假设你在某个公司工作,这个公司里经理的待遇与普通员工的待遇存在着一些差异。不过,他们之间也存在着很多相同的地方,例如,他们都领取薪水。只是普通员工在完成本职任务之后仅领取薪水,而经理在完成了预期的业绩之后还能得到奖金。这种情形就需要使用继承。为什么呢?因为需要为经理定义一个新类Manager,并增加一些新功能。但可以重用Employee类中已经编写的部分代码,并保留原来Employee类中的所有字段。从理论上讲,在 Manager 与 Employee之间存在着明显的“is-a”(是)关系,每个经理都是一个员工:“is-a”关系是继承的一个明显特征。
1.1定义子类
可以如下继承Employee类来定义Manager类,这里使用关键字extends表示继承。
关键字extends表明正在构造的新类派生于一个已存在的类。这个已存在的类称为超类( superclass)、基类( base class)或父类( parent class);新类称为子类(( subclass)、派生类( derived class)或孩子类(child class)。超类和子类是Java程序员最常用的两个术语,而了解其他语言的程序员可能更加偏爱使用父类和孩子类,这也能很贴切地体现“继承”。
尽管Employee类是一个超类,但并不是因为它优于子类或者拥有比子类更多的功能。实际上恰恰相反,子类比超类拥有的功能更多。例如,看过Manager类的源代码之后就会发现,Manager类比超类Employee封装了更多的数据,拥有更多的功能。
在Manager类中,增加了一个用于存储奖金信息的字段,以及一个用于设置这个字段的新方法:
然而,尽管在Manager类中没有显式地定义getName和getHireDay等方法,但是可以对Manager对象使用这些方法,这是因为Manager类自动地继承了超类Employee中的这些方法。
类似地,从超类中还继承了name、salary和 hireDay这3个字段。这样一来,每个Manager对象就包含了4个字段:name、salary、hireDay和 bonus。
通过扩展超类定义子类的时候,只需要指出子类与超类的不同之处。因此在设计类的时候,应该将最一般的方法放在超类中,而将更特殊的方法放在子类中,这种将通用功能抽取到超类的做法在面向对象程序设计中十分普遍。
1.2覆盖方法
超类中的有些方法对子类Manager并不一定适用。具体来说,Nanager类中的getSalary方法应该返回薪水和奖金的总和。为此,需要提供一个新的方法来覆盖(override)超类中的这个方法: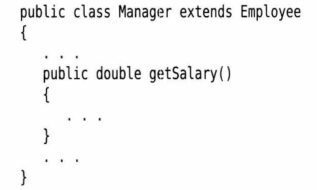
1.3子类构造器
在例子的最后,我们来提供一个构造器。
这里的关键字super具有不同的含义。语句super(name,year,month,day);是“调用超类Employee中带有n、s、year、month和 day参数的构造器”的简写形式。由于Manager类的构造器不能访问Employee类的私有字段,所以必须通过一个构造器来初始化这些私有字段。可以利用特殊的super语法调用这个构造器。使用super调用构造器的语句必须是子类构造器的第一条语句。
如果子类的构造器没有显式地调用超类的构造器,将自动地调用超类的无参数构造器。如果超类没有无参数的构造器,并且在子类的构造器中又没有显式地调用超类的其他构造器,Java编译器就会报告一个错误。
1.4多态
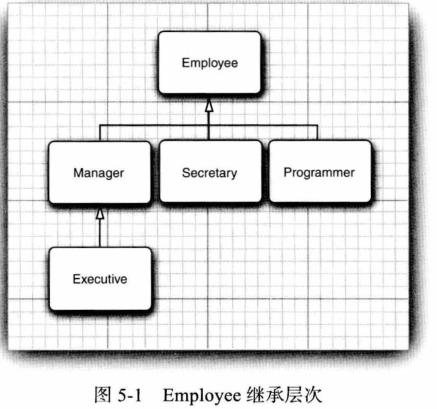
有一个简单规则可以用来判断是否应该将数据设计为继承关系,这就是“ is-a”规则,它指出子类的每个对象也是超类的对象。例如,每个经理都是员工,因此,将Manager类设计为Employee类的子类是有道理的;反之则不然,并不是每一名员工都是经理。
“is-a”规则的另一种表述是替换原则( substitution principle)。它指出程序中出现超类对象的任何地方都可以使用子类对象替换。
例如,可以将子类的对象赋给超类变量。
在Java程序设计语言中,对象变量是多态的( polymorphic.)。一个Employee类型的变量既可以引用一个Employee类型的对象,也可以引用Employee类的任何一个子类的对象(例如,Manager、Executive、Secretary等)。
在这个例子中,变量staff[0]与 boss引用同一个对象。但编译器只将staff[0]看成是一个Employee对象。
这意味着,可以这样调用
boss.setBonus(5000); //OK
但不能这样调用
staff[0].setBonus(5000);//ERROR
这是因为staff[0]声明的类型是Employee,而setBonus不是Employee类的方法。不过,不能将超类的引用赋给子类变量。例如,下面的赋值是非法的:
Manager m = staff[i]; //ERROR
原因很清楚:不是所有的员工都是经理。如果赋值成功,m有可能引用了一个不是经理的Employee对象,而在后面有可能会调用m.setBonus(…),这就会发生运行时错误。
1.5理解方法的调用
准确地理解如何在对象上应用方法调用非常重要。下面假设要调用x.f(args),隐式参数x声明为类C的一个对象。下面是调用过程的详细描述:
1.编译器查看对象的声明类型和方法名。需要注意的是:有可能存在多个名字为f但参数类型不一样的方法。例如,可能存在方法 f(int)和方法 f(String)。编译器将会一一列举C类中所有名为f的方法和其超类中所有名为f而且可访问的方法(超类的私有方法不可访问)。
至此,编译器已知道所有可能被调用的候选方法。
2.接下来,编译器要确定方法调用中提供的参数类型。如果在所有名为f的方法中存在一个与所提供参数类型完全匹配的方法,就选择这个方法。这个过程称为重载解析( overloading resolution)。例如,对于调用x.f(“Hello”),编译器将会挑选 f(String),而不是f(int)。由于允许类型转换( int可以转换成double,Manager可以转换成Employee,等等),所以情况可能会变得很复杂。如果编译器没有找到与参数类型匹配的方法,或者发现经过类型转换后有多个方法与之匹配,编译器就会报告一个错误。
至此,编译器已经知道需要调用的方法的名字和参数类型。
注释:前面曾经说过,方法的名字和参数列表称为方法的签名。例如,f(int)和f(String)是两个有相同名字、不同签名的方法。如果在子类中定义了一个与超类签名相同的方法,那么子类中的这个方法就会覆盖超类中这个相同签名的方法。
返回类型不是签名的一部分。不过在覆盖一个方法时,需要保证返回类型的兼容性。允许子类将覆盖方法的返回类型改为原返回类型的子类型。例如,假设Employee类有以下方法:
经理不会想找这种底层员工作搭档。为了反映这一点,在子类Manager中,可以如下覆盖这个方法:
我们说,这两个getBuddy方法有可协变的返回类型。

若有收获,就点个赞吧
0 人点赞
