问:radar 提供哪些功能?
答:radar 目前主要提供一个风控引擎平台,通过规则引擎统一管理风险,并支持可视化配置和修改,最大程度的做到所见即所得。
问:radar 怎么集成其他平台或者数据能力?
答:radar 通过插件机制,集成其他数据能力,目前系统自带手机号码段和IP转换(ip2region)两个数据处理插件,通过插件的形式获取关联数据,后续前端页面会提供插件管理功能,方便大家落地的到具体的应用场景。
问: 作为一款实时的风控引擎,radar 为什么会采用 Springboot + Mongodb + Groovy 的架构设计?
为什么没有采用其它更加优秀的 Storm, Flink ,Drools 等框架?
答:作为一款开源版的风控引擎,在设计之初也经过多次调研,开源的目的是设计成通用风控解决方案,普及风控知识以及解决方法,首要的目的是通用,易用,好用,所以在选择技术方案的时候做了一些取舍,不是说 storm, flink 在实时流式处理方面不好,选择 mongodb 主要是考虑在 数据存储方式,数据时间窗口更具有优势,弱schema、json格式文档存储,自动失效,nosql,shading 更加具有通用性。
而 Drools 是大家都较为熟悉的非常优秀的规则引擎框架,之所以选择Groovy 自定义规则引擎,主要是考虑 Drools 在可视化编辑方面,还不够灵活,前端支持难度大,参考了开源社区其他人做的产品,好多还是手写 drools 脚本,而radar 做到了规则定义全中文支持,看不到变量的定义,配置灵活多变,当然groovy 动态脚本也有缺点,动态编译非常消耗性能,高并发可能导致频繁fullGc的问题。
问:目前radar底层使用mongodb,考虑的是长时间窗口(目前推荐3个月),相对于其它实时流式引擎(flink)来说,只能说是准实时,在处理时间窗口较短的场景(秒级,分钟,小时)有明显的弱势,后续是否需要支持flink,以应对实时性非常高的场景?
答:从目前项目架构来说,特征(abstraction)的提取的实现类是基于mongodb来实现的,理论上来说,只需要在基于flink 再实现一遍即可,后续将列入版本计划,同时支持 mongodb 和flink 通过配置选择使用。
问:规则的解析和执行是在什么时候进行的?
答:目前特征(abstraction)的提取和策略集(activation)的执行 都涉及到规则脚本的执行,规则的解析的逻辑在前端页面,具体可以参考 GroovyScriptUtil.java 和 groovyUtil.jsx (react) 这两个类的使用。
问: radar 的评分怎么做的?
答: radar 采用综合累计积分, 简单的来说: f(r) = (ax +n1)+ (by + n2) + (cz + n3) , f(r)为风险总分, xyz 为 特征,, abc 为权重 , n 为偏移量。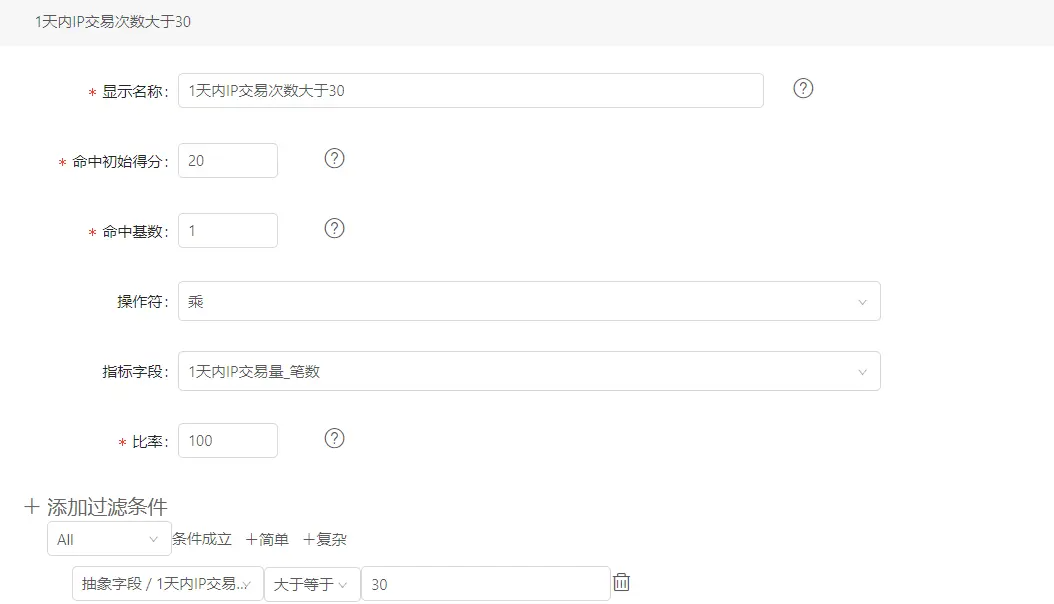
如图,过滤条件 1天内IP交易次数大于 30,假设现在达到31,
这条策略的计分为:20 + 1 31 100% = 51
最后简化成数学表达式: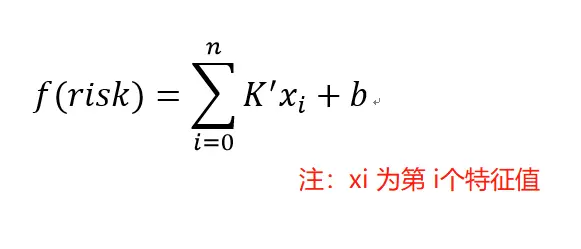
问: 机器学习支持的方式(PMML)? 参考链接:https://www.cnblogs.com/pinard/p/9220199.html
答:现阶段很多机器学习框架都支持java 直接调用,所以直接集成相应的api 就好。

若有收获,就点个赞吧
0 人点赞
