算法工程
从0搭建算法在线工程
应用:
- CTR预估
- NPL计算文本情感,相关性分数等
算法线上工程开发人员要解决如下问题:
- 工程人员和算法人员解耦:特征处理和模型训练交给算法开发处理,工程端加载模型和特征处理流程。
- 保证性能
- 配置化:通过配置实现算法策略的上线和迭代。
- 数据,模型版本怎么管理
包括如下管控平台:
- 版本管理平台
- 模型管理平台
- 特征管理平台(包括特征数据和特征处理jar包的管理)
- 打分管理平台
打分流程
涉及到以下服务:
- 打分服务
- 特征服务
- 版本管理服务
- tensorflow模型服务
打分服务
打分req&resp
请求:
{"app_name":"favpush","origin":{ // origin是一个map"goods_id":123,"uid":234}}
打分的response是多个tensor,这些tensor是在fg类中指定的。
流程如下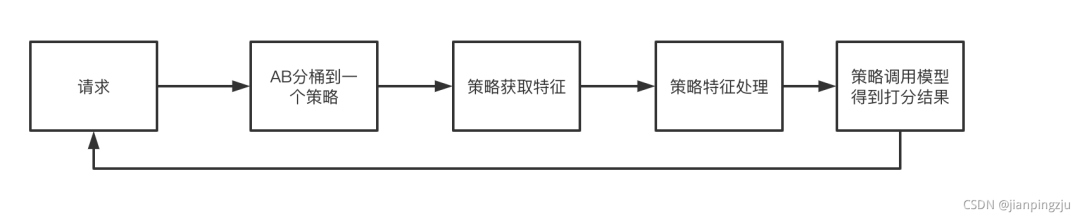
将请求根据配置中心的配置,分桶到某一个solution,每个solution的配置在打分服务都会实例化一个通用的处理类,如com.xxx.service.RankingSoltution。solution的配置包括:模型,特征query模板,特征处理类等信息
解析特征query模板,得到特征query,调用特征查询服务获取特征,拼接featureMap
用特征处理类处理featureMap,得到tensorIO
调用模型服务,输入tensorIO、模型名等信息得到推理结果。
配置
配置中心上存放应用分桶AB的配置,比如:
{"app_name":"favpush","solutions":[{"v1":{"features":{"user_vec":"getKV user_tbl {uid}|{version:favpush_vec_v2}","goods_vec":"getKV goods_tbl {goods_id}|{version:favpush_vec_v2}"},"model":{"name":"favpush_lr","version":"favpush_lr_v1"},"fg": {"class": "com.xxx.ranking.fg.LRFg","version": "v2"},"buckets":[0,1,2]}},{"v2":{"features":{"user_vec":"getKV user_tbl {uid}|{version:favpush_vec_v2}","goods_vec":"getKV goods_tbl {goods_id}|{version:favpush_vec_v2}","cf":"getKKV graph_cf_tbl {uid}|{goods_id}|{version:favpush_cf_v5}"},"fg": {"class": "com.xxx.ranking.fg.DNNFg","version": "v2"},"model":{"name":"favpush_dnn","version":"favpush_dnn_v1"}},"buckets":[3,4,5,6,7,8,9]}]}
特征query模版
getKKV graph_cf_tbl {uid}|{goods_id}|{version:favpush_cf_v5}是特征query模版,通过这个模版生存特征query,再到特征服务去查询特征,这个模版统一了查询特征的语法,屏蔽了不同存储的细节,由以下元素组成:
操作符 表 key
操作符:getKV(返回Object),getKKV(返回Map)等
表:在特征服务上线,一般来说是一个Hbase表,一个图数据库表,一个KV存储的表等
key:不同表的key代表的含义可能不一样,比如hbase的rowkey,redis的2key等。
被{}包围起来的是query字段,query字段和origin中的key一致,或者内置的字段,目前内置的字段有:
version:后面紧跟的字段是版本管理服务的版本key(用:符号分割)
特征服务需要提供特征数据管理的功能,来管理各种表对应的存储集群信息等,对业务方来说只有表和key的概念。
特征处理
线上线下一致性协议为:
interface ConsistFeatureBuilder {TensorIO build(Map<String, Object> featureMap);}
算法人员需要实现这个接口,如LRConsistFeatureBuilder,算法用这个类来进行离线训练,如通过Hive UDF的方式来处理海量数据,这样就实现了线上和线下特征处理的一致性。
fg Jar包管理
打分服务通过加载jar包的方式,通过配置指定的fg类,对其进行实例化来处理featureMap。jar包加入了多版本管理,在配置中需要制定fg类以及jar包的版本。
featureMap字段:
origin:打分请求,为map
online:boolean类型,表示这个featureMap是线上的还是线下的,有时候线上线下处理的逻辑可能不一样
log:是保留字段,为map
其余字段都是特征query模版的key
TensorIO是张量数据的抽象表达,可以表达多种类型(int, boolean, float等)的任意维度的数据。
TensorIO表示在调用下游的tensorflow模型时,输入的tensor和输出的tensor,支持多个tensor的输入输出。
下面的例子输入2个tensor(input, input1),输出一个output tensor:
TensorInput tokenTensor = new TensorInput("input", DataTypeEnum.FLOAT.getValue());tokenTensor.addDim(1);tokenTensor.addDim(tokenList.size());tokenTensor.addAllFloats(tokenList);TensorInput segTensor = new TensorInput("input1", DataTypeEnum.FLOAT.getValue());segTensor.addDim(1);segTensor.addDim(segList.size());segTensor.addAllFloats(segList);TensorOutput tensorOutput = new TensorOutput("output", DataTypeEnum.FLOAT.getValue());return TensorIO.builder().tensorInputs(Lists.newArrayList(tokenTensor, segTensor)).tensorOutputs(Lists.newArrayList(tensorOutput)).build();3
版本管理服务
版本管理服务通过一个可编辑的DAG表示一个业务,每个节点的更新依赖其前置节点,具体方式为
检查前置节点的线上版本,是否都更新到了最新的版本
节点分为三类:
数据节点:外部可以通过HTTP来更改某个数据节点版本,外部可以是上传模型或者特征的平台。
触发节点:当前置节点更新时,会更新其就绪版本,当就绪版本大于线上版本时,当前节点会发出外部的HTTP调用,外部确认后,确认更新触发节点,将就绪版本改为线上版本。外部可以是数据的加载或者校验。
输出节点:将版本输出到配置中心。
版本管理服务提供SDK,SDK封装了对配置中心的访问,可以通过API获取某个业务的版本。版本管理还需要提供版本长时间未更新,版本快失效等告警功能。
模型服务
模型服务使用了tensorflow serving,serving通过GRPC提供服务。
每个serving实例只加载一个模型,启动向注册中心上报其模型和地址。
上游的打分服务通过注册中心,找到某个模型对应下游serving的机器列表,调用serving得到推理结果。
serving提供丰富的接口来管理版本,如版本的上线,下线,热更新。
Tensorflow serving简介
Tensorflow serving(简称TFS)提供GRPC和Restful接口,加载tensorflow训练好的模型文件,实现模型在线服务。
配置和模型文件
TFS启动时可以指定一个配置文件model.conf,配置文件格式如下,下面的配置表示TFS会加载最新的2个模型:
model_config_list: {config: {name: "dnn",base_path: "/model/dnn/data/",model_platform: "tensorflow",model_version_policy: {latest: {num_versions: 2}}}}
下面的配置表示TFS会加载版本20200115和20200116版本:
model_config_list: {config: {name: "dnn",base_path: "/model/dnn/data/",model_platform: "tensorflow",model_version_policy: {specific {versions: 20200115versions: 20200116}}}}
在本地的文件系统中,文件应该按照如下方式组织:
/model/dnn/data/20200116/model/dnn/data/20200115
一个版本文件夹内,应该存放Tensorflow导出的模型文件,如下:
20200116/variables/variables.index20200116/variables/variables.data-00000-of-0000120200116/saved_model.pb
TFS会轮询配置目录,识别版本的加载和卸载。
一般来说会通过将目录拷贝到TFS配置目录,来实现版本的加载:具体是通过判断saved_model.pb文件是否加载成功来判断该版本是否成功加载。所以需要最后拷贝saved_model.pb文件,否则会出现模型加载成功,但是变量找不到的问题。
TFS安装和启动
初次安装推荐用docker镜像,网上教程很多,此处不赘述。推荐构建TFS的docker镜像,dockerfile参考此链接。
如下命令启动TFS:
tensorflow_model_server --port=8550 --model_config_file=/model/dnn/conf/model.conf
版本的热更新
如果发现某个版本的模型存在问题,需要重新覆盖该版本模型,TFS并不能感知版本被覆盖了,一种方式是重启TFS,一种方式是通过热更实现。下面介绍如何通过热更TFS配置实现:
TFS提供了handleReloadConfigRequest接口,来热更TFS配置。
最近N个模型模式:
举例:加载最近3个模型(20200114,20200115,20200116),有问题的模型是20200115,第一步是通过热更配置指定TFS加载20200114,20200116,这样20200115就会被卸载,第二步是通过热更配置指定TFS加载最近3个模型,这样20200115就会被重新加载。
指定版本模式:
举例:加载指定版本(20200114,20200115,20200116),有问题的模型是20200115,第一步是通过热更配置指定TFS加载20200114,20200116,这样20200115就会被卸载,第二步是通过热更配置指定TFS加载20200114,20200115,20200116,这样20200115就会被重新加载。
版本管理
TFS通过固定时间轮询版本文件目录,结合当前配置实现版本的加载和卸载。推荐使用“指定版本模式”来管理版本,通过热更配置的方式指定TFS的版本,相比于“最近N个模型模式”,好处是版本加载和卸载可以从TFS剥离,放到外面的服务中去做。
如果版本文件误删或者文件系统故障,会导致线上服务的版本从内存中卸载,这也是TFS版本管理机制决定的(版本文件是否存在于当前文件系统中来决定加载或者卸载),一个优化的策略是修改TFS源码:当TFS发现版本文件不存在后,如果该版本还存在于配置中,不卸载该版本的模型,实现模型服务的高可用。
TFS GRPC
Tensor为张量,可以表示更高维度的数据,TFS提供了GRPC预测打分的接口,如下构建m行n列的二维张量数据:
TensorProto.Builder tensorProtoBuilder;TensorShapeProto.Builder tensorShapeBuilder;tensorProtoBuilder.setDtype(DataType.DT_INT32);tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(m));tensorShapeBuilder.addDim(TensorShapeProto.Dim.newBuilder().setSize(n));tensorProtoBuilder.addAllIntVal(m*n个数据);tensorProtoBuilder.setTensorShape(tensorShapeBuilder);PredictRequest.Builder request;// input是模型导出时指定的输入张量名request.putInputs("input", tensorProtoBuilder.build());PredictionServiceBlockingStub stub;PredictResponse response = stub.predict(request);// output是模型导出时指定的输出张量名TensorProto tensorProto = response.getOutputsOrThrow("output");tensorProto.getFloatValCount(); // m个打分
模型预热
模型加载之后,第一次调用时间会很长,可以通过预热解决这个问题,TFS提供模型文件预热机制,当然也可以通过调用几次模型实现模型预热。
性能优化
官方默认的编译选项就很好用。
1.MKL(坑:使用不当会出现把CPU打满的情况,即使QPS很低)
2.XLA
3.TVM
4.TensorRT
采用以上方法会有2-3倍的优化空间。
常用命令
查看tensor输入输出:saved_model_cli show —dir 20200527/ —all

若有收获,就点个赞吧
0 人点赞
