一个sql执行很慢的就叫慢sql,一般来说sql语句执行超过5s就能够算是慢sql,需要进行优化了,下面这篇文章主要就为什么要对慢SQL进行治理以及一些治理原理和操作方案做介绍,请看正文。
正文
为何要对慢SQL进行治理
每一个SQL都需要消耗一定的I/O资源,SQL执行的快慢直接决定了资源被占用时间的长短。假设业务要求每秒需要完成100条SQL的执行,而其中10条SQL执行时间长导致每秒只能完成90条SQL,所有新的SQL将进入排队等待,直接影响业务
治理的优先级
master数据库->slave数据库:采用读写分离架构,读在从库slave上执行,写在主库master上执行。但由于从库的数据都是在主库复制过去的,主库如果等待较多的情况,会加大从库的复制延时
执行SQL次数多的优先治理
某张表被高并发集中访问的优先治理
MySQL执行原理
为了更好的优化慢SQL,我们来简单了解下MySQL的执行原理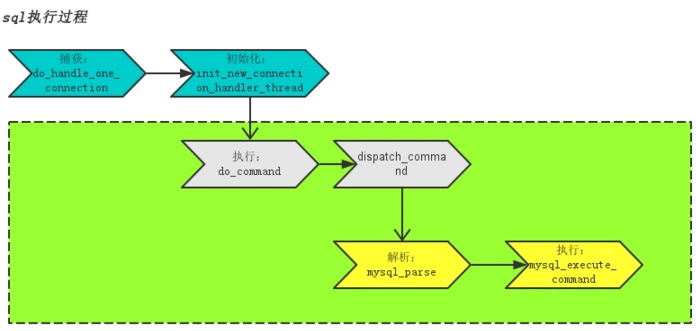
绿色部分为SQL实际执行部分,主要分为两步:
解析:词法解析->语法解析->逻辑计划->查询优化->物理执行计划,过程中会检查缓存是否可用,如果没有可用缓存则进入下一步mysql_execute_command执行
执行:检查用户、表权限->表加上共享读锁->取数据到query_cache->取消共享读锁
如何发现慢查询SQL
-- 修改慢查询时间,只能当前会话有效;set long_query_time=1; -- 启用慢查询 ,加上global,不然会报错的;set global slow_query_log='ON';-- 是否开启慢查询;show variables like "%slow%";-- 查询慢查询SQL状况;show status like "%slow%"; -- 慢查询时间(默认情况下MySQL认位10秒以上才是慢查询)show variables like "long_query_time";
除了sql的方式,我们也可以在配置文件(my.ini)中修改,加入配置时必须要在[mysqld]后面加入
-- 开启日志;slow_query_log = on -- 记录日志的log文件(注意:window上必须写绝对路径)slow_query_log_file = D:/mysql5.5.16/data/showslow.log-- 最长查询的秒数;long_query_time = 2 -- 表示记录没有使用索引的查询logqueriesnotusingindexes
开启慢查询会带来CPU损耗与日志记录的IO开销,所以建议间断性的打开慢查询日志来观察MySQL运行状态
慢查询分析示例
**SELECT** * **FROM**emp**where** ename **like** '%mQspyv%';
执行时间为1.163s,而我们设置的慢查询时间为1s,这时我们可以打开慢查询日志进行日志分析:
# Time: 150530 15:30:58 -- 该查询发生在2015530 15:30:58# User@Host: root[root] @ localhost [127.0.0.1] --是谁,在什么主机上发生的查询# Query_time: 1.134065 Lock_time: 0.000000 Rows_sent: 8 Rows_examined: 4000000 Query_time: --查询总共用了多少时间,Lock_time: 在查询时锁定表的时间,Rows_sent: 返回多少rows数据,Rows_examined: 表扫描了400W行数据才得到的结果;
如果我们的慢SQL很多,人工分析肯定分析不过来,这时候我们就需要借助一些分析工具,MySQL自带了一个慢查询分析工具mysqldumpslow,以下是常见使用示例
mysqldumpslow s c t 10 /var/run/mysqld/mysqldslow.log # 取出使用最多的10条慢查询mysqldumpslow s t t 3 /var/run/mysqld/mysqldslow.log # 取出查询时间最慢的3条慢查询mysqldumpslow s t t 10 g “left join” /database/mysql/slowlog #得到按照时间排序的前10条里面含有左连接的查询语句mysqldumpslow s r t 10 g 'left join' /var/run/mysqld/mysqldslow.log # 按照扫描行数最多的
SQL语句常见优化
只要简单了解过MySQL内部优化机制,就很容易写出高性能的SQL
1.不使用子查询:
**SELECT** * **FROM** t1 **WHERE** **id** (**SELECT** **id** **FROM** t2 **WHERE** **name**='hechunyang');
在MySQL5.5版本中,内部执行计划器是先查外表再匹配内表,如果外表数据量很大,查询速度会非常慢
在MySQL5.6中,有对内查询做了优化,优化后SQL如下**SELECT** t1.* **FROM** t1 **JOIN** t2 **ON** t1.id = t2.id;
但也仅针对select语句有效,update、delete子查询无效,所以生成环境不建议使用子查询
2.避免函数索引
**SELECT** * **FROM** t **WHERE** **YEAR**(d) >= 2016;
即使d字段有索引,也会全盘扫描,应该优化为:**SELECT** * **FROM** t **WHERE** d >= '2016-01-01';
3.使用IN替换OR
**SELECT** * **FROM** t **WHERE** LOC_ID = 10 **OR** LOC_ID = 20 **OR** LOC_ID = 30;
非聚簇索引走了3次,使用IN之后只走一次:**SELECT** * **FROM** t **WHERE** LOC_IN **IN** (10,20,30);
4.LIKE双百分号无法使用到索引
**SELECT** * **FROM** t **WHERE** **name** **LIKE** '%de%';
应优化为右模糊**SELECT** * **FROM** t **WHERE** **name** **LIKE** 'de%';
5.增加LIMIT M,N 限制读取的条数
6.避免数据类型不一致
**SELECT** * **FROM** t **WHERE** **id** = '19';
应优化为**SELECT** * **FROM** t **WHERE** **id** = 19;
7.分组统计时可以禁止排序
**SELECT** goods_id,**count**(*) **FROM** t **GROUP** **BY** goods_id;
默认情况下MySQL会对所有GROUP BY co1,col2 …的字段进行排序,我们可以对其使用ORDER BY NULL禁止排序,避免排序消耗资源**SELECT** goods_id,**count**(*) **FROM** t **GROUP** **BY** goods_id **ORDER** **BY** **NULL**;
8.去除不必要的ORDER BY语句
总结
总的来说,我们知道曼查询的SQL后,优化方案可以做如下尝试:
- SQL语句优化,尽量精简,去除非必要语句
- 索引优化,让所有SQL都能够走索引
- 如果是表的瓶颈问题,则分表,单表数据量维持在1000W以内
- 如果是单库瓶颈问题,则分库,读写分离
- 如果是物理机器性能问题,则分多个数据库节点
假设我们有一条SQL

若有收获,就点个赞吧
0 人点赞
