再次强调“纯”
首先,我们要厘清纯函数的概念。
纯函数是这样一种函数,即相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用。
比如 slice 和 splice,这两个函数的作用并无二致——但是注意,它们各自的方式却大不同,但不管怎么说作用还是一样的。我们说 slice 符合纯函数的定义是因为对相同的输入它保证能返回相同的输出。而 splice 却会嚼烂调用它的那个数组,然后再吐出来;这就会产生可观察到的副作用,即这个数组永久地改变了。
var xs = [1,2,3,4,5];// 纯的xs.slice(0,3);//=> [1,2,3]xs.slice(0,3);//=> [1,2,3]xs.slice(0,3);//=> [1,2,3]// 不纯的xs.splice(0,3);//=> [1,2,3]xs.splice(0,3);//=> [4,5]xs.splice(0,3);//=> []
在函数式编程中,我们讨厌这种会改变数据的笨函数。我们追求的是那种可靠的,每次都能返回同样结果的函数,而不是像 splice 这样每次调用后都把数据弄得一团糟的函数,这不是我们想要的。
来看看另一个例子。
// 不纯的var minimum = 21;var checkAge = function(age) {return age >= minimum;};// 纯的var checkAge = function(age) {var minimum = 21;return age >= minimum;};
在不纯的版本中,checkAge 的结果将取决于 minimum 这个可变变量的值。换句话说,它取决于系统状态(system state);这一点令人沮丧,因为它引入了外部的环境,从而增加了认知负荷(cognitive load)。
这个例子可能还不是那么明显,但这种依赖状态是影响系统复杂度的罪魁祸首(http://www.curtclifton.net/storage/papers/MoseleyMarks06a.pdf )。输入值之外的因素能够左右 checkAge 的返回值,不仅让它变得不纯,而且导致每次我们思考整个软件的时候都痛苦不堪。
另一方面,使用纯函数的形式,函数就能做到自给自足。我们也可以让 minimum 成为一个不可变(immutable)对象,这样就能保留纯粹性,因为状态不会有变化。要实现这个效果,必须得创建一个对象,然后调用 Object.freeze( https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Object/freeze)方法:
var immutableState = Object.freeze({minimum: 21});
副作用可能包括…
让我们来仔细研究一下“副作用”以便加深理解。那么,我们在纯函数定义中提到的万分邪恶的副作用到底是什么?“作用”我们可以理解为一切除结果计算之外发生的事情。
“作用”本身并没什么坏处,而且在本书后面的章节你随处可见它的身影。“副作用”的关键部分在于“副”。就像一潭死水中的“水”本身并不是幼虫的培养器,“死”才是生成虫群的原因。同理,副作用中的“副”是滋生 bug 的温床。
副作用是在计算结果的过程中,系统状态的一种变化,或者与外部世界进行的可观察的交互。
副作用可能包含,但不限于:
- 更改文件系统
- 往数据库插入记录
- 发送一个 http 请求
- 可变数据
- 打印/log
- 获取用户输入
- DOM 查询
- 访问系统状态
这个列表还可以继续写下去。概括来讲,只要是跟函数外部环境发生的交互就都是副作用——这一点可能会让你怀疑无副作用编程的可行性。函数式编程的哲学就是假定副作用是造成不正当行为的主要原因。
这并不是说,要禁止使用一切副作用,而是说,要让它们在可控的范围内发生。后面讲到 functor 和 monad 的时候我们会学习如何控制它们,目前还是尽量远离这些阴险的函数为好。
副作用让一个函数变得不纯是有道理的:从定义上来说,纯函数必须要能够根据相同的输入返回相同的输出;如果函数需要跟外部事物打交道,那么就无法保证这一点了。
我们来仔细了解下为何要坚持这种「相同输入得到相同输出」原则。注意,我们要复习一些八年级数学知识了。
八年级数学
根据 mathisfun.com:
函数是不同数值之间的特殊关系:每一个输入值返回且只返回一个输出值。
换句话说,函数只是两种数值之间的关系:输入和输出。尽管每个输入都只会有一个输出,但不同的输入却可以有相同的输出。下图展示了一个合法的从 x 到 y 的函数关系;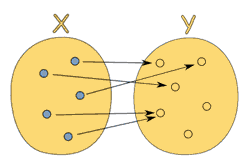 (http://www.mathsisfun.com/sets/function.html)
(http://www.mathsisfun.com/sets/function.html)
相反,下面这张图表展示的就不是一种函数关系,因为输入值 5 指向了多个输出: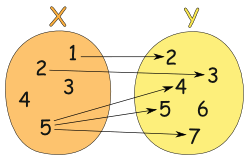 (http://www.mathsisfun.com/sets/function.html)
(http://www.mathsisfun.com/sets/function.html)
函数可以描述为一个集合,这个集合里的内容是 (输入, 输出) 对:[(1,2), (3,6), (5,10)](看起来这个函数是把输入值加倍)。
或者一张表:
| 输入 | 输出 |
|---|---|
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
甚至一个以 x 为输入 y 为输出的函数曲线图: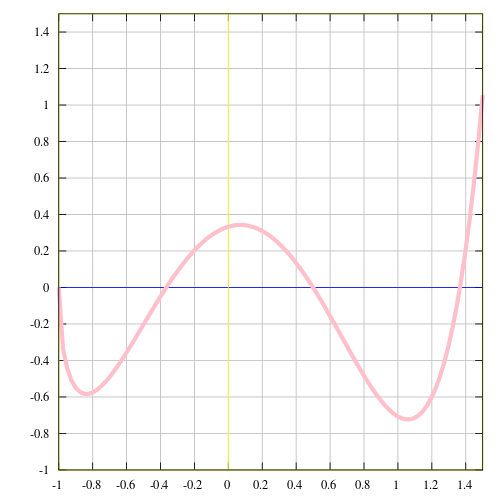
如果输入直接指明了输出,那么就没有必要再实现具体的细节了。因为函数仅仅只是输入到输出的映射而已,所以简单地写一个对象就能“运行”它,使用 [] 代替 () 即可。
var toLowerCase = {"A":"a", "B": "b", "C": "c", "D": "d", "E": "e", "D": "d"};toLowerCase["C"];//=> "c"var isPrime = {1:false, 2: true, 3: true, 4: false, 5: true, 6:false};isPrime[3];//=> true
当然了,实际情况中你可能需要进行一些计算而不是手动指定各项值;不过上例倒是表明了另外一种思考函数的方式。(你可能会想“要是函数有多个参数呢?”。的确,这种情况表明了以数学方式思考问题的一点点不便。暂时我们可以把它们打包放到数组里,或者把 arguments 对象看成是输入。等学习 curry 的概念之后,你就知道如何直接为函数在数学上的定义建模了。)
戏剧性的是:纯函数就是数学上的函数,而且是函数式编程的全部。使用这些纯函数编程能够带来大量的好处,让我们来看一下为何要不遗余力地保留函数的纯粹性的原因。
追求“纯”的理由
可缓存性(Cacheable)
首先,纯函数总能够根据输入来做缓存。实现缓存的一种典型方式是 memoize 技术:
var squareNumber = memoize(function(x){ return x*x; });squareNumber(4);//=> 16squareNumber(4); // 从缓存中读取输入值为 4 的结果//=> 16squareNumber(5);//=> 25squareNumber(5); // 从缓存中读取输入值为 5 的结果//=> 25
下面的代码是一个简单的实现,尽管它不太健壮。
var memoize = function(f) {var cache = {};return function() {var arg_str = JSON.stringify(arguments);cache[arg_str] = cache[arg_str] || f.apply(f, arguments);return cache[arg_str];};};
Note:
cache[arg_str] = cache[arg_str] || f.apply(f, arguments);
第一次执行传入的f函数,第二次如果值一样不需要再执行
值得注意的一点是,可以通过延迟执行的方式把不纯的函数转换为纯函数:
var pureHttpCall = memoize(function(url, params){return function() { return $.getJSON(url, params); }});
这里有趣的地方在于我们并没有真正发送 http 请求——只是返回了一个函数,当调用它的时候才会发请求。这个函数之所以有资格成为纯函数,是因为它总是会根据相同的输入返回相同的输出:给定了 url 和 params 之后,它就只会返回同一个发送 http 请求的函数。
我们的 memoize 函数工作起来没有任何问题,虽然它缓存的并不是 http 请求所返回的结果,而是生成的函数。
现在来看这种方式意义不大,不过很快我们就会学习一些技巧来发掘它的用处。重点是我们可以缓存任意一个函数,不管它们看起来多么具有破坏性。
可移植性/自文档化(Portable / Self-Documenting)
纯函数是完全自给自足的,它需要的所有东西都能轻易获得。仔细思考思考这一点…这种自给自足的好处是什么呢?首先,纯函数的依赖很明确,因此更易于观察和理解——没有偷偷摸摸的小动作。
// 不纯的var signUp = function(attrs) {var user = saveUser(attrs); //依赖了attrs却又使用了saveUser的返回的userwelcomeUser(user);};// 不纯的 使用了外部变量Dbvar saveUser = function(attrs) {var user = Db.save(attrs);...};var welcomeUser = function(user) {Email(user, ...);...};// 纯的var signUp = function(Db, Email, attrs) {return function() {var user = saveUser(Db, attrs);welcomeUser(Email, user);};};var saveUser = function(Db, attrs) {...};var welcomeUser = function(Email, user) {...};
这个例子表明,纯函数对于其依赖必须要诚实,这样我们就能知道它的目的。仅从纯函数版本的 signUp 的签名就可以看出,它将要用到 Db、Email 和 attrs,这在最小程度上给了我们足够多的信息。
后面我们会学习如何不通过这种仅仅是延迟执行的方式来让一个函数变纯,不过这里的重点应该很清楚,那就是相比不纯的函数,纯函数能够提供多得多的信息;前者天知道它们暗地里都干了些什么。
其次,通过强迫“注入”依赖,或者把它们当作参数传递,我们的应用也更加灵活;因为数据库或者邮件客户端等等都参数化了(别担心,我们有办法让这种方式不那么单调乏味)。如果要使用另一个 Db,只需把它传给函数就行了。如果想在一个新应用中使用这个可靠的函数,尽管把新的 Db 和 Email 传递过去就好了,非常简单。
在 JavaScript 的设定中,可移植性可以意味着把函数序列化(serializing)并通过 socket 发送。也可以意味着代码能够在 web workers 中运行。总之,可移植性是一个非常强大的特性。
命令式编程中“典型”的方法和过程都深深地根植于它们所在的环境中,通过状态、依赖和有效作用(available effects)达成;纯函数与此相反,它与环境无关,只要我们愿意,可以在任何地方运行它。
你上一次把某个类方法拷贝到新的应用中是什么时候?我最喜欢的名言之一是 Erlang 语言的作者 Joe Armstrong 说的这句话:“面向对象语言的问题是,它们永远都要随身携带那些隐式的环境。你只需要一个香蕉,但却得到一个拿着香蕉的大猩猩…以及整个丛林”。
可测试性(Testable)
第三点,纯函数让测试更加容易。我们不需要伪造一个“真实的”支付网关,或者每一次测试之前都要配置、之后都要断言状态(assert the state)。只需简单地给函数一个输入,然后断言输出就好了。
事实上,我们发现函数式编程的社区正在开创一些新的测试工具,能够帮助我们自动生成输入并断言输出。这超出了本书范围,但是我强烈推荐你去试试 Quickcheck——一个为函数式环境量身定制的测试工具。
合理性(Reasonable)
很多人相信使用纯函数最大的好处是引用透明性(referential transparency)。如果一段代码可以替换成它执行所得的结果,而且是在不改变整个程序行为的前提下替换的,那么我们就说这段代码是引用透明的。
由于纯函数总是能够根据相同的输入返回相同的输出,所以它们就能够保证总是返回同一个结果,这也就保证了引用透明性。我们来看一个例子。
var Immutable = require('immutable');var decrementHP = function(player) {return player.set("hp", player.hp-1);};var isSameTeam = function(player1, player2) {return player1.team === player2.team;};var punch = function(player, target) {if(isSameTeam(player, target)) {return target;} else {return decrementHP(target);}};var jobe = Immutable.Map({name:"Jobe", hp:20, team: "red"});var michael = Immutable.Map({name:"Michael", hp:20, team: "green"});punch(jobe, michael);//=> Immutable.Map({name:"Michael", hp:19, team: "green"})
decrementHP、isSameTeam 和 punch 都是纯函数,所以是引用透明的。我们可以使用一种叫做“等式推导”(equational reasoning)的技术来分析代码。所谓“等式推导”就是“一对一”替换,有点像在不考虑程序性执行的怪异行为(quirks of programmatic evaluation)的情况下,手动执行相关代码。我们借助引用透明性来剖析一下这段代码。
首先内联 isSameTeam 函数:
var punch = function(player, target) {if(player.team === target.team) {return target;} else {return decrementHP(target);}};
因为是不可变数据,我们可以直接把 team 替换为实际值:
var punch = function(player, target) {if("red" === "green") {return target;} else {return decrementHP(target);}};
if 语句执行结果为 false,所以可以把整个 if 语句都删掉:
var punch = function(player, target) {return decrementHP(target);};
如果再内联 decrementHP,我们会发现这种情况下,punch 变成了一个让 hp 的值减 1 的调用:
var punch = function(player, target) {return target.set("hp", target.hp-1);};
总之,等式推导带来的分析代码的能力对重构和理解代码非常重要。事实上,我们重构海鸥程序使用的正是这项技术:利用加和乘的特性。对这些技术的使用将会贯穿本书,真的。
并行代码
最后一点,也是决定性的一点:我们可以并行运行任意纯函数。因为纯函数根本不需要访问共享的内存,而且根据其定义,纯函数也不会因副作用而进入竞争态(race condition)。
并行代码在服务端 js 环境以及使用了 web worker 的浏览器那里是非常容易实现的,因为它们使用了线程(thread)。不过出于对非纯函数复杂度的考虑,当前主流观点还是避免使用这种并行。
总结
我们已经了解什么是纯函数了,也看到作为函数式程序员的我们,为何深信纯函数是不同凡响的。从这开始,我们将尽力以纯函数式的方式书写所有的函数。为此我们将需要一些额外的工具来达成目标,同时也尽量把非纯函数从纯函数代码中分离。
如果手头没有一些工具,那么纯函数程序写起来就有点费力。我们不得不玩杂耍似的通过到处传递参数来操作数据,而且还被禁止使用状态,更别说“作用”了。没有人愿意这样自虐。所以让我们来学习一个叫 curry 的新工具。

若有收获,就点个赞吧
0 人点赞
