在提高生产效率、调整产业结构、提高产品服务质量、降低人工运营成本等战略目标的驱动下,我国各行各业都在从传统模式向数字化、网络化、智能化转变。例如,制造业正在从粗放型向质量效益型转变,从高污染、高能耗向绿色制造转变,从生产型向“生产+服务”型转变,逐步走向智能化,其中,AI技术大大加快了智能制造的步伐。
说起这两年AI领域的热门,跨模态绝对占有一席之地。跨模态指的是多种模态的信息,包括文本、图像、视频、音频、传感器数据、3D等。对跨模态文档(如PDF文件、PPT文件、扫描件、图片等)的分析和理解技术,包括文档信息抽取、文档比对、文档问答等,其广泛应用于金融、能源、物流、医疗、制造业等行业中。
图1:汽车说明书问答示例
例如,基于跨模态文档问答技术搭建的汽车说明书问答系统,能够对用户提出的问题,自动从汽车说明书中寻找答案,并高亮显示输出。这一系统极大地缓解了传统人工售后的压力,降低运营成本的同时,给用户带来满满的惊喜感。对于用户来说,该系统能够通过车机助手/APP/小程序为用户提供即问即答的功能,用户不再需要翻阅说明书,也无需拨打客服电话,排队等候;对于企业来说,该系统帮助客服人员高效查阅文档、快速定位答案、缩短客服的培训周期,为企业降本增效。
近期,飞桨PaddleNLP开源了跨模态文档问答系统方案,可应用于To C产品说明书、工业制造维修手册、工厂设备操作手册等文本布局丰富的各种非单一模态问答场景,该技术深度融合了感知和认知的跨模态语义理解技术,机器能够在理解文本信息的同时,去进一步理解视觉信息,通过文字+图片示例的回答方式高效解决用户问题。此外,还带来汽车说明书问答产业实践范例的直播讲解,手把手实操,快速搭建系统。
GitHub地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/applications/doc_vqa
所有源码及模型均已开源,欢迎大家使用,star鼓励~
**
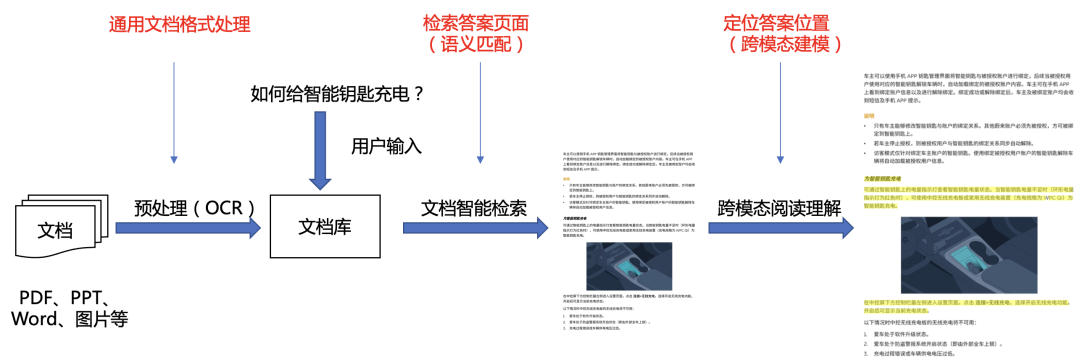
图2:PaddleNLP跨模态文档问答整体流程
PaddleNLP跨模态文档问答整体流程分为三个模块:
- 【文档解析模块】通过OCR技术对跨模态文档进行预处理,获取文本和坐标信息,这里采用了2.2w GitHub star、OCR业务必备的飞桨文字识别套件PaddleOCR。
- 【文档检索模块】若逐个遍历所有的文档寻找答案,会非常耗费时间和资源,因此通过检索模块,找到与问题最相关的top N文档,作为候选集。
- 【跨模态阅读理解模块】基于跨模态文档阅读理解技术深度解析非结构化文档中排版复杂的图文/图表内容,精准定位问题的答案。
下面我们对文档检索和阅读理解模块详细展开。
文档检索模块 – RocketQA技术
检索系统存在于人们日常使用的很多产品中,比如商品搜索、学术文献检索、通用搜索引擎等。传统方法匹配能力有限,只能捕捉字面匹配,而语义检索能够捕捉深层语义信息,达到更精准、更广泛地召回相似结果的目的,这里采用了语义检索技术,有如下亮点: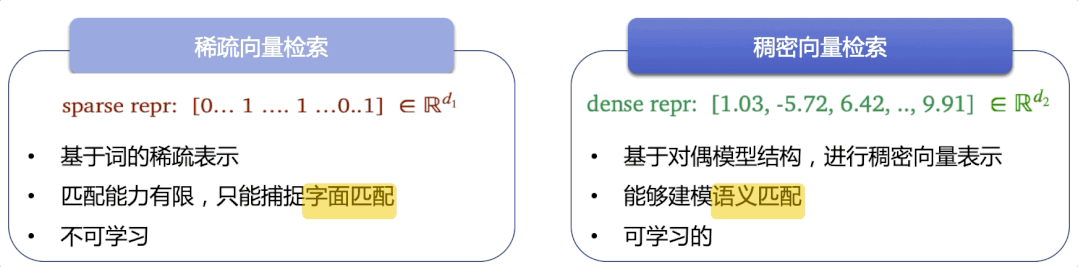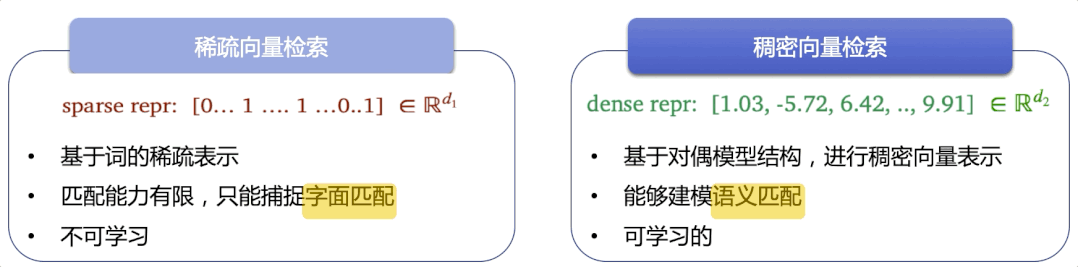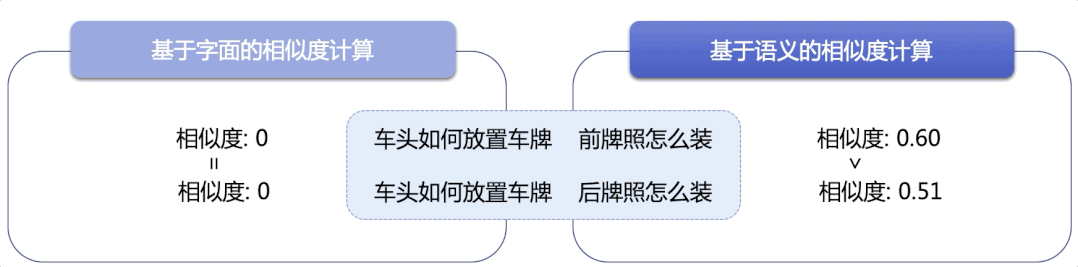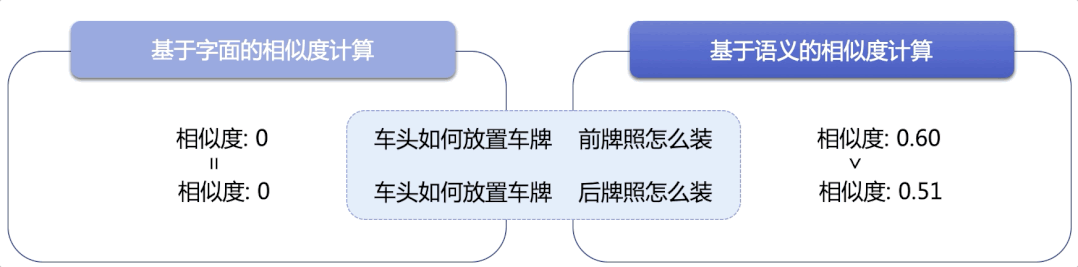
图3:基于字面的稀疏向量检索 vs 基于语义的稠密向量检索
- 领先:采用国际领先的端到端检索问答技术-RocketQA[1],效果远超传统检索问答系统,与国际知名公司的技术方案相比也有一定优势。
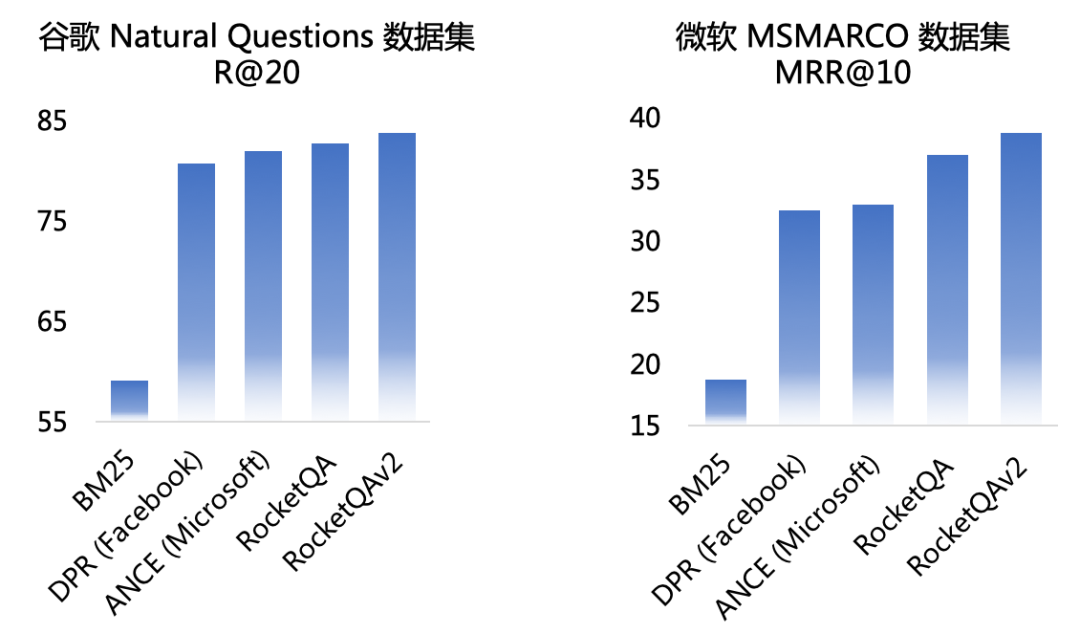
图4:RocketQA效果领先
- 中文:开源首个中文端到端问答模型,该模型基于知识增强的预训练模型ERNIE和百万量级的人工标注数据集DuReader_retrieval [2]训练得到。DuReader_retrieval是源自百度搜索的工业级开源数据集,使得模型在真实场景中表现优异。
前往GitHub获取开源代码和模型:
https://github.com/PaddlePaddle/RocketQA
跨模态阅读理解模块
跨模态阅读理解,要求模型在图文文档中抽取相关问题的答案,需要模型在抽取和理解文档的文本信息的同时,还能充分利用文档的布局、字体、颜色等视觉信息,这比单一模态的信息抽取任务更具挑战性,尤其当布局复杂、答案不连续时,任务挑战更大。
图5:传统文本文档vs 图文复杂布局文档阅读理解
_
近年来,以LayoutLM为代表的基于文本、布局和图像的跨模态预训练模型,在视觉丰富的文档理解任务中取得了优异的性能,展现了不同模态之间联合学习的巨大潜力。这里我们采用多语言扩展LayoutXLM[3]模型,使用DuReadervis数据集[4]——首个面向中文真实搜索场景的跨模态文档智能问答数据集进行微调训练,得到具有跨模态能力的阅读理解模型。DuReadervis样本中的答案源于文本、列表、表格等多种类型文档中,使得模型在跨模态问答任务上效果优异,该数据集发表于ACL’22。
经过OCR解析——文档检索——跨模态阅读理解三个步骤,即搭建完成跨模态文档智能问答系统,结果如图6所示:
图6:跨模态文档问答效果展示

若有收获,就点个赞吧
0 人点赞
