接着前面对项目的分词索引开发,下面开始做详情页的开发。主表novel表,详情页的数据表为novel_detail表
novel_detail表格式如下:
mysql> desc novel_detail;+--------------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+--------------+--------------+------+-----+---------+----------------+| id | int(11) | NO | PRI | NULL | auto_increment || author_name | varchar(255) | NO | | NULL | || novel_name | varchar(255) | NO | | NULL | || chapter_name | varchar(255) | NO | | NULL | || chapter_url | varchar(255) | NO | | NULL | |+--------------+--------------+------+-----+---------+----------------+
由于这个表的数据量太大,我只取的20万的数据,以便于logstash导入到es中时间更短
create table novel_detail_test as select * from novel_detail limit 200000;
novel_detail原表是没有novel_id这个字段的,为了好与novel表做关联,我添加了一个novel_id这个字段
# 添加novel_idalter table novel_detail_test add novel_id int;# 导入数据update novel_detail_test b set b.novel_id = (select a.id from novel_test a where a.name = b.novel_name);
20万的数据差不多导入了14分钟
现在的novel_detail_test格式如下:
下面需要将novel_detail_test的数据通过logstash导入到es中
# 进入rootsucd /etc/logstash/conf.dvim novel_detail.conf
input {stdin {}jdbc {jdbc_driver_library => "/opt/shell/mysql-connector-java-5.1.48-bin.jar"jdbc_driver_class => "com.mysql.jdbc.Driver"jdbc_connection_string => "jdbc:mysql://bigdata-pro-m04:3306/db_novel"jdbc_user => "root"jdbc_password => "199911"statement => "SELECT id,novel_id,novel_name,chapter_name from novel_detail_test"jdbc_validate_connection => "true"jdbc_validation_timeout => "3600"connection_retry_attempts => "5"jdbc_paging_enabled => "true"jdbc_page_size => "1000"sql_log_level => "warn"lowercase_column_names => "false"}}filter {json {source => "message"remove_field => ["message"]}}output {elasticsearch {hosts => "bigdata-pro-m04:9200"index => "novel_detail"document_id => "%{id}"}stdout {codec => "json_lines"}}
cd /usr/share/logstashbin/logstash -f /etc/logstash/conf.d/novel_detail.conf
下面开始开发代码:
详情页搜索效果: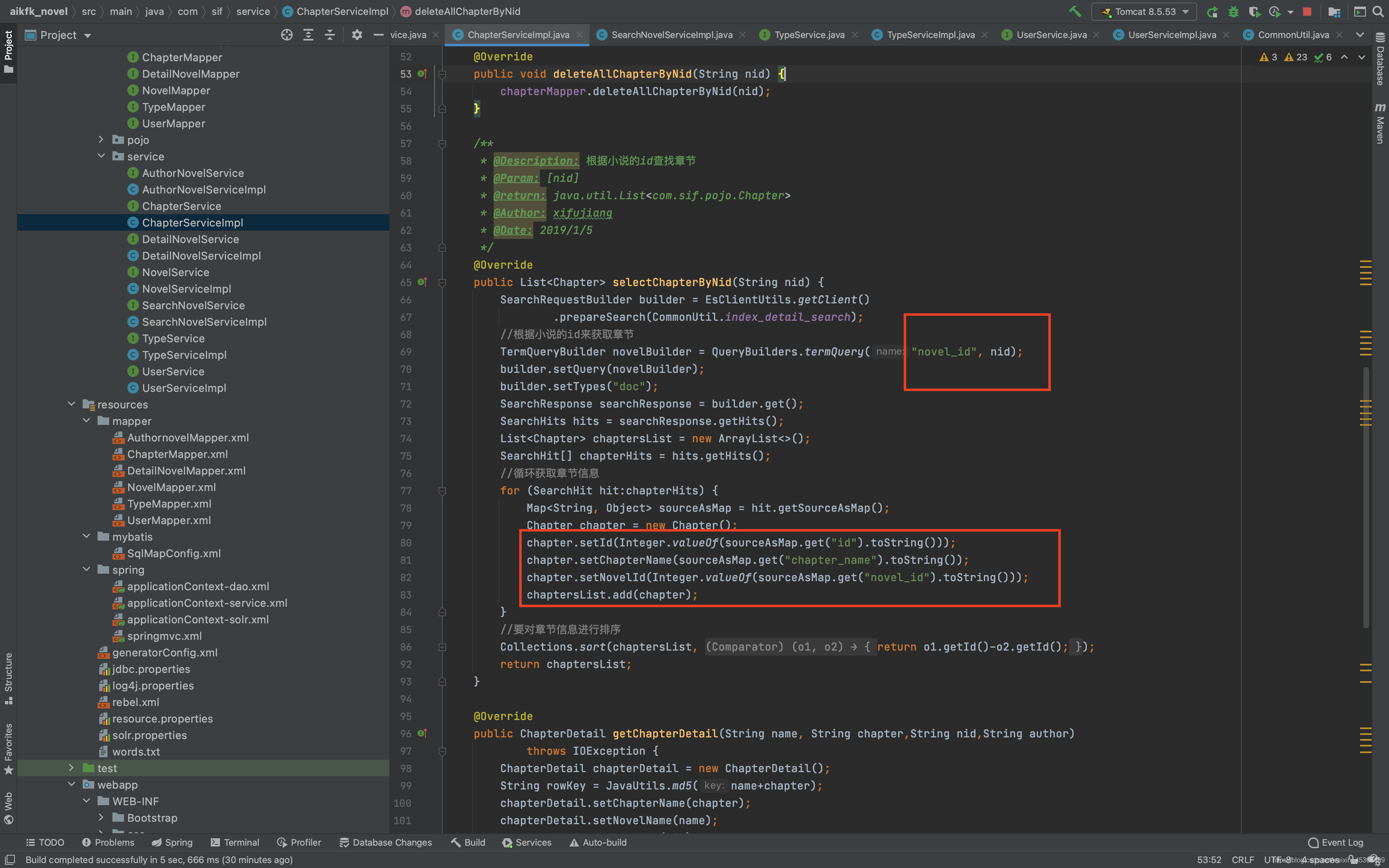
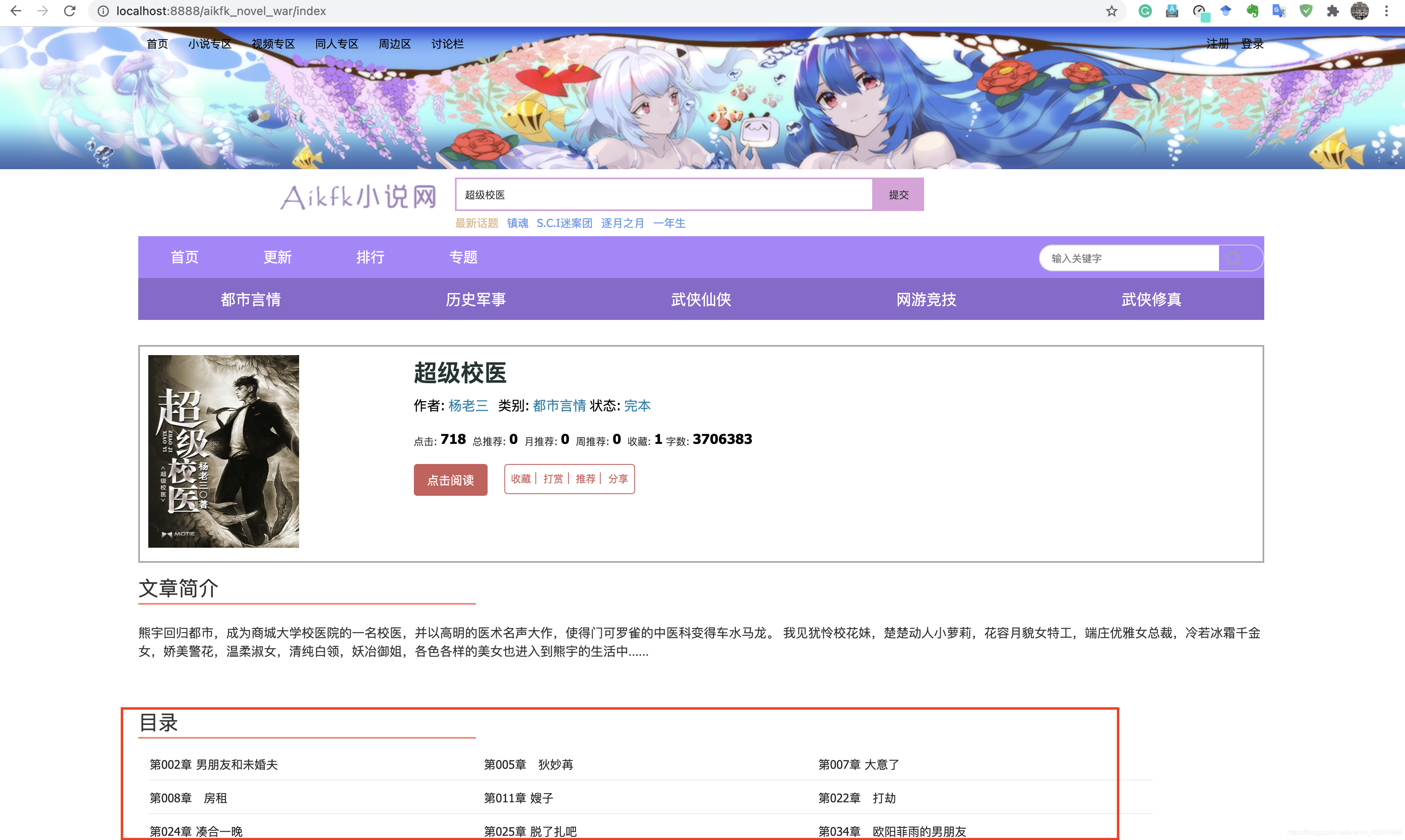
为了能点进每个目录去看,我们需要启动hbase,因为小说内容的链接是存在hbase中的
小说详情页功能开发: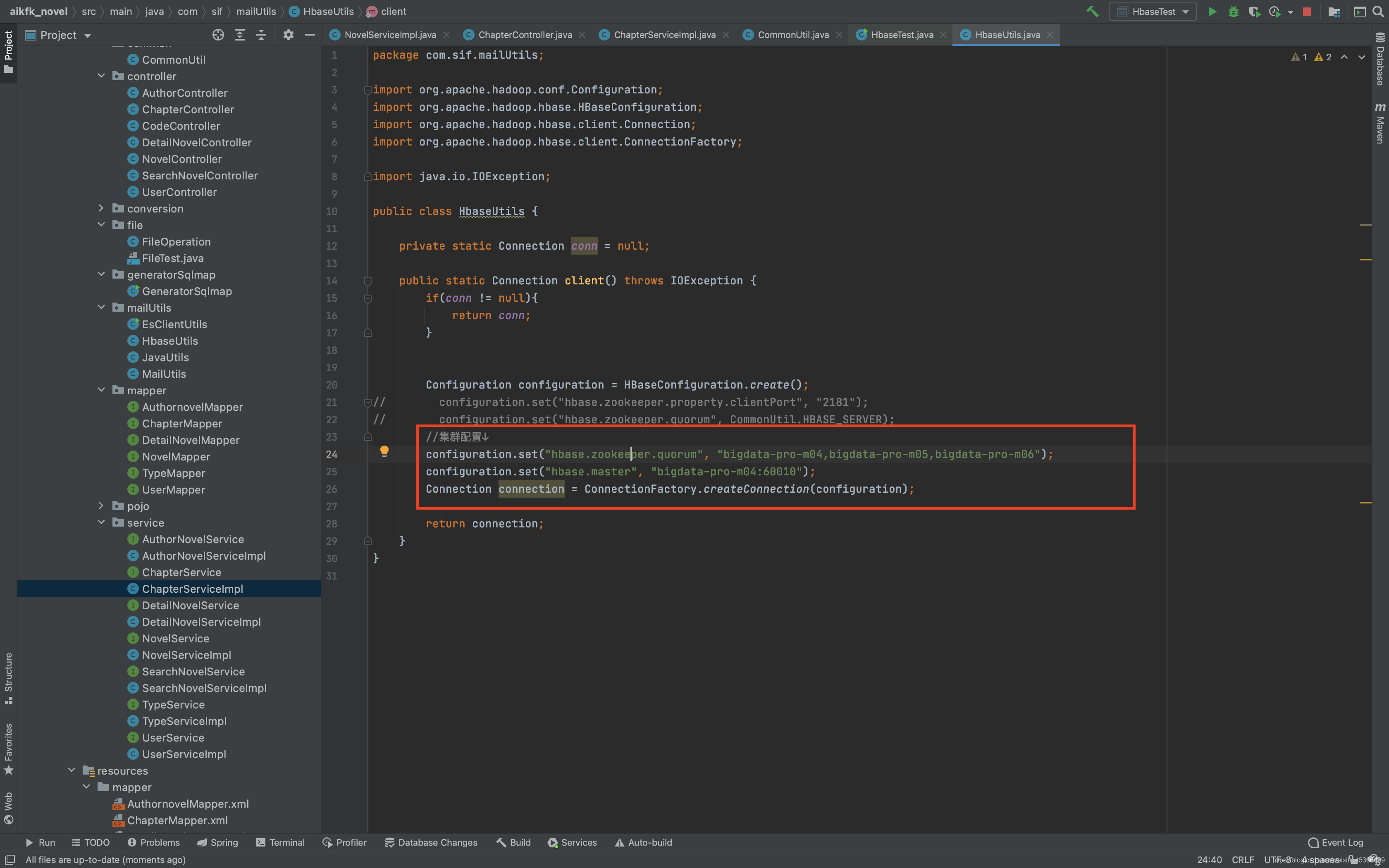
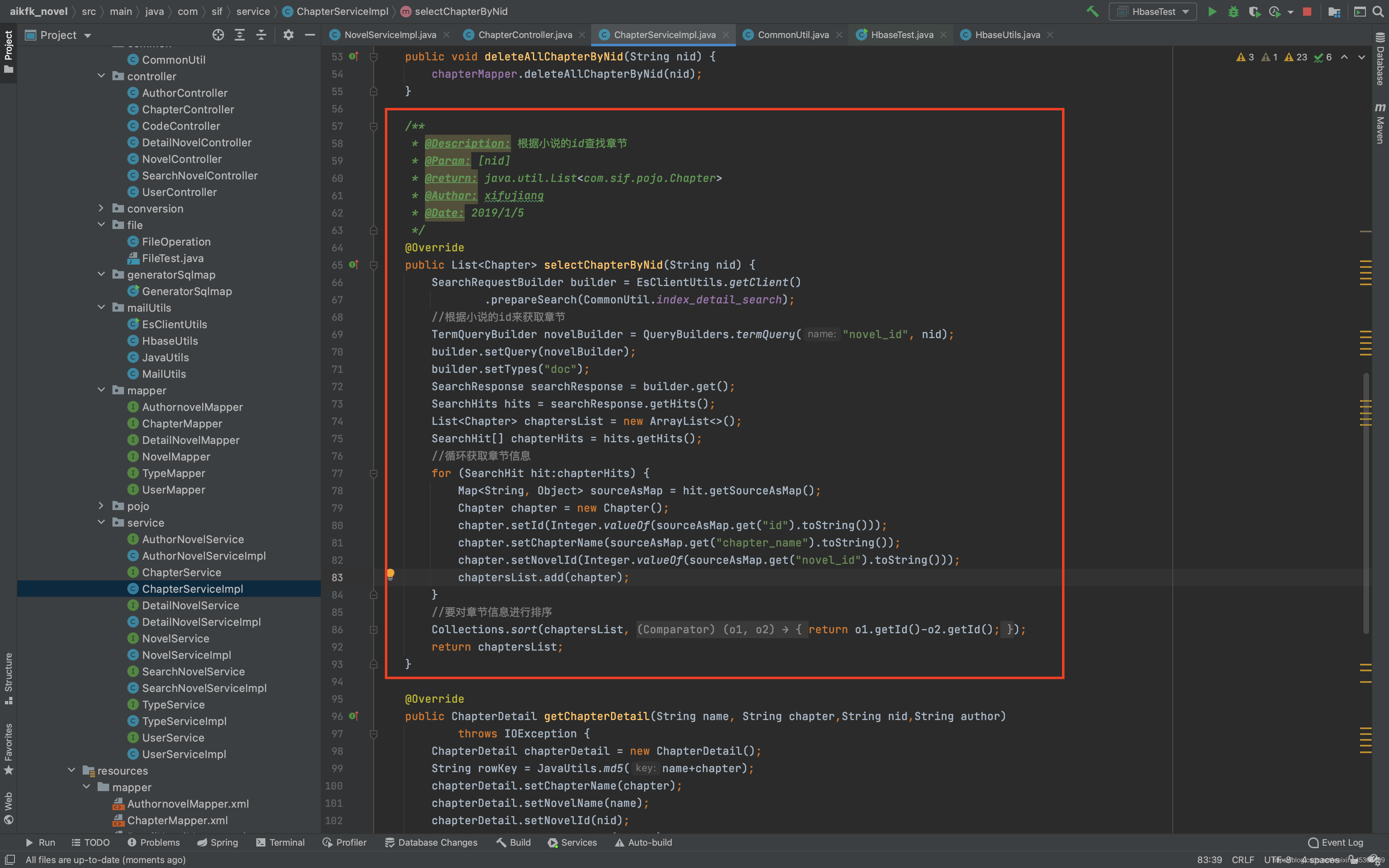
详情页效果: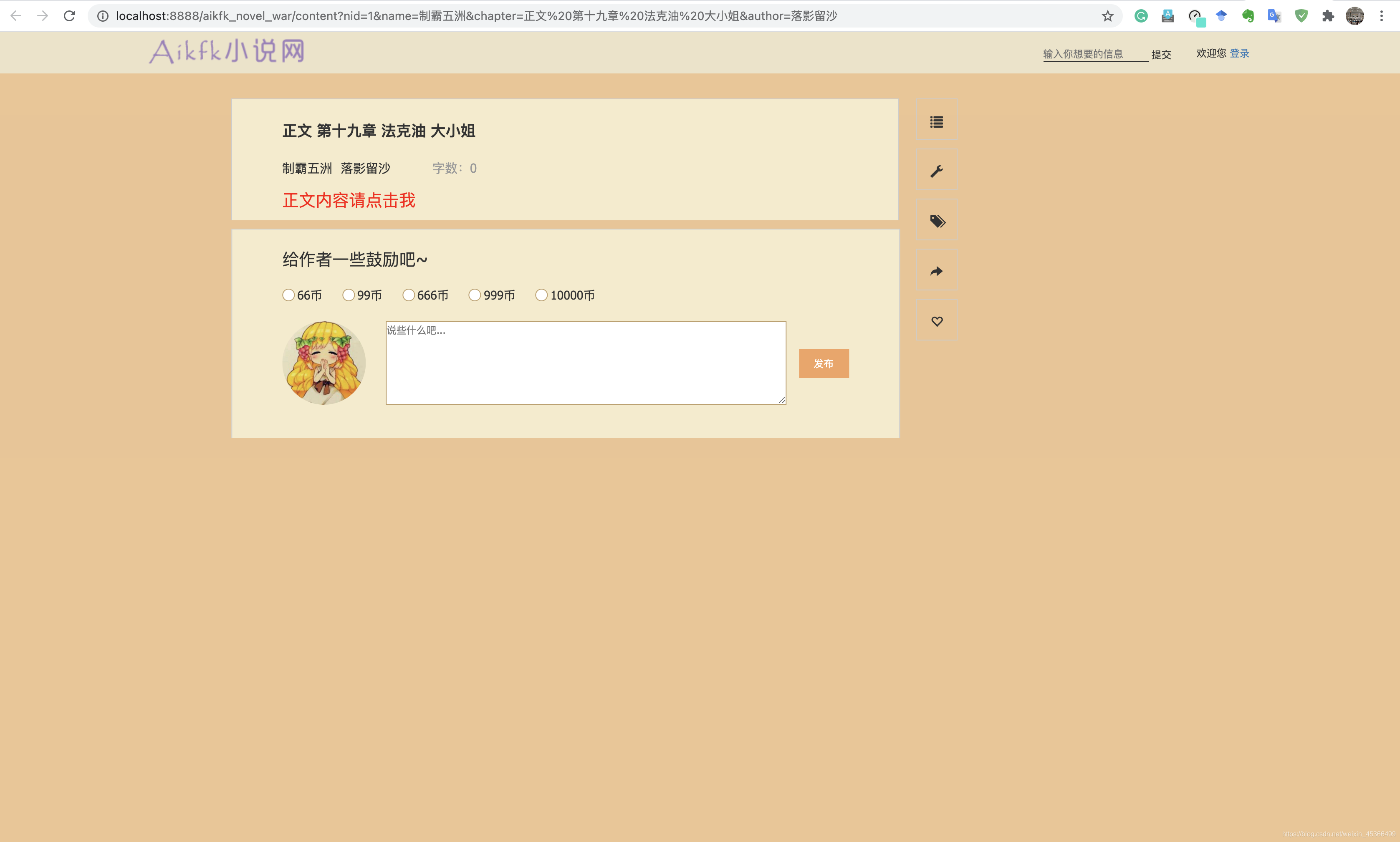

若有收获,就点个赞吧
0 人点赞
