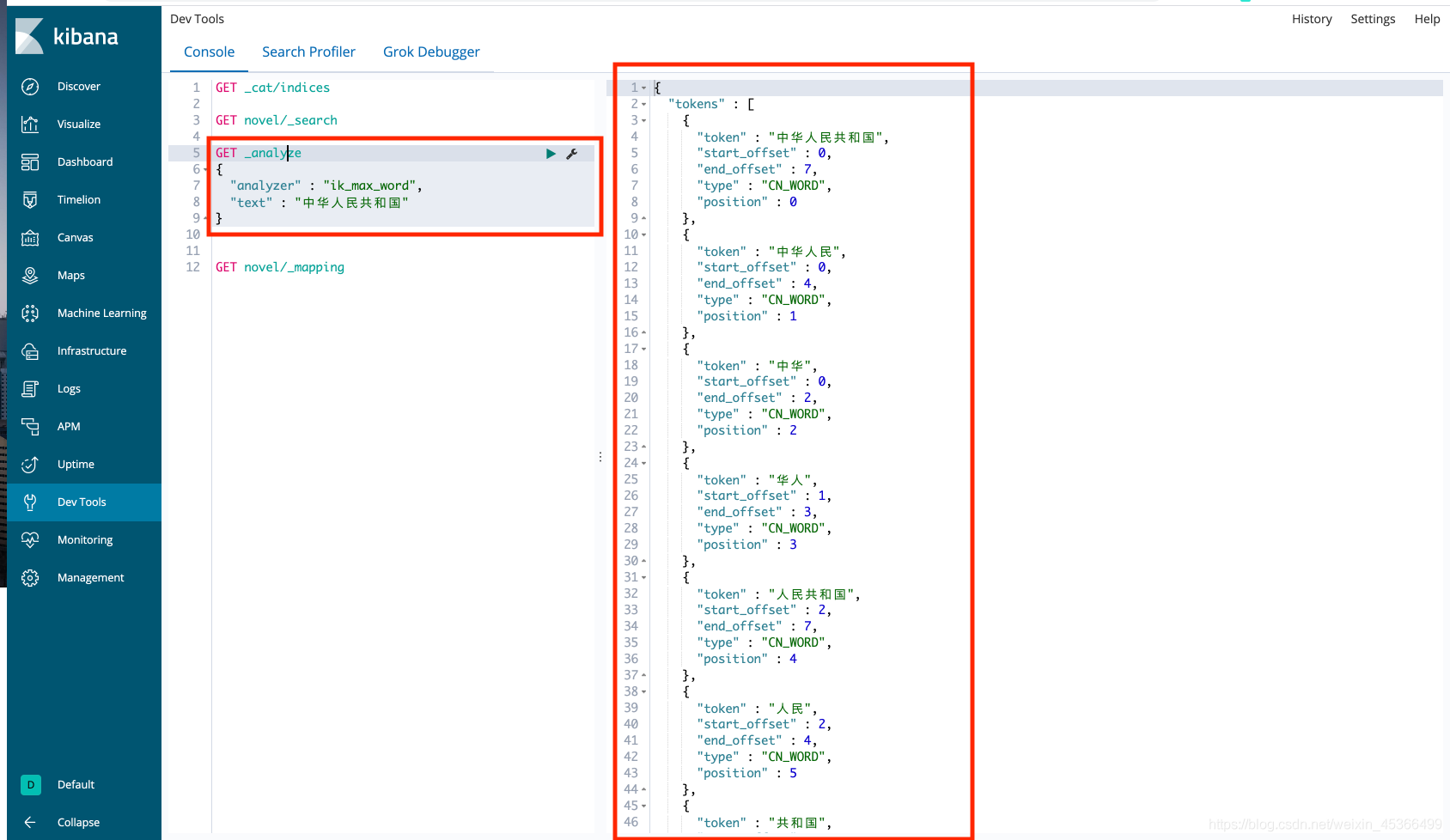
(2)IK自定义词库扩展配置
在对分词做配置的时候,我们可以根据自己的需求做分词,比如:
卡弗卡大数据 -> 卡弗卡 大数据
在config目录下创建配置自己的扩展字典my.dic
vim my.dic卡弗卡大数据
修改配置文件:ik/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">my.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
重启ES服务,通过kibana验证: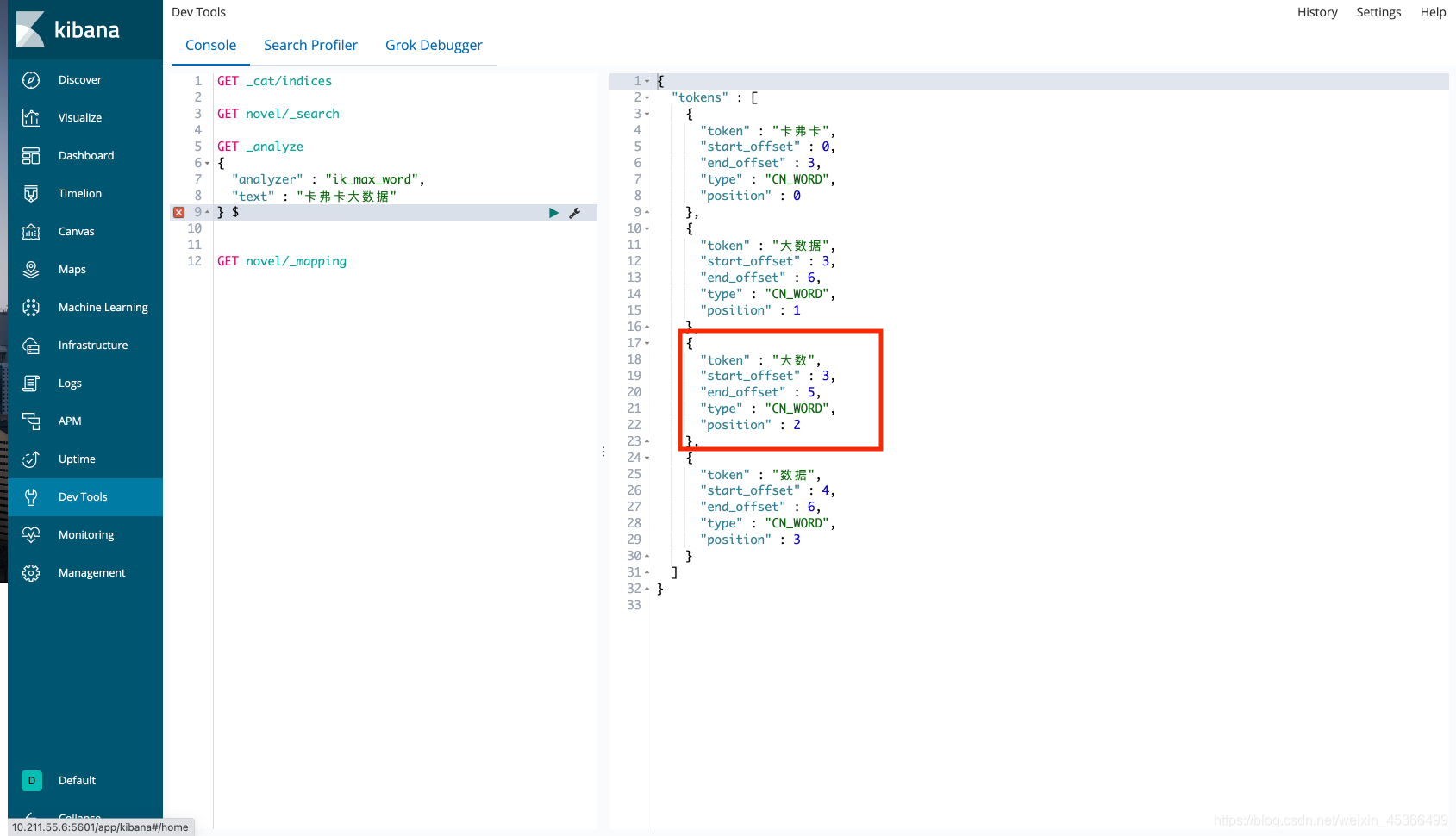
确实起到了自定义分词的效果,但是【大数】不是我们想要的分词
我们可以配置自己的扩展停止词字典my_stop.dic:
vim my_stop.dic大数
修改配置文件:ik/config/IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"><properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">my.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">my_stop.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> --></properties>
再次验证达到我们想要的效果: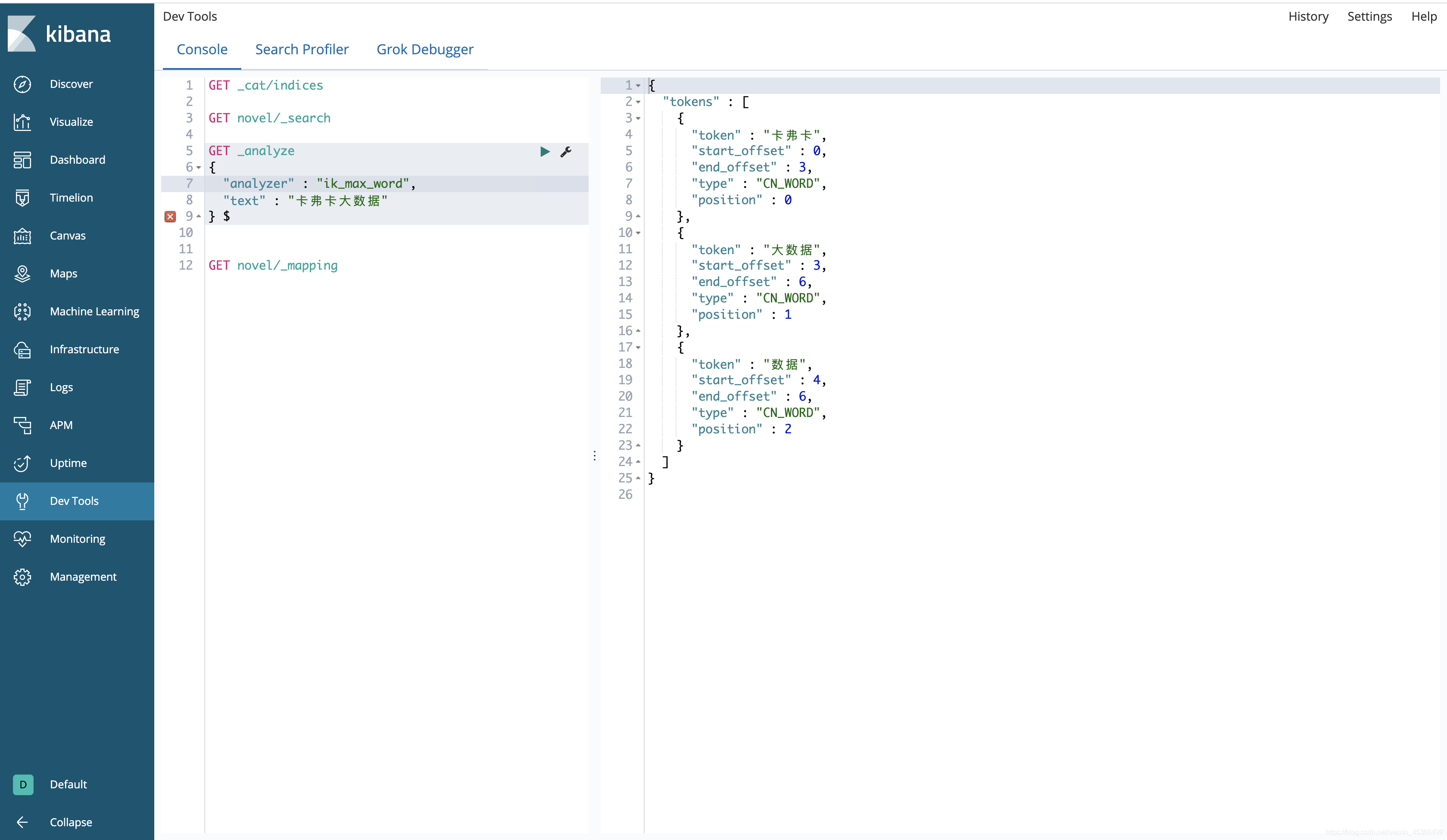
(3)创建ES索引和Mapping
1.重新创建es索引
我们在初始化导入ES数据的时候,自动生成的mapping,现在我们要进行分词搜索,必须要重新构建mapping,不能修改原有的mapping,只能重新创建一个新的mapping。
GET novel/_mapping
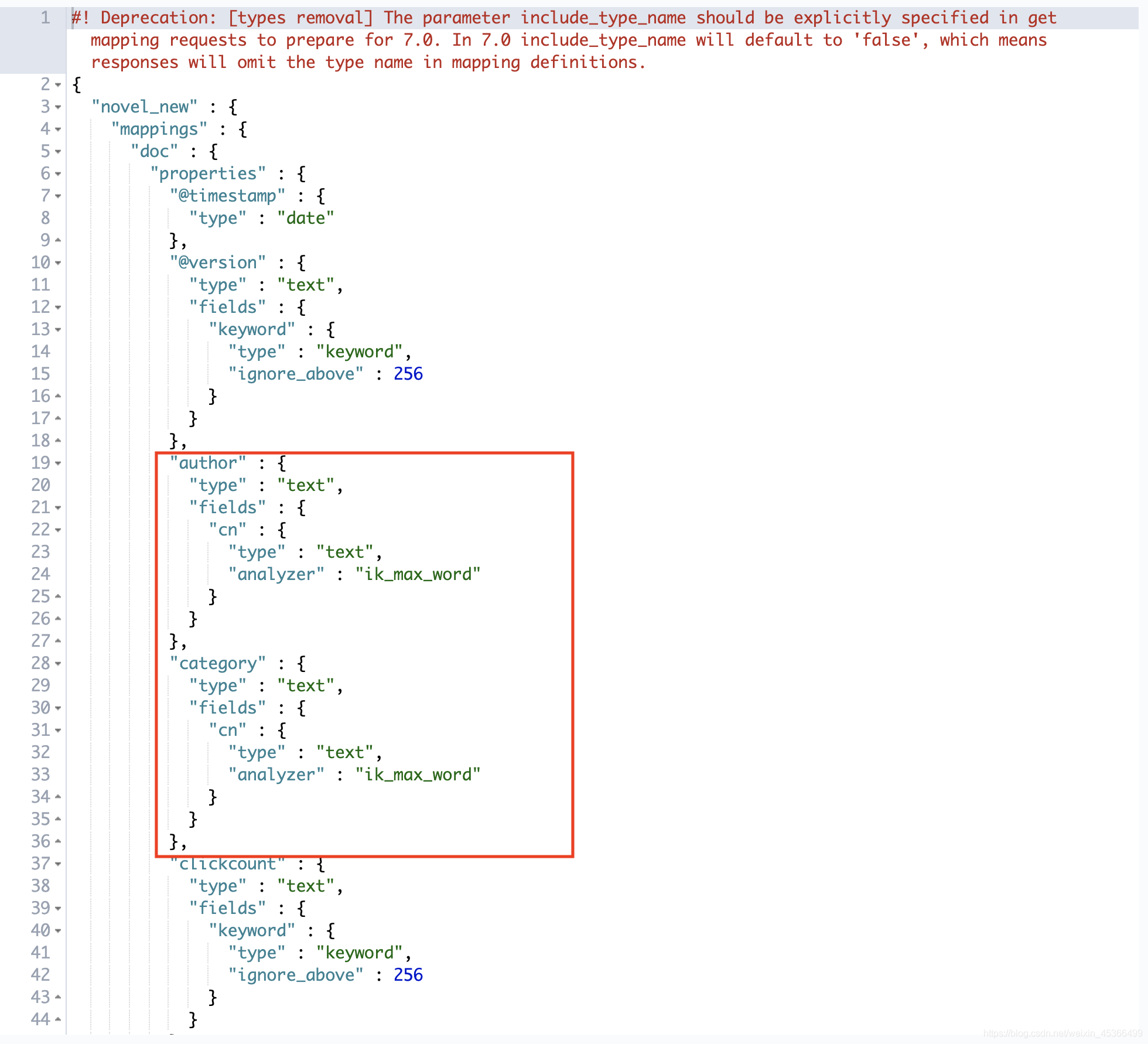
拷贝内容,修改内容如下:
修改四个部分:“name”, “category”, “author”, “novelinfo”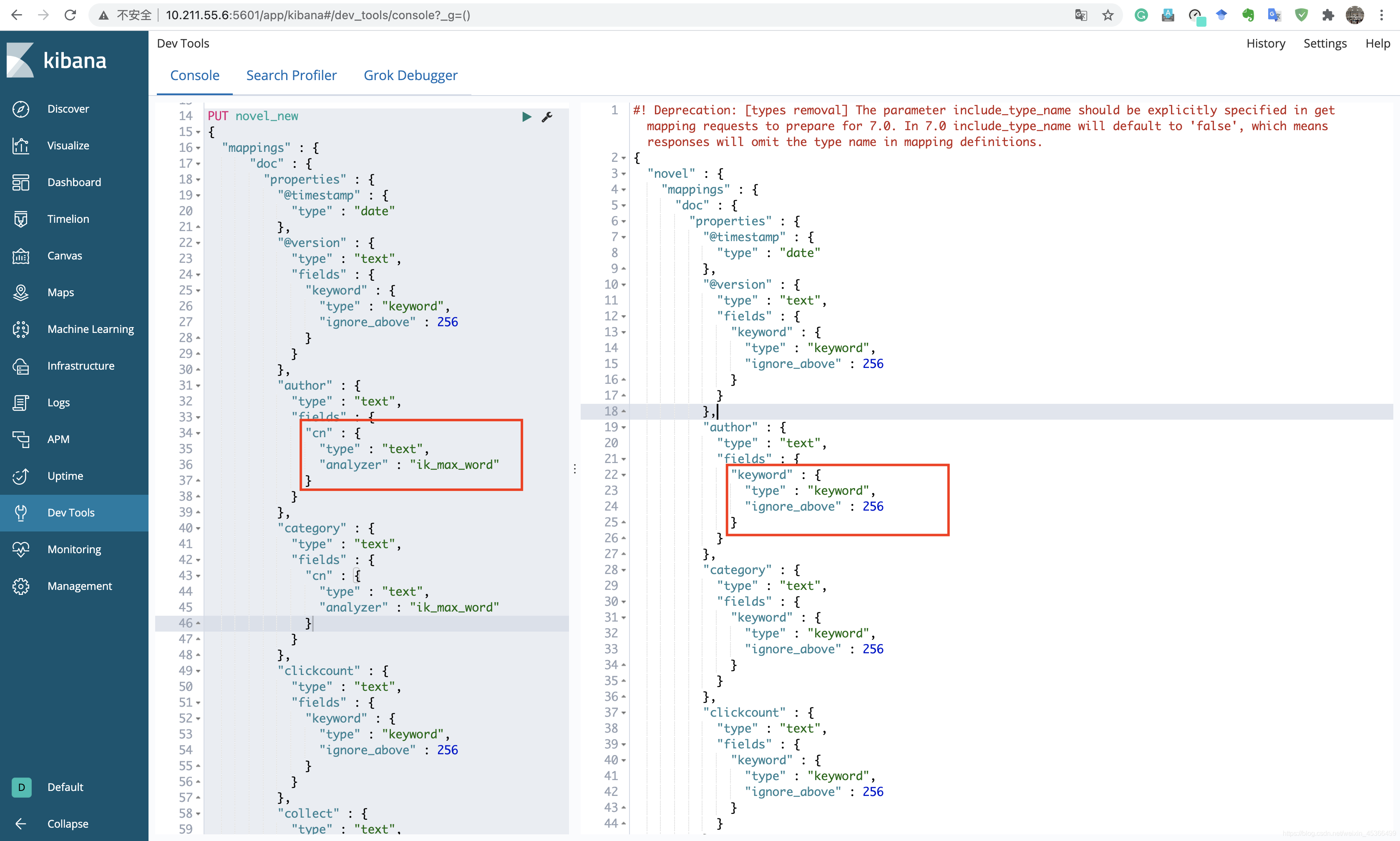
2.数据加载到新创建的索引上:novel_new
POST _reindex{"source": {"index": "novel"},"dest": {"index": "novel_new"}}
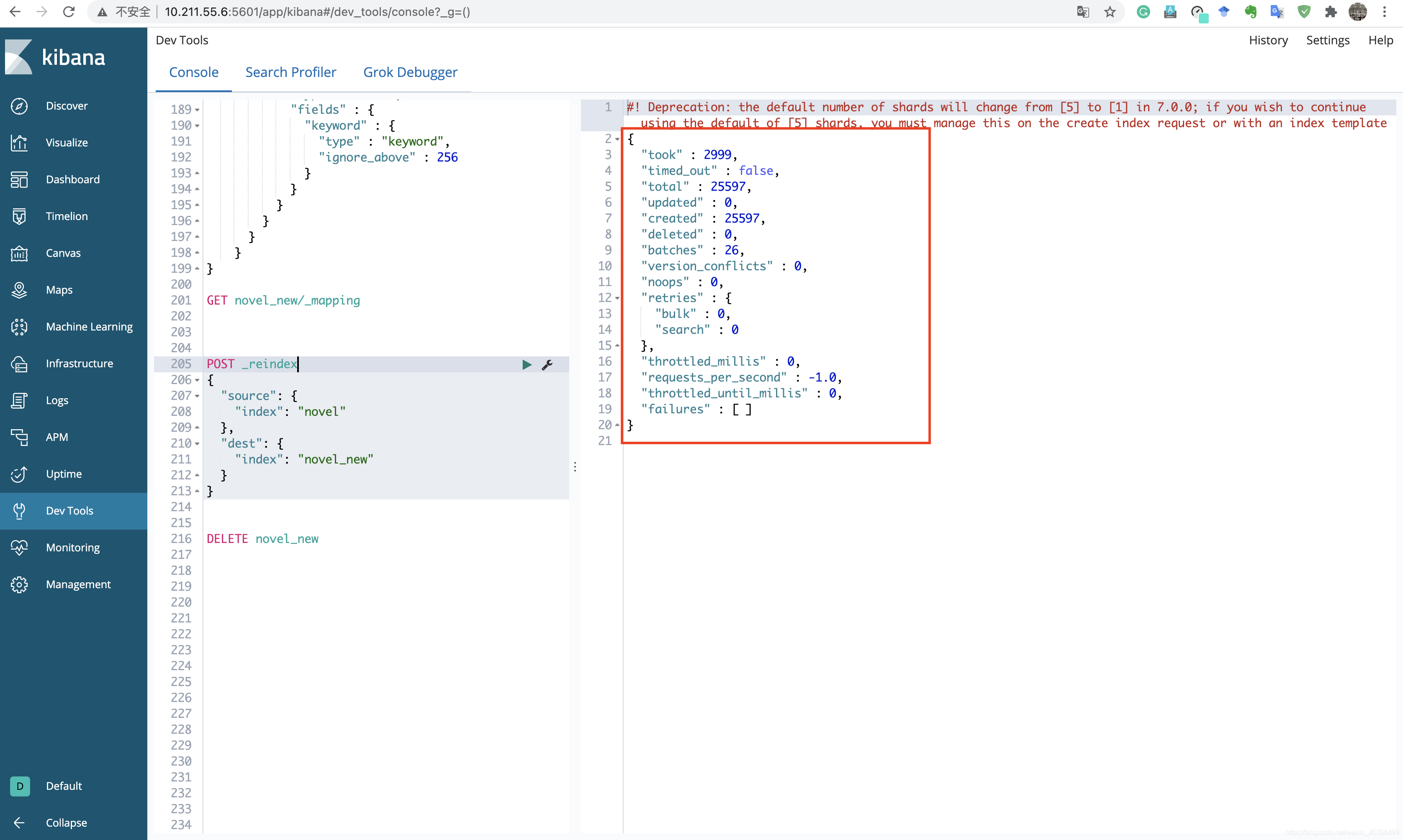
3.给索引创建别名,为了让程序代码不动,我们创建别名novel
# 删除novelDELETE novelGET _cat/indices# 创建别名,程序代码不动POST _aliases{"actions": [{"add": {"index": "novel_new","alias": "novel"}}]}
分词搜索效果: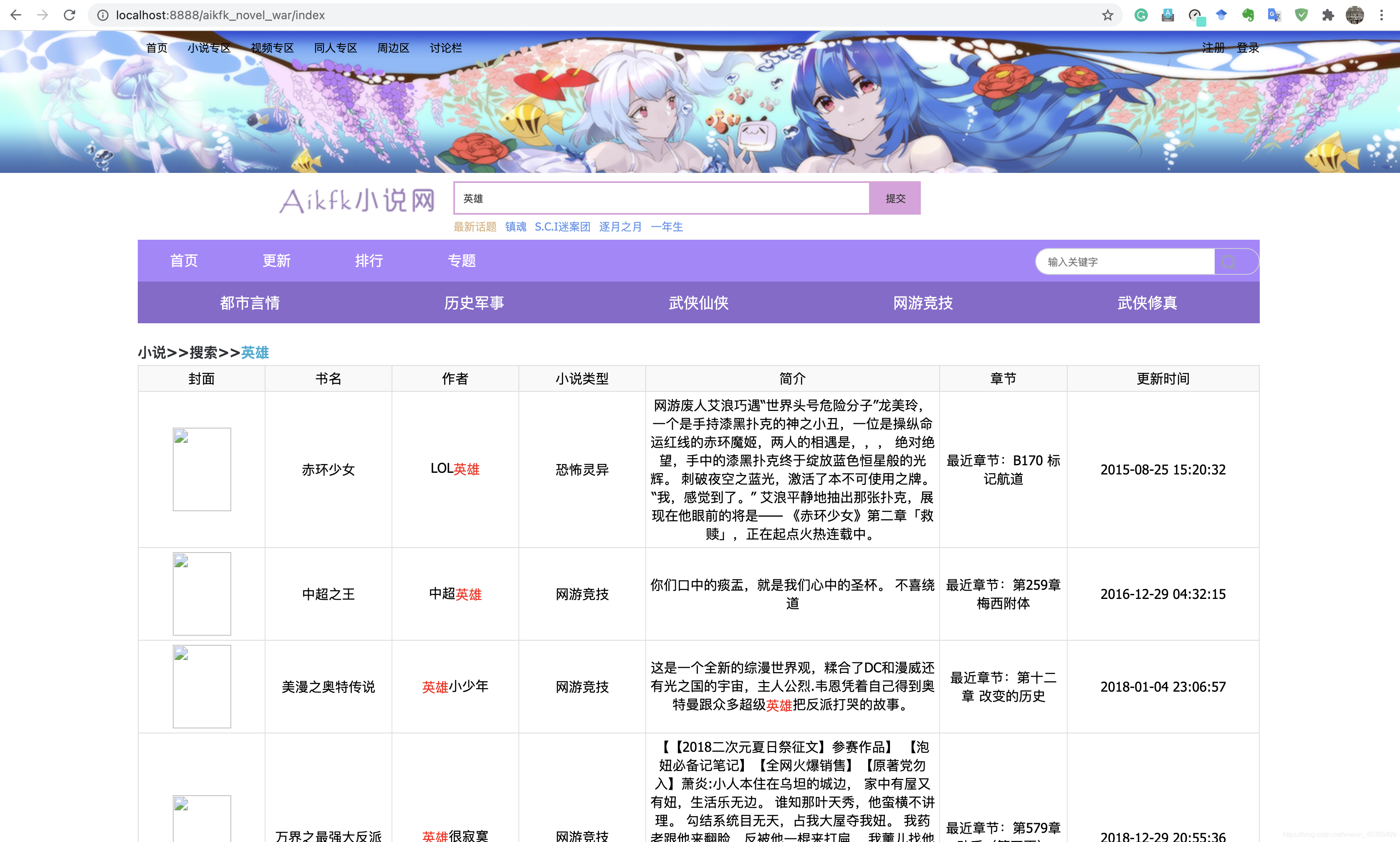
(4)拼音分词插件安装与验证
1.下载地址:https://elasticsearch.cn/download/
2.插件安装
说明文档地址:https://github.com/medcl/elasticsearch-analysis-pinyin
安装方式与IK Analyzer插件相同,在/opt/modules/elasticsearch/plugins/地址下创建pinyin目录,将yinpin资源包下载之后放到创建的pinyin目录。
3.重启ES服务
4.启动kibana服务进行pinyin分词器的验证
测试词:英雄
ES分词器搜索效果: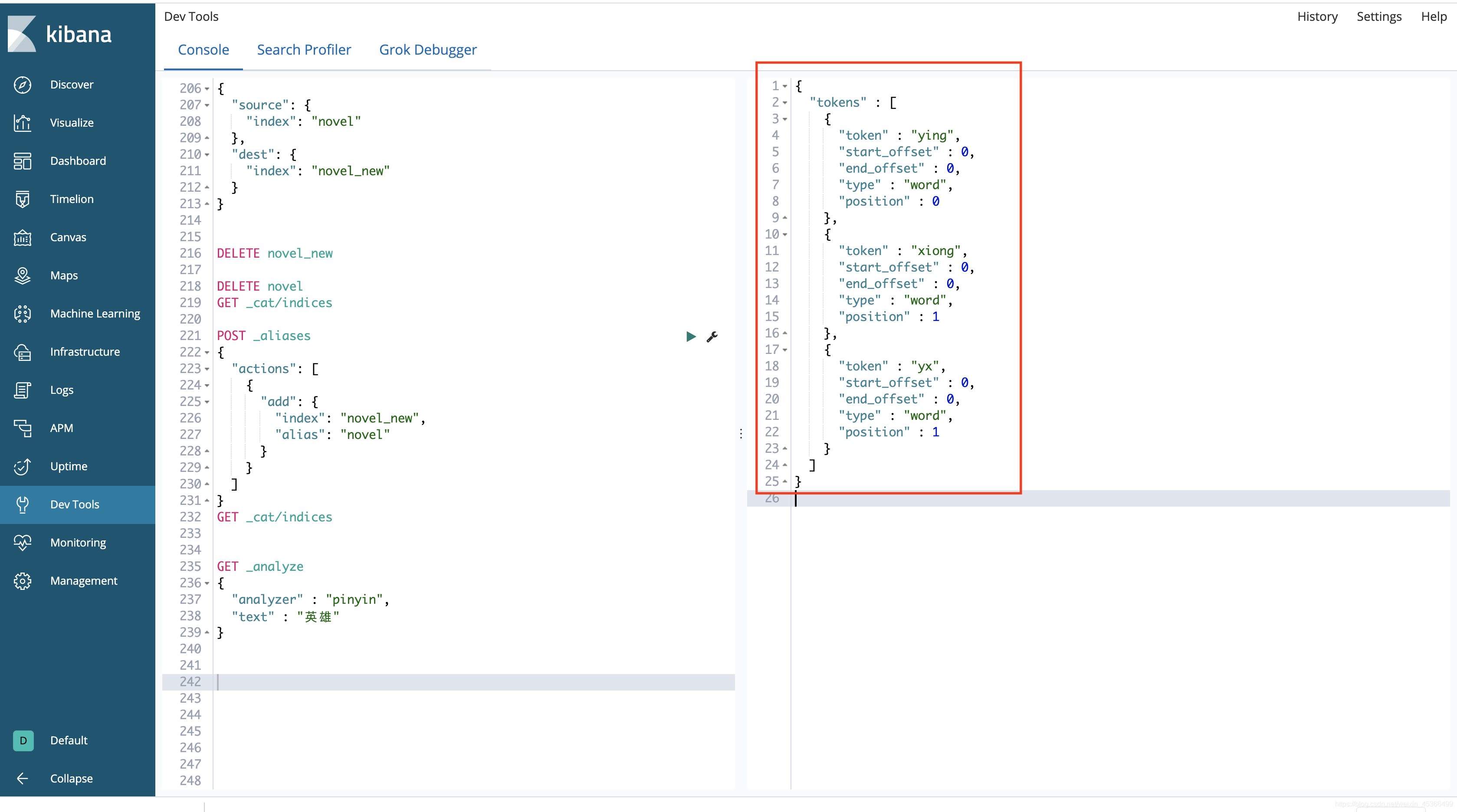
(5)自定义拼音分词器
1.使用自定义拼音分析器创建索引
PUT /novel_new_ik_pinyin/{"settings" : {"analysis" : {"analyzer" : {"ik_pinyin_analyzer" : {"type" : "custom","tokenizer" : "ik_max_word","filter" : "my_pinyin"}},"filter" : {"my_pinyin" : {"type" : "pinyin","keep_separate_first_letter" : false,"keep_full_pinyin" : true,"keep_original" : true,"limit_first_letter_length" : 16,"lowercase" : true,"remove_duplicated_term" : true}}}}}
2.对自定义拼音分析器进行测试
GET novel_new_ik_pinyin/_analyze{"analyzer": "ik_pinyin_analyzer","text": "英雄"}
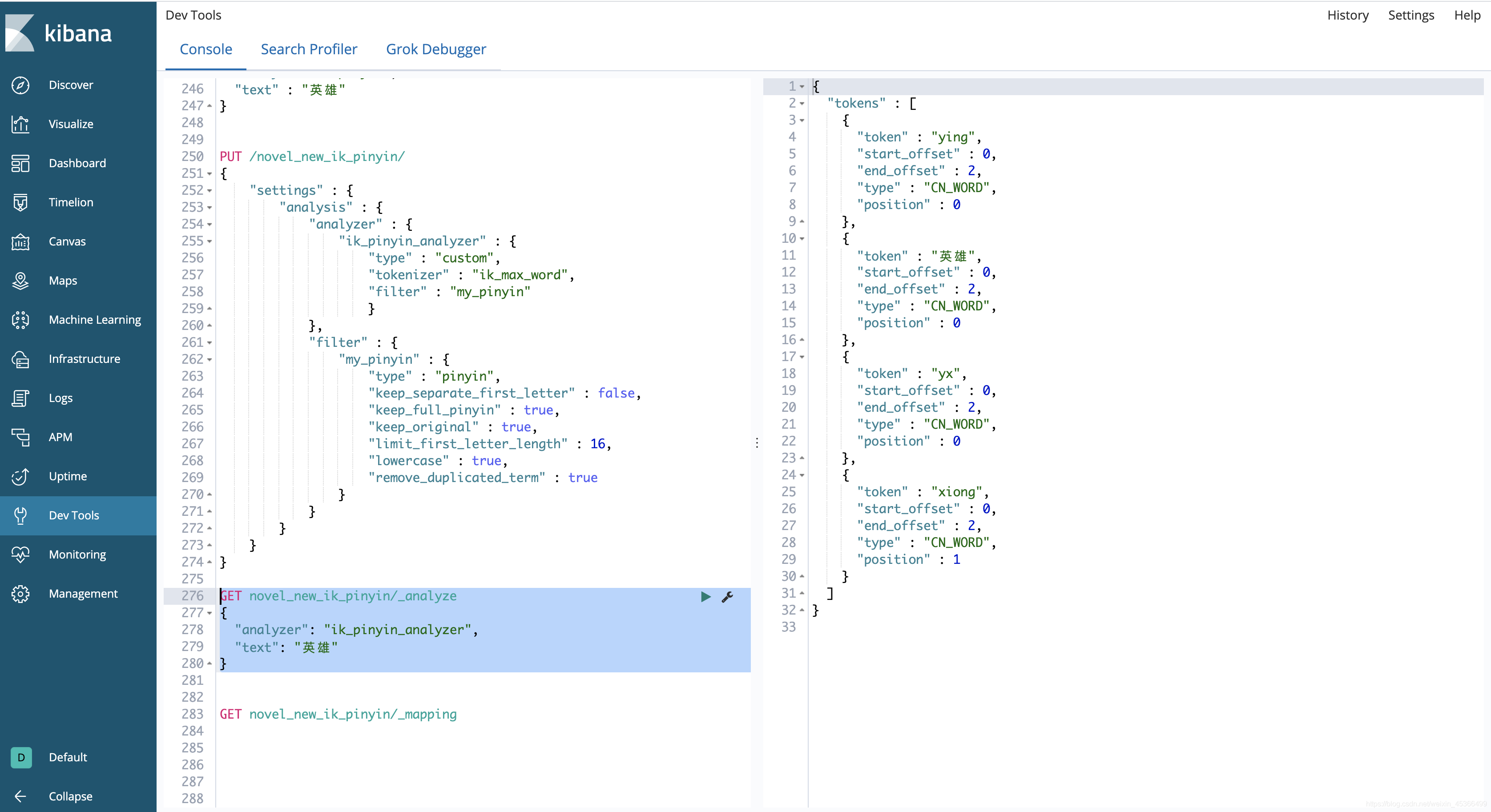
3.创建索引对应的Mapping
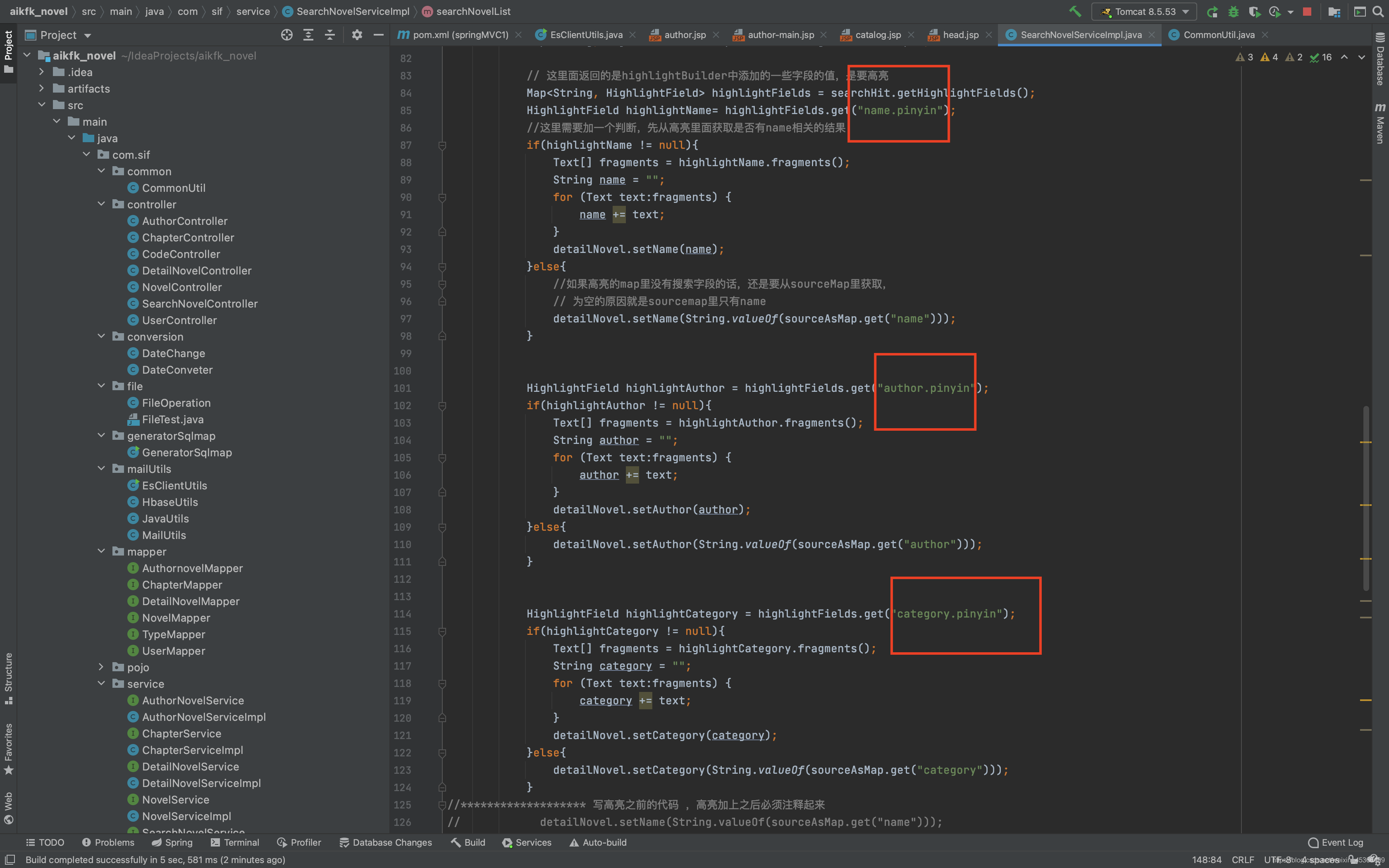
将需要查询的字段加上自定义拼音分析器,因为拼音分析也包含中文分词分析。
包括字段: author、name、category、novelinfo
Boost:为权重设置。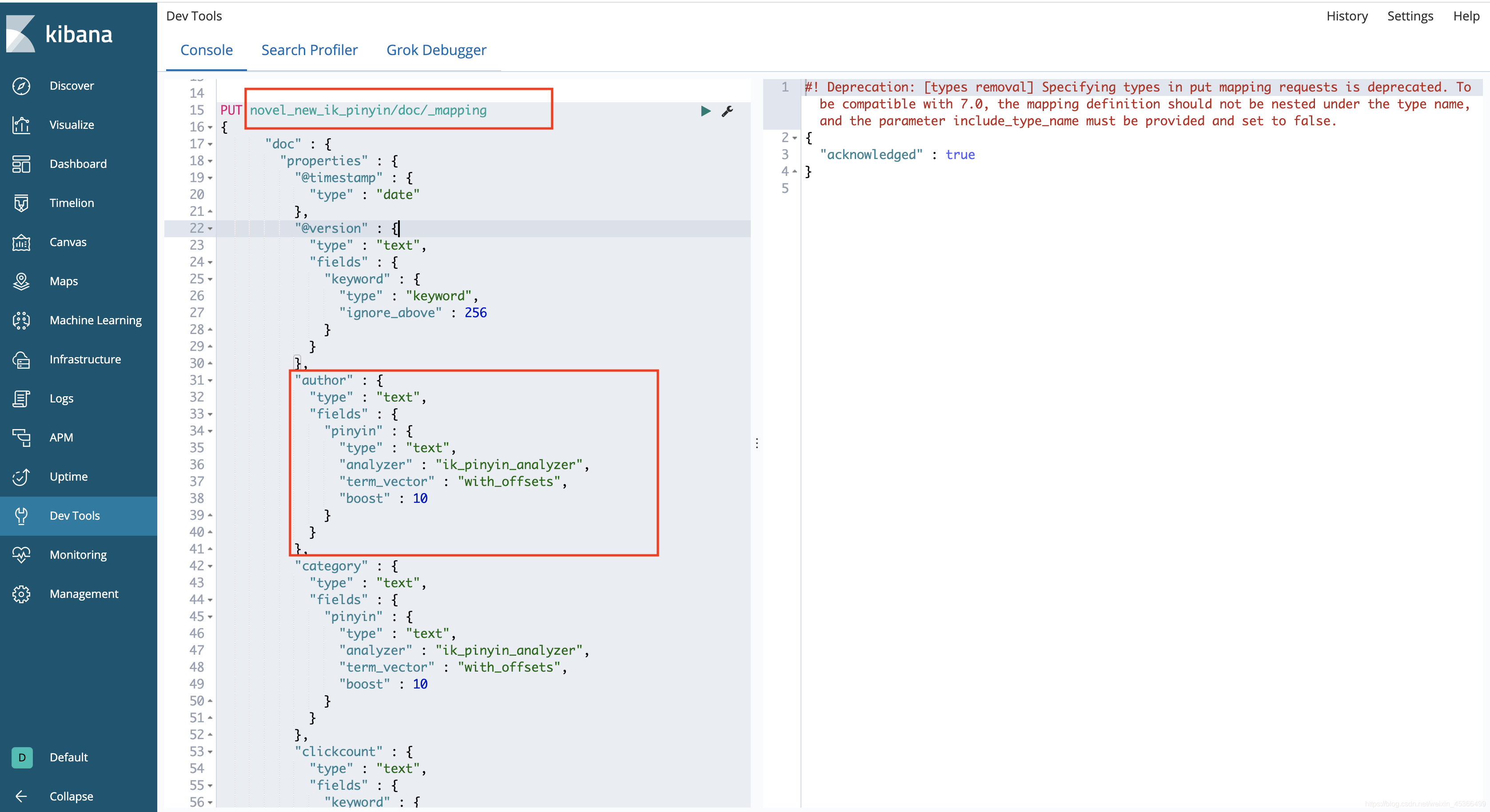
4.对新创的索引加载数据
POST _reindex{"source": {"index": "novel"},"dest": {"index": "novel_new_ik_pinyin"}}
5.基于Kibana进行测试
GET novel_new_ik_pinyin/doc/_search{"query": {"match": {"name.pinyin": "meinv"}}}
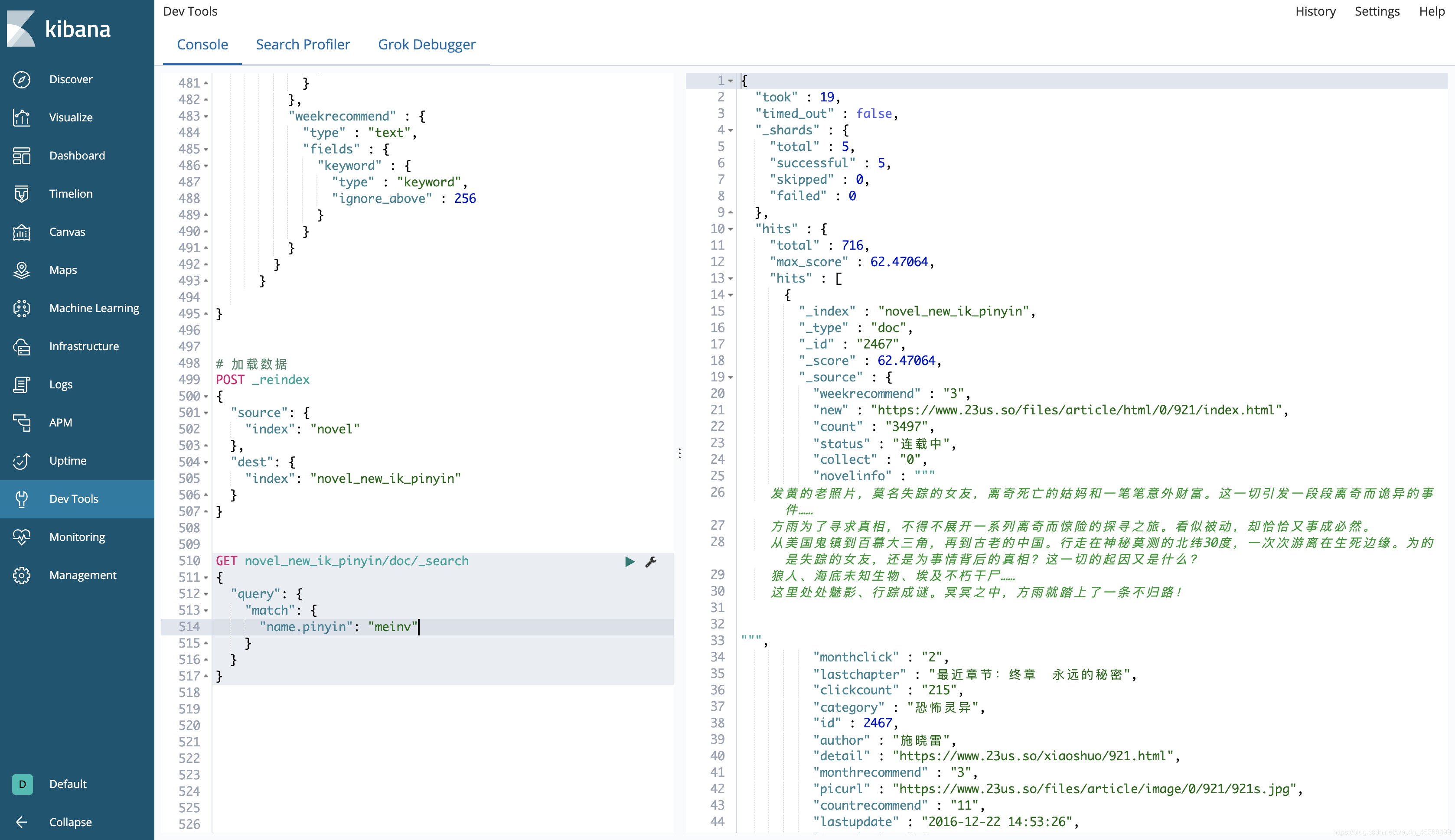
6.创建别名,程序代码不动
POST _aliases{"actions": [{"add": {"index": "novel_new_ik_pinyin","alias": "novel"}}]}
7.代码开发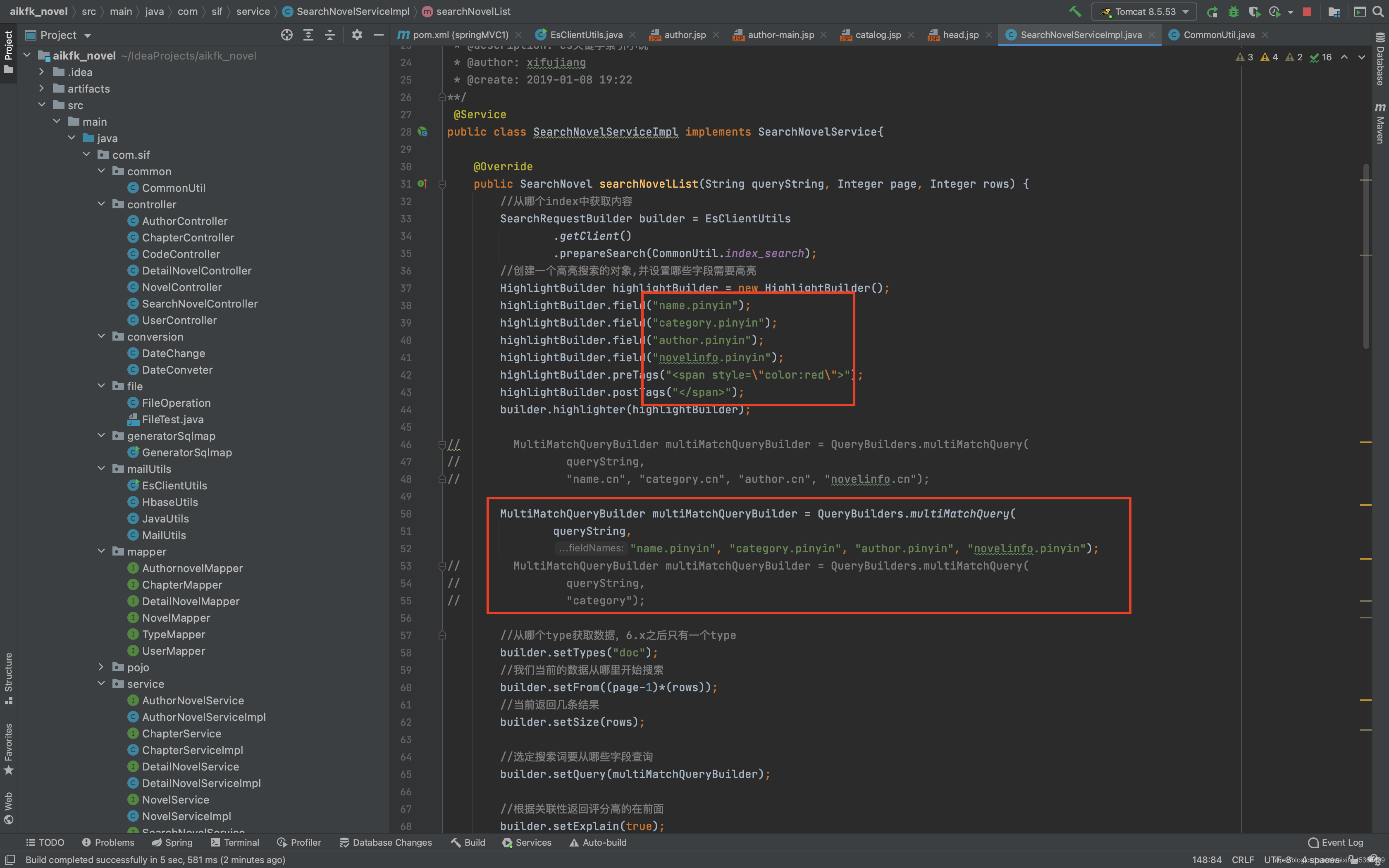
8.页面搜索效果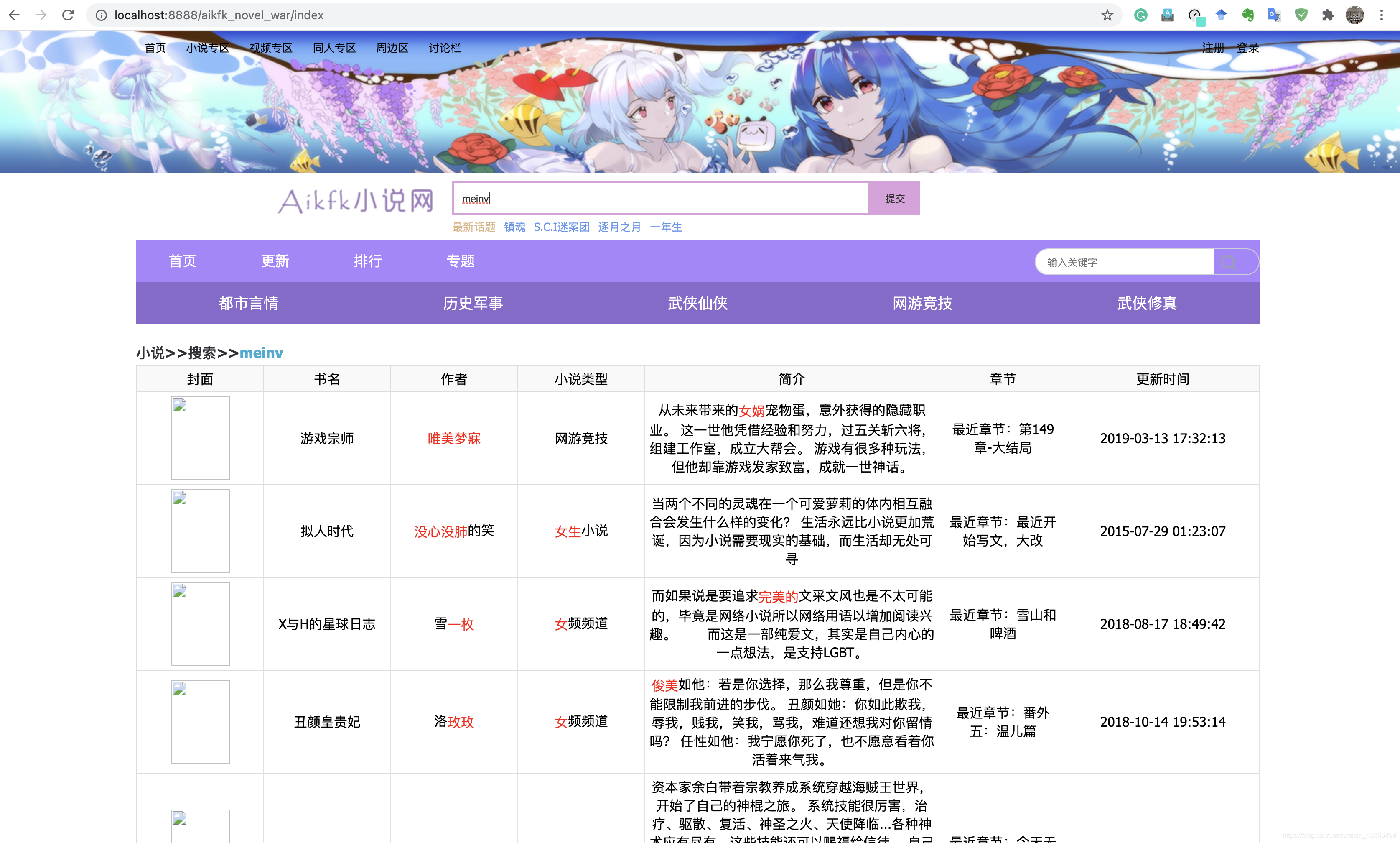
参考:https://blog.csdn.net/weixin_45366499/article/details/113697332

若有收获,就点个赞吧
0 人点赞
