


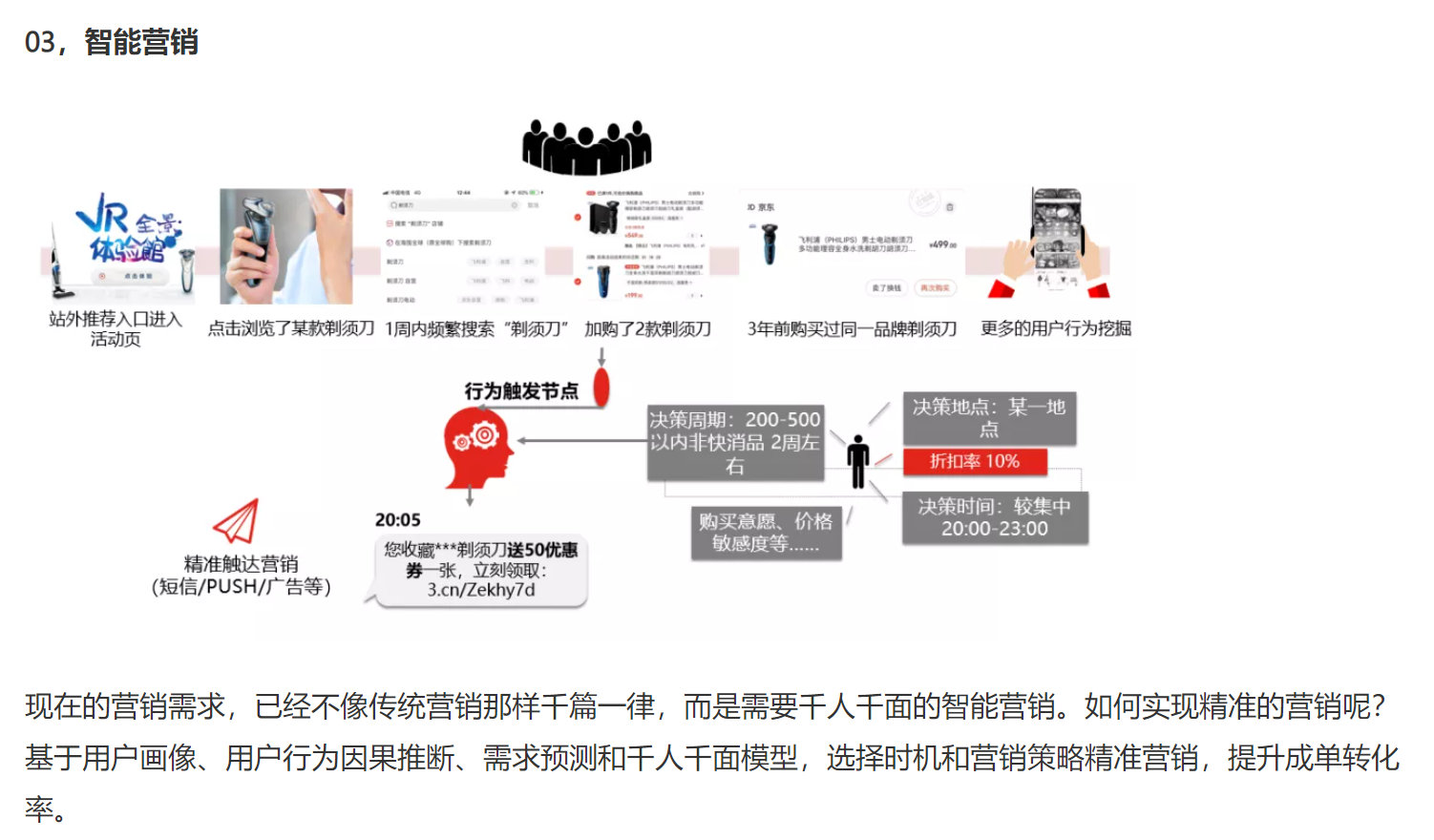

bdp平台中已有许多线上业务产生的数据以供使用,同时还可以导入离线的数据。作为示例,这里将一个评论文本情感分类的数据集上传到bdp中
步骤1. 新建表格
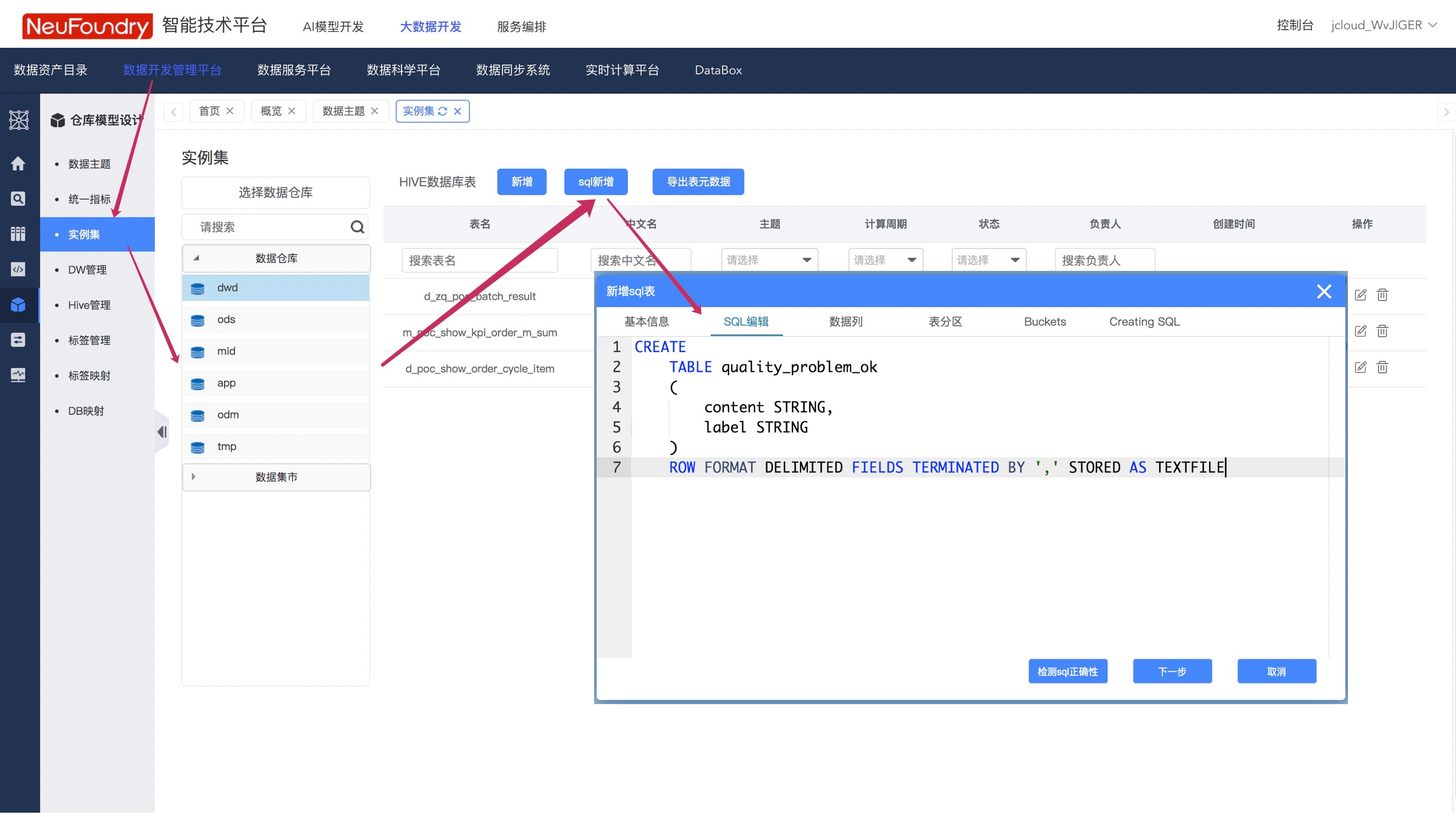 顺序点击
顺序点击
步骤2.上传数据
按照下图步骤,向第一步中新建的表格中插入数据 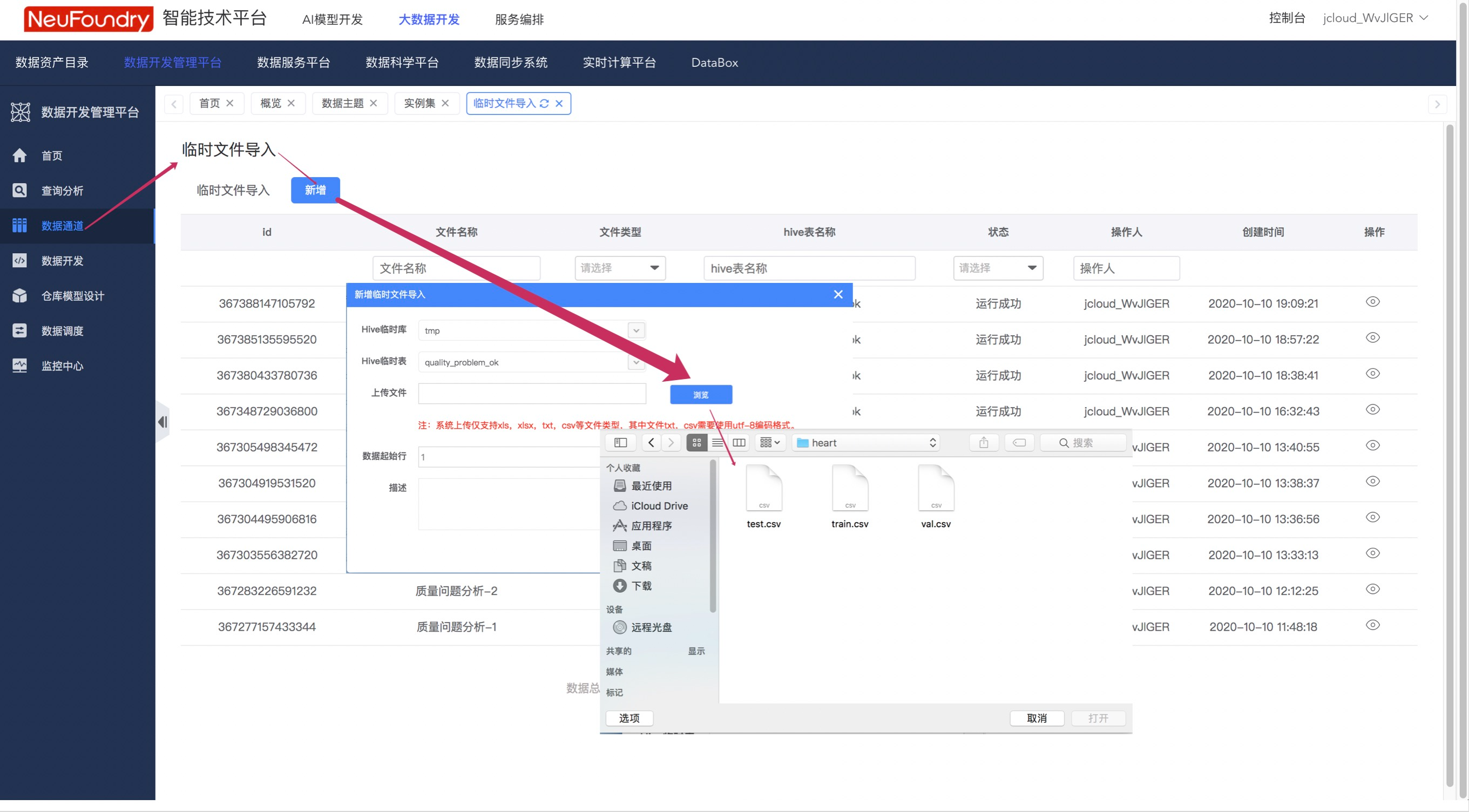 成功后,即可在数据开发管理平台看到新建的任务。
成功后,即可在数据开发管理平台看到新建的任务。 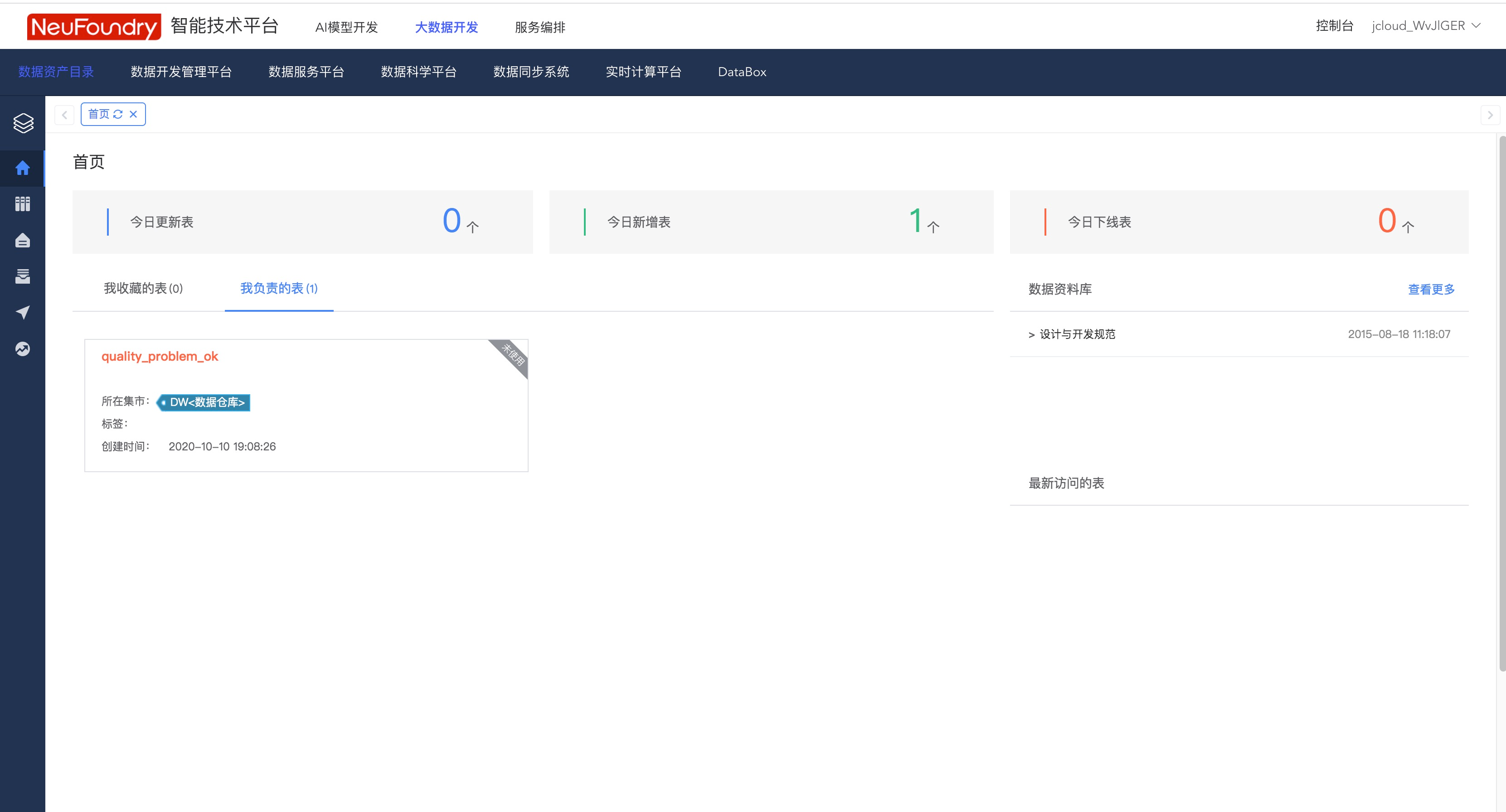
AI模型开发
1. 拉取数据集
上传完成后,进入AI模型开发模块,可以在任务式调度中,取出bdp中的数据集,用于算法的模型训练。新建任务式流程如下。使用bdp时,需要选择PySpark2.4.3引擎框架,上传自己的执行脚本后即可 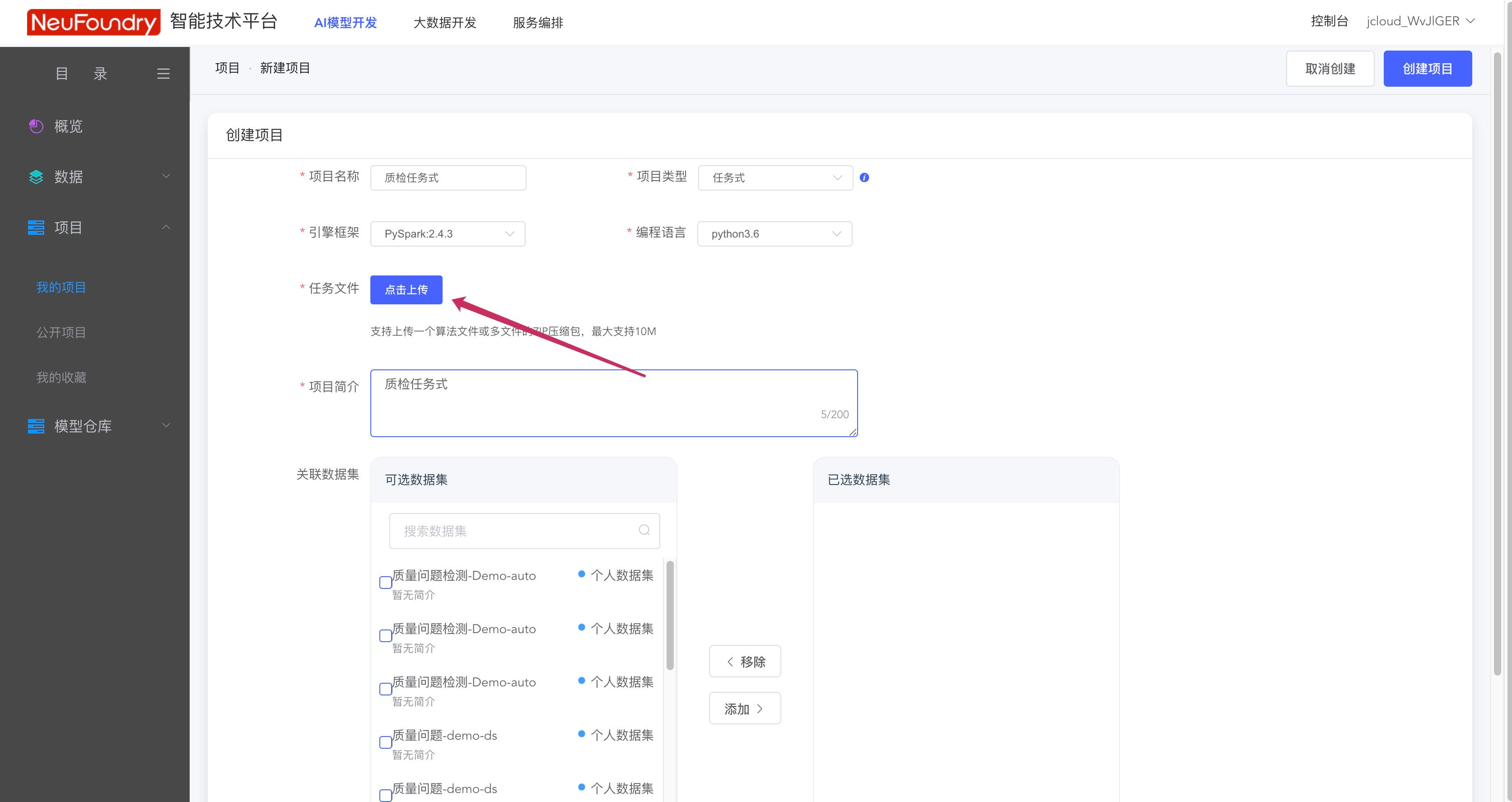
任务式中,提供了取数模板,对模板进行更改即可使用hive提取数据 其中有三处需要用户自行修改
- 自定义设置1: 根据bdp中存储的内容,编写sql语句进行取数
- 自定义设置2: cookie需要根据用户账号自行设置
- 自定义设置3: 自定义一个数据集名称
任务式脚本执行后,可在左侧导航数据栏下看到生成的数据集。
echo '文本内容,标签' > output.csv# 自定义设置1hive -e "select content,label from tmp.quality_problem_ok" | sed 's/\t/,/g' >> output.csv# 自定义设置2cookie="thor=4727E1DC998674A4900ED668E0B68DB46EE69A80F9780117607ADC30F7EB88B754765482AE32D0CF6013BE50BFD4BDCD357E7F2BEF277023F975BBFD02282678894F8ED9BFC490B93929CC1AAB03B2BCD088759CABAC8F01B8AEF7DA28F909A0A1CD7063DB3C81481AD8B15D99B274E9BD578DFDB869643159427CD40181CE571FD386F8A1870A9EAECA615707753A2503783F9E2EE38EFA81CD9AD4275FE4E1;"result=`curl -X POST 'https://nfaitp.jdcloud.com/v1/dataset' \--header "Cookie: ${cookie}" \--header 'Content-Type: application/json' \--data '{# 自定义设置3"name":"质量问题检测-Demo-auto1","labelStatus":1,"labelType":7,"datatype":"0","desc":"","tags":""}'`
2. 模型训练
在AI模型开发平台中,点击我的项目,新建项目,可以在项目中进行模型训练 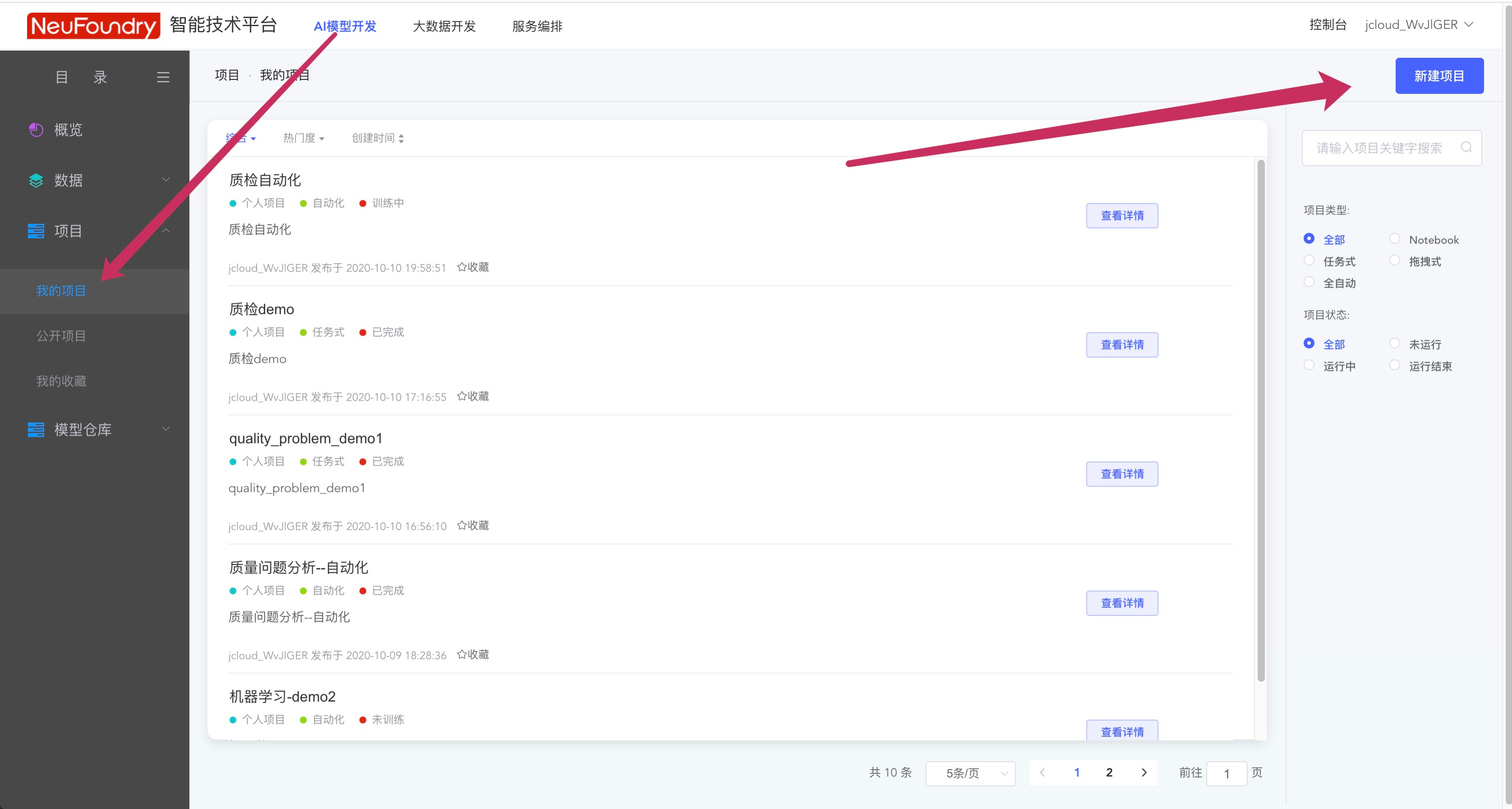
项目分为4种类型,这里以自动化流程为例,使用拉取的数据集进行模型训练。
针对文本分类的场景,我们选择对应的自动化任务,开始训练。 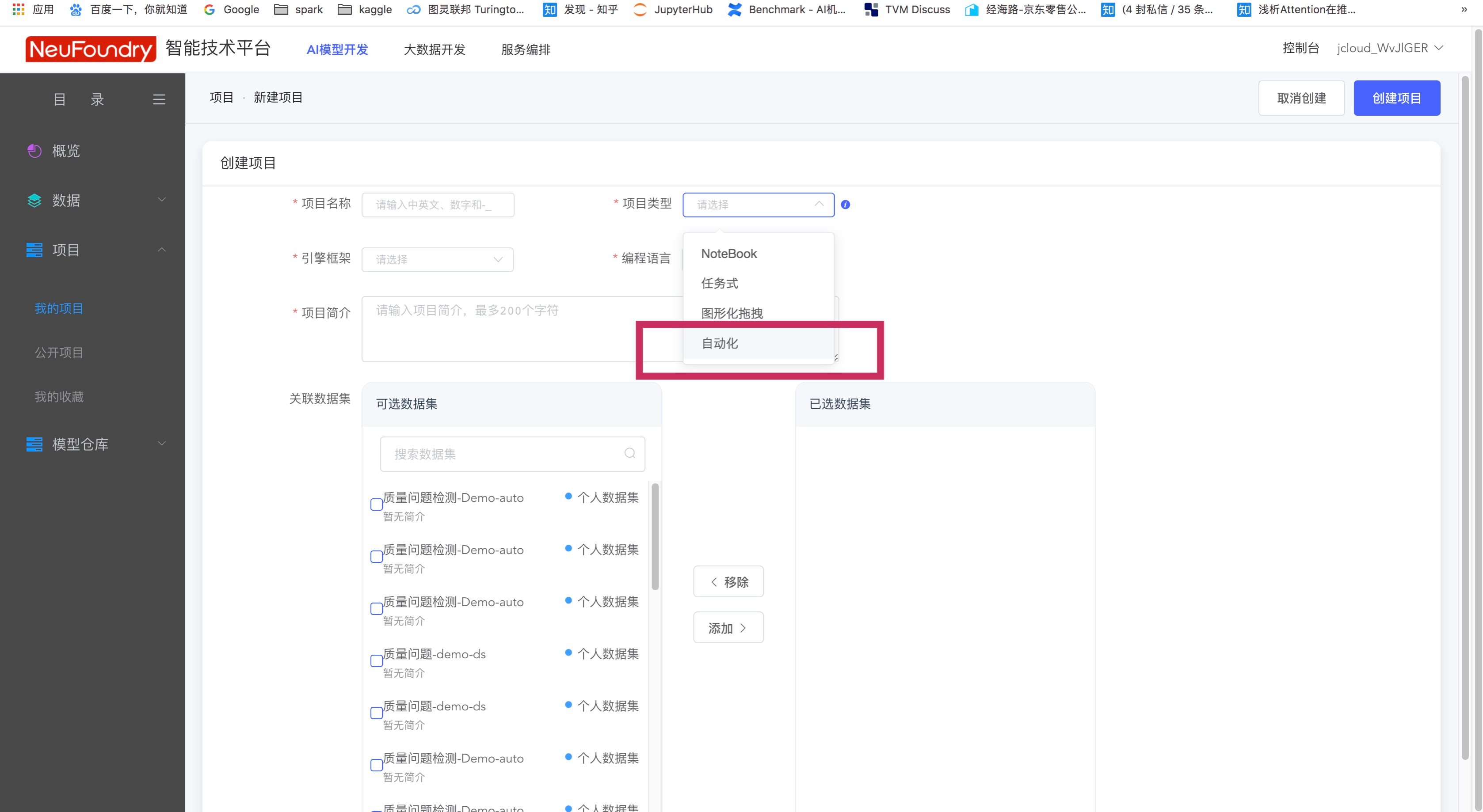
3. 服务发布
自动化任务执行成功后,可以看到对模型的评估指标,若指标合格,即可点击发布按钮,将模型发布为在线API,以供业务使用。点击发布后需要审核人员进行审核,稍作等待
服务编排
若在一个业务场景中,需要多个模型配合完成任务,可以使用服务编排功能,按照自定义流程图调用多种API,灵活完成业务
步骤1. 新建编排流程
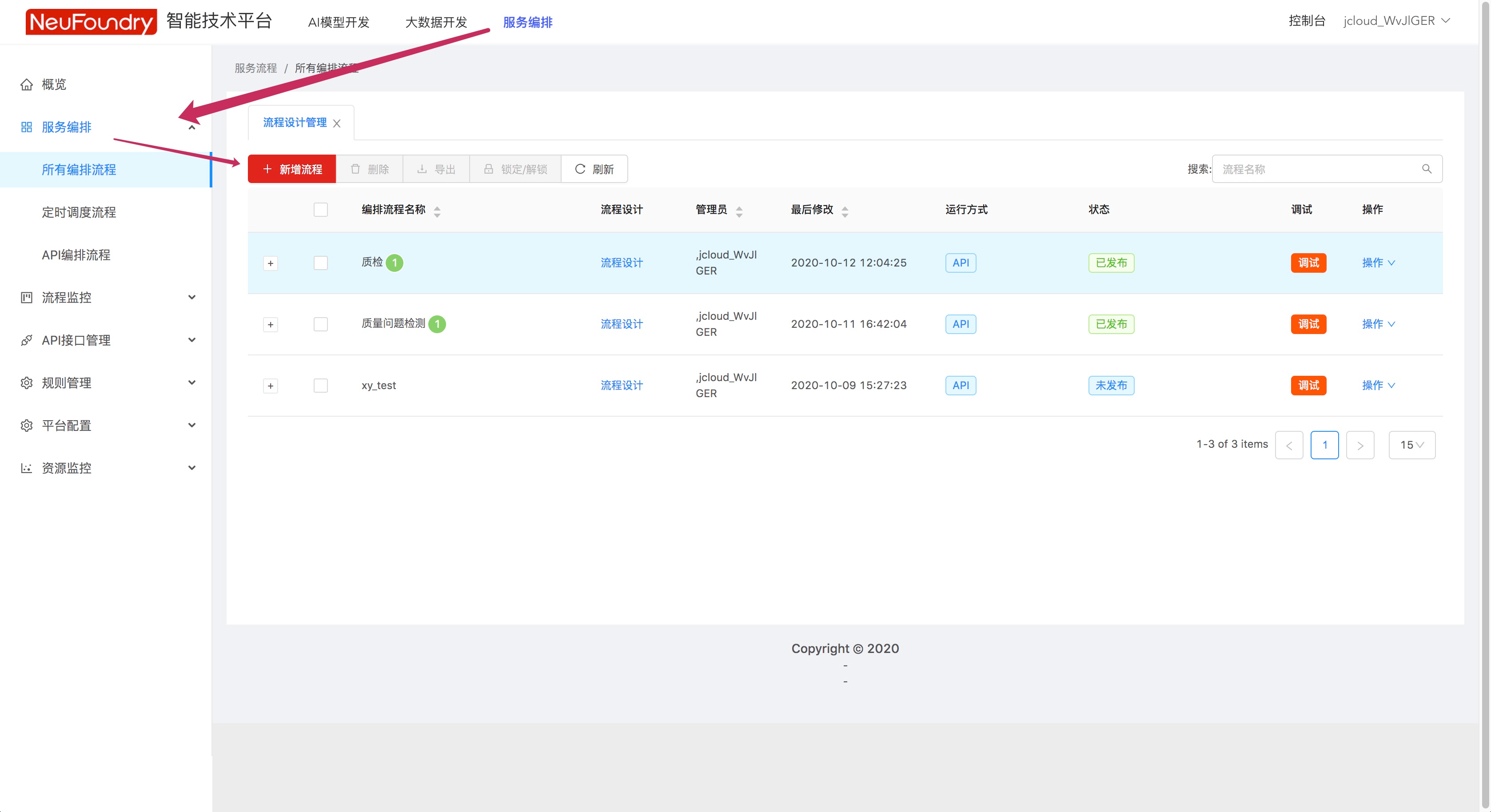
步骤2. 新建编排流程
然后从左侧流程基本节点中,拖拽节点,第一个节点需要数据输入,所以拖拽文件上传节点,最后一个文件需要结果输出,所以拖拽Restful API。 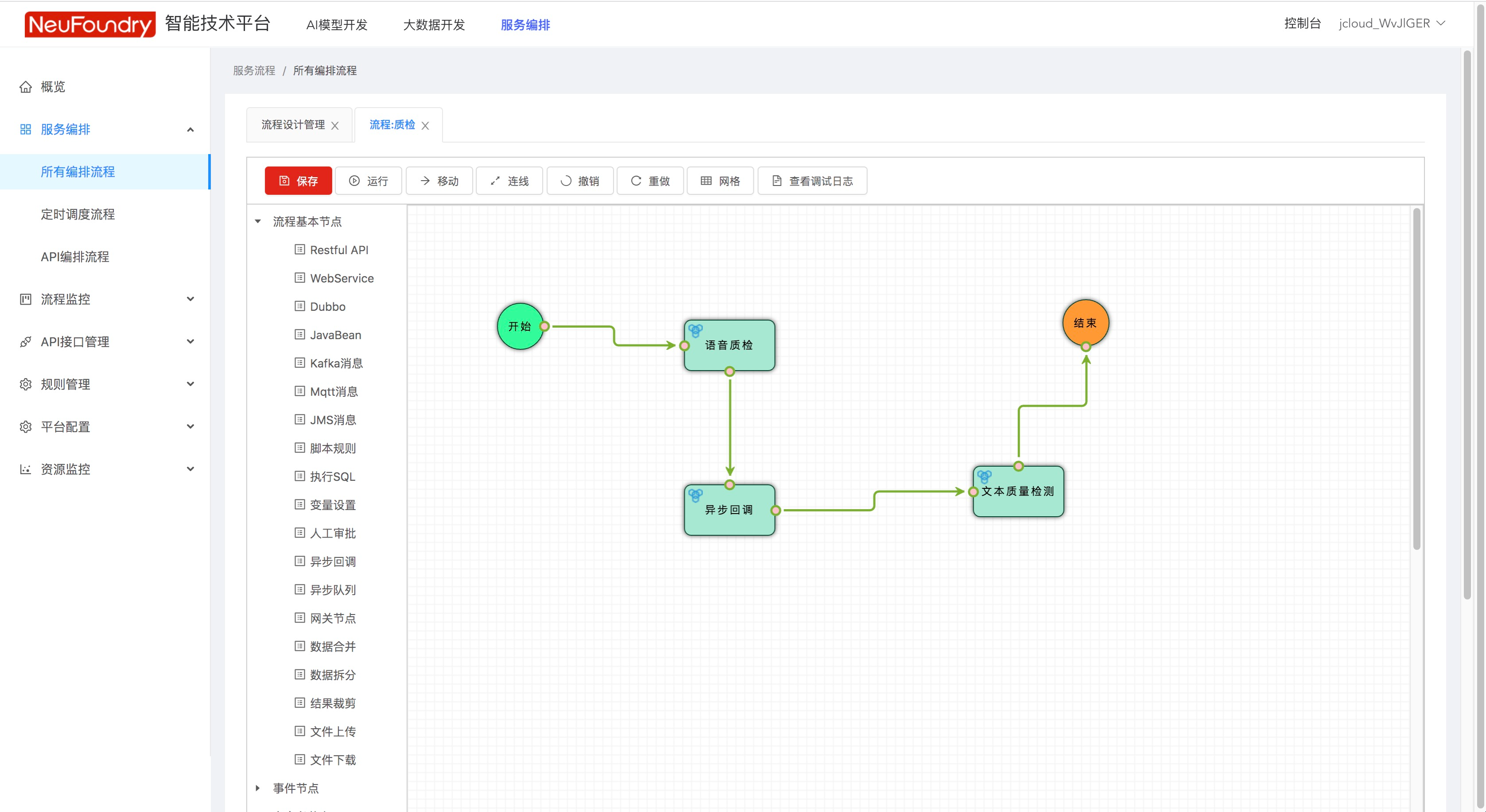 然后对各API节点进行设置,首先设置调用API的URL
然后对各API节点进行设置,首先设置调用API的URL  如果是第一个节点,需要填写从什么位置读取数据
如果是第一个节点,需要填写从什么位置读取数据 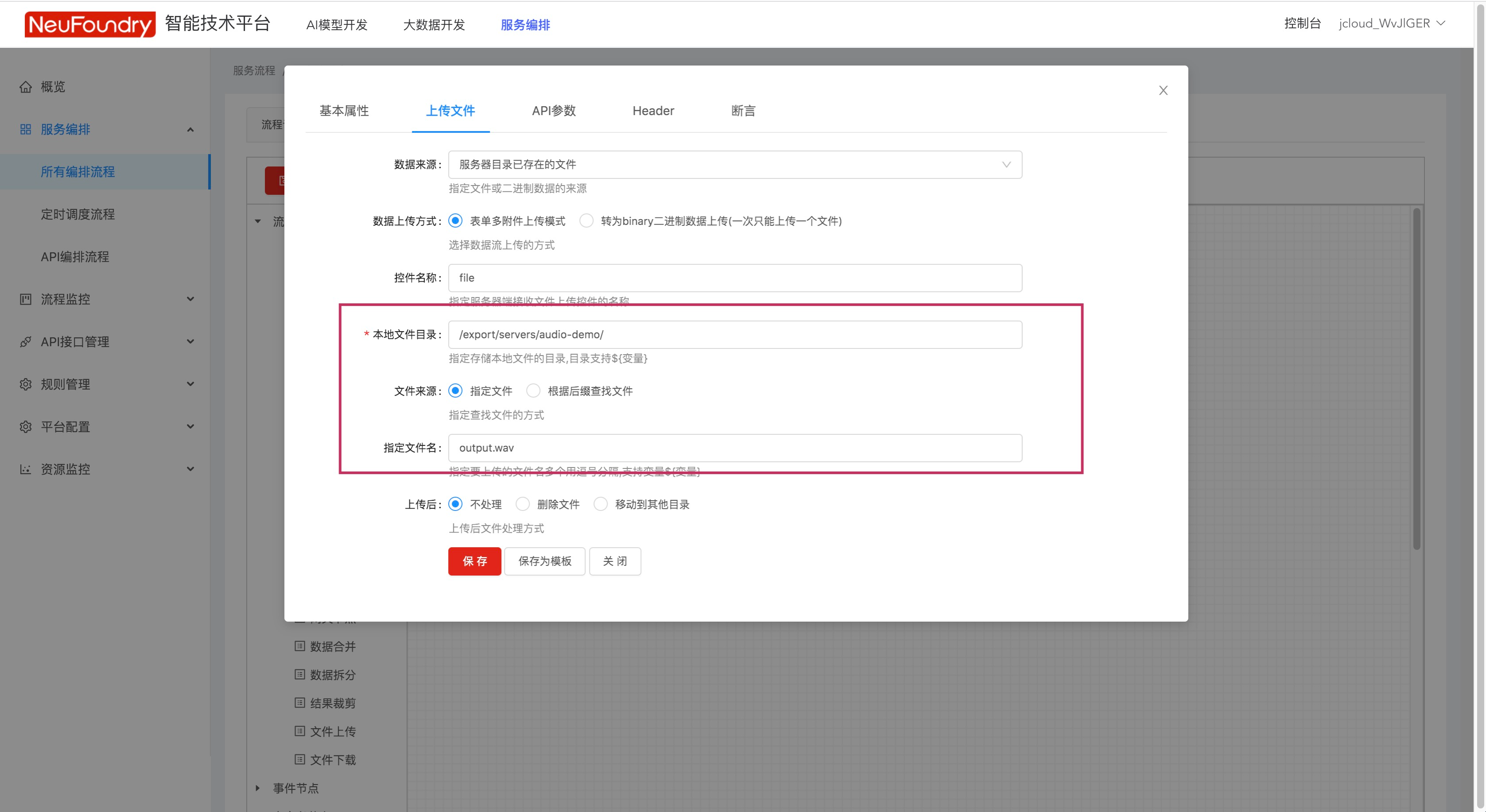 填写完成后,点击运行即可调用API
填写完成后,点击运行即可调用API
步骤3. 查看结果
在流程监控-流程运行统计中可以查看执行结果,本次API调用的结果为“有质量问题” 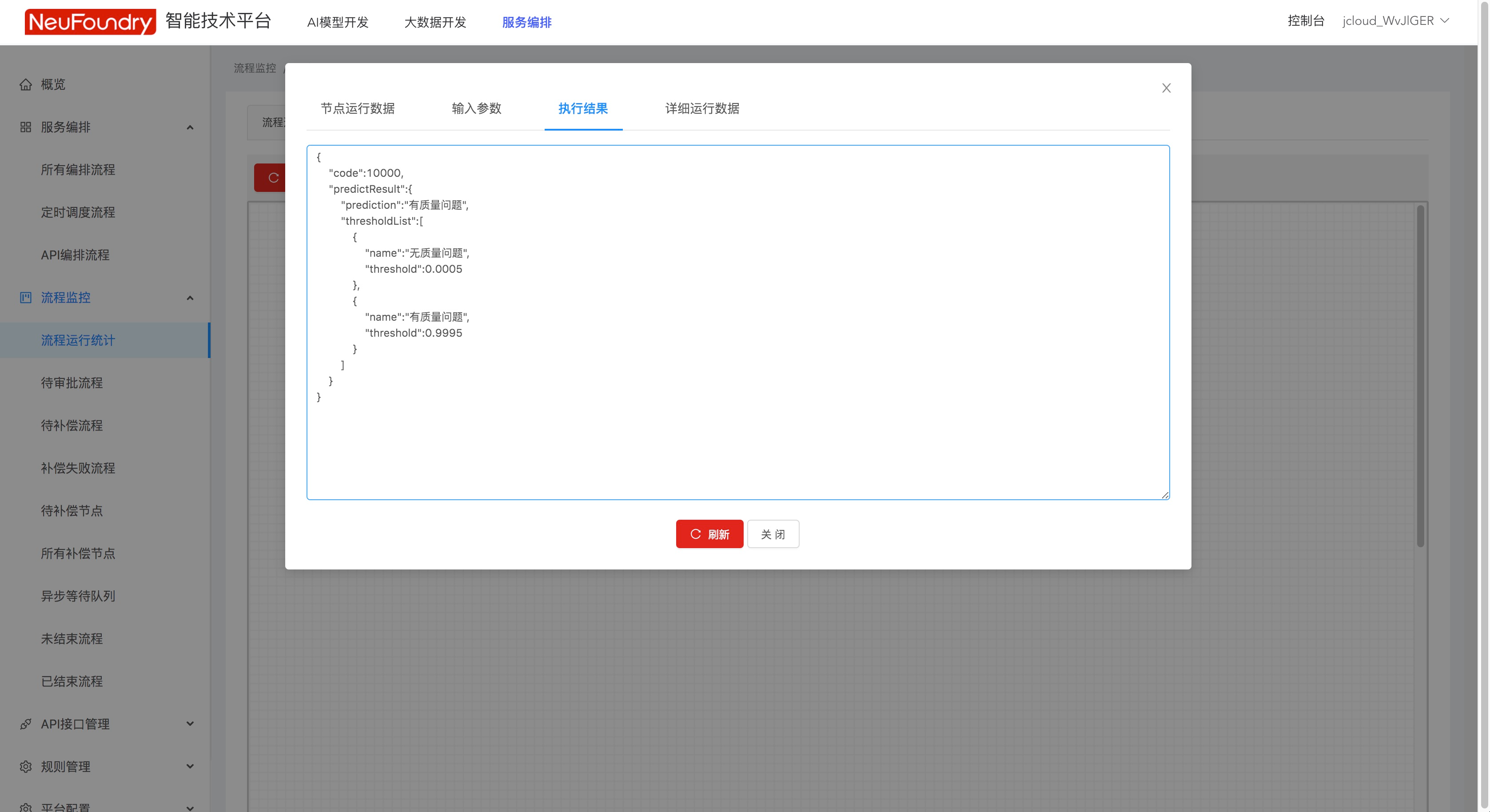

若有收获,就点个赞吧
0 人点赞
