一、基本概述
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况。
MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。大家可以在
https://www.eclipse.org/mat/downloads.php下载并使用MAT。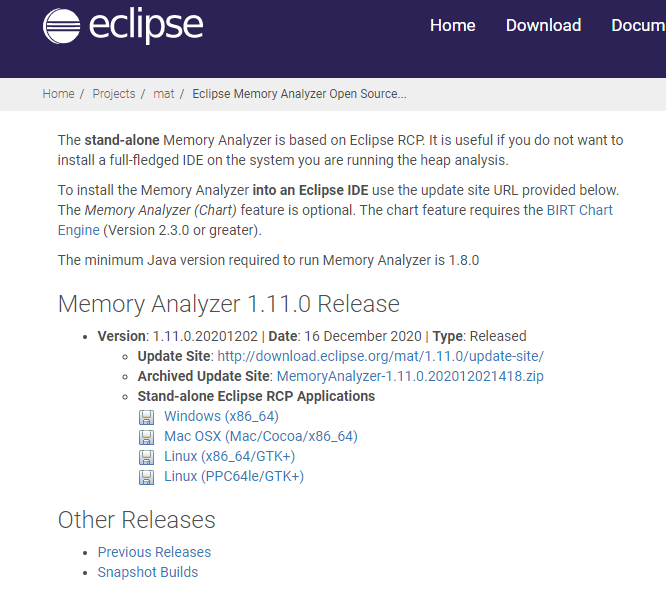
只要确保机器上装有DK并配置好相关的环境变量,MAT可正常启动。
还可以在Eclipse中以插件的方式安装: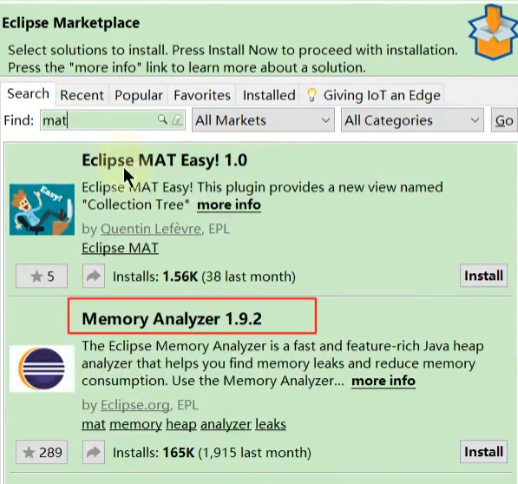
二、获取堆dump文件
2.1、dump文件内容
MAT可以分析heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观地看到当前的内存信息。
一般说来,这些内存信息包含:
- 所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值。
- 所有的类信息,包括classloader、类名称、父类、静态变量等.
- GCRoot到所有的这些对象的引用路径
- 线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)
2.2、两点说明
说明1:缺点:
MAT不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如Sun,HP,SAP所采用的 HPROF 二进制堆存储文件,以及IBM的 PHD堆存储文件等都能被很好的解析。说明2:
最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到一键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现。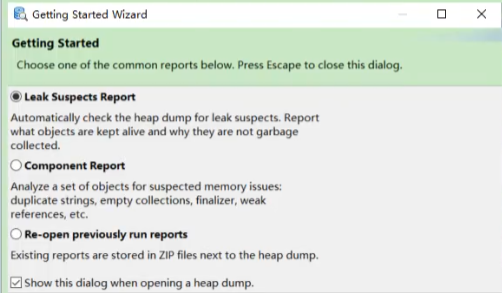
2.3、获取dump文件
方法一:通过前一章介绍的 jmap工具生成,可以生成任意一个java进程的dump文件;
方法二:通过配置JVM参数生成。
- 选项”-XX:+HeapDumpOnoutOfMemoryError”或”-XX:+HeapDumpBeforeFullGC”
- 选项”-XX:HeapDumpPath”所代表的含义就是当程序出现OutofMemory时,将会在相应的目录下生成一份dump文件。如果不指定选项“XX:HeapDumpPath”则在当前目录下生成dump文件。
对比:考虑到生产环境中几乎不可能在线对其进行分析,大都是采用离线分析,因此使用jmap+MAT工具是最常见的组合。
方法三:使用visualVM可以导出堆dump文件
方法四:
使用MAT既可以打开一个己有的堆快照,也可以通过MAT直接从活动Java程序中导出堆快照。该功能将借助jps列出当前正在运行的Java进程,以供选择并获取快照。
打开一dump文件会出现下列选项:
第一个:泄漏疑点的报告
自动检测堆的dump文件,查看那些是堆内存泄漏的疑点,报告中那些对象还是存活的以及他们为什么没有被垃圾回收器所收集。
第二个:组件报告
会分析一系列对象的集合,找到可以的内存空间,例如:重复的字符串、空集合、终结器、弱引用等等
第三个:打开一个之前运行过的报告
之前存在过的报告会保存在dump文件下同一个目录下的zip文件里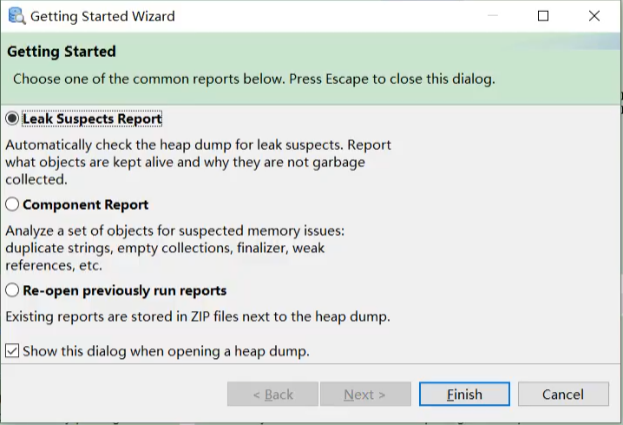
三、分析堆dump文件
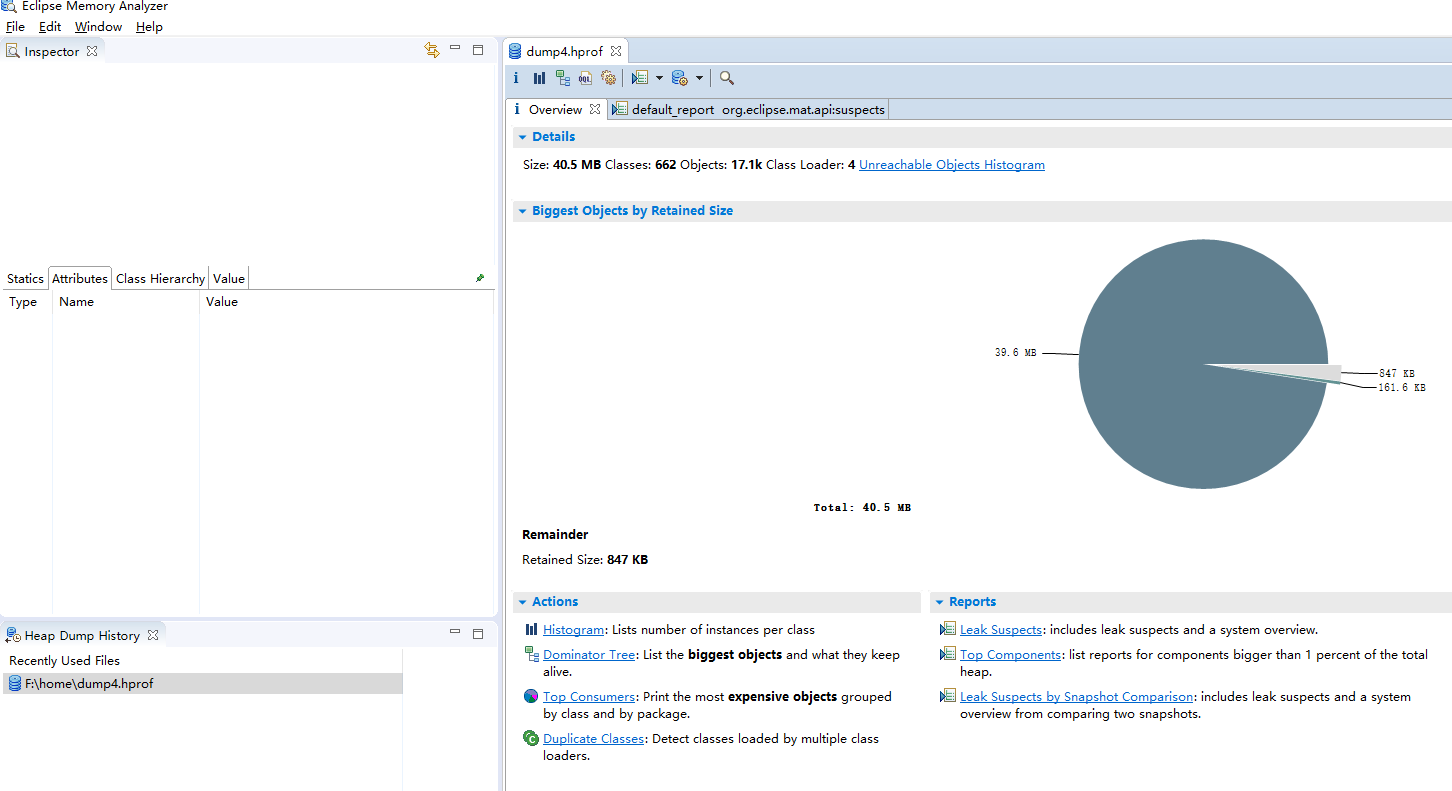
3.1、histogram
展示了各个类的实例数目以及这些实例的Shallow Heap 或Retained Heap的总和。
Shallow Heap即浅堆,表示对象消耗内存的大小,不包括对象内所引用的其他对象的大小计算。
Retained Heap即深堆,是Shallow Heap的总和,当对象被回收了及其相关数据被回收的总大小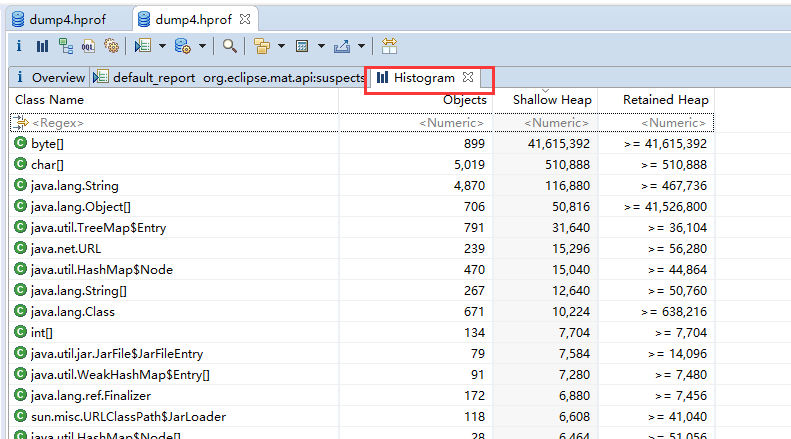
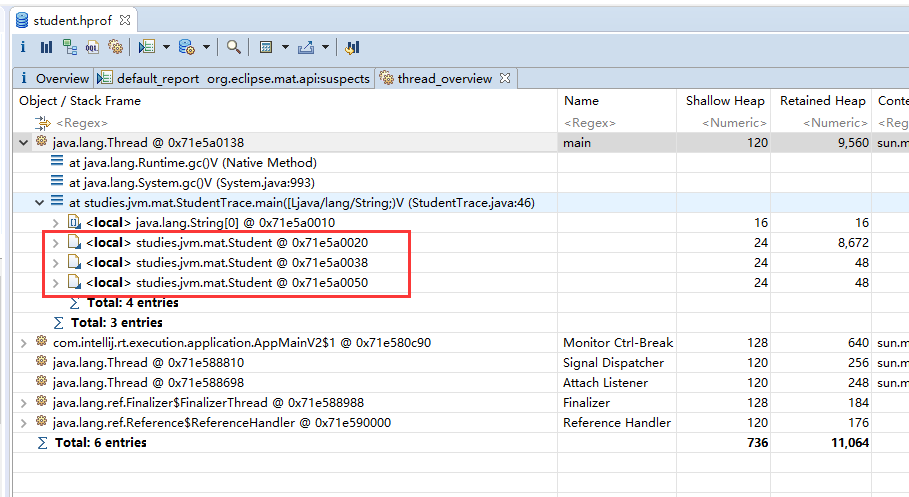
3.2、thread overview
查看系统中的Java线程
查看局部变量的信息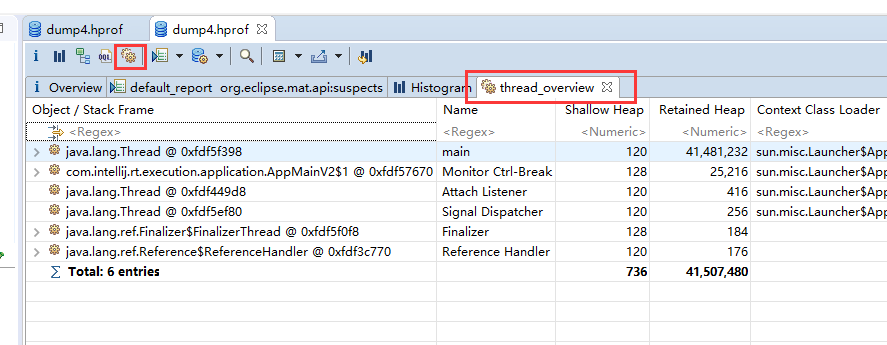
第一个是main线程,其他的都是守护线程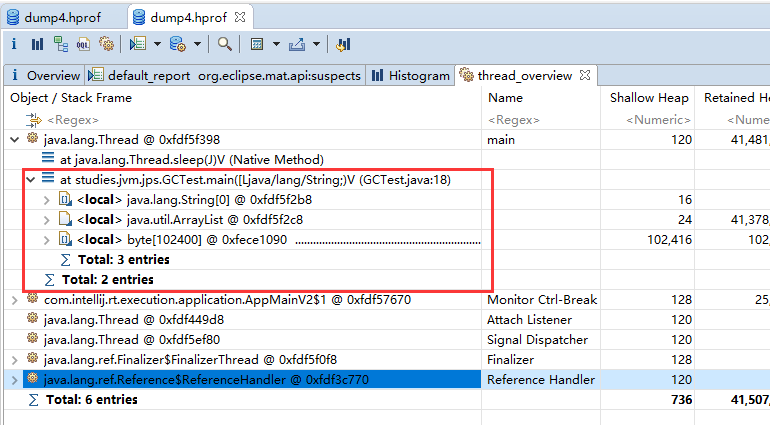
local表示当前线程的局部变量,java.lang.String[0]是main方法的形参args,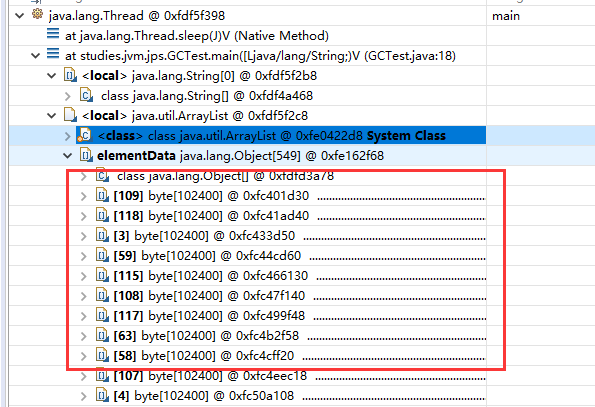
java.util.ArrayList下的elementData里存的是ArrayList存的值
3.3、获得对象相互引用的关系
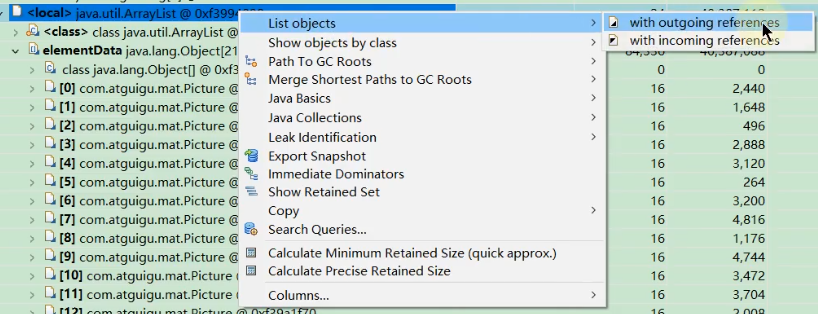
with outgoing references
with outgoing references表示这个ArrayList它引用过那些对象
点击with outgoing references发现ArrayList的elementData都是byte对象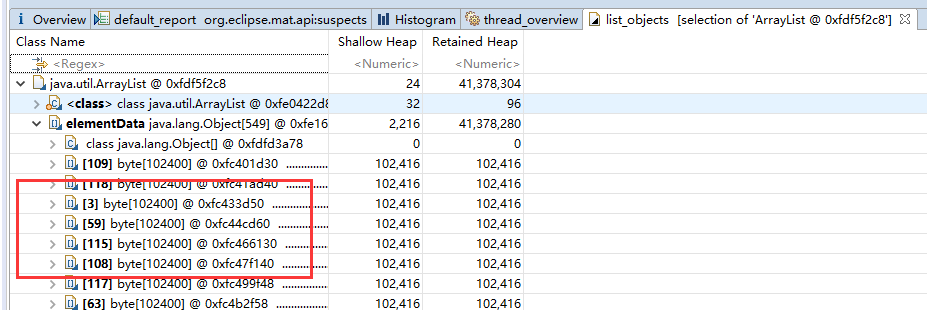
with incoming references
with incoming refefences 表示有那些对象引用了ArrayList
在我的测试代码中在main方法中,我的ArrayList对象只存了byte对象,这里只有Object引用byte对象是正常的,如果有其他对象引用到就要检查代码,是那个对象引用的,这样就可能找到内存泄漏的问题点。
3.4、浅堆与深堆
3.4.1、shallow heap
浅堆(Shallow Heap)是指一个对象所消耗的内存。在32位系统中,一个对象引用会占据4个字节,一个int类型会占据4个字节,long型变量会占据8个字节,每个对象头需要占用8个字节。根据堆快照格式不同,对象的大小可能会向8字节进行对齐。
以String为例:2个int值共占8字节,对象引用占用4字节,对象头8字节,合计20字节,向8字节对齐(用8除不尽),故占24字节。(jdk7中)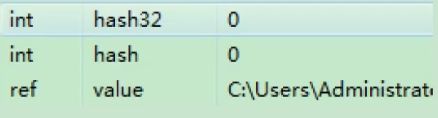
这24字节为String对象的浅堆大小。它与String的value实际取值无关,无论字符串长度如何,浅堆大小始终是24字节。
3.4.2、retained heap
保留集(Retained Set):
对象A的保留集指当对象A被垃圾回收后,可以被释放的所有的对象集合(包括对象A本身),即对象A的保留集可以被认为是只能通过对象A被直接或间接访问到的所有对象的集合。通俗地说,就是指仅被对象A所持有的对象的集合。简单的讲,就是可以被回收的就称为保留集
深堆(Retained Heap):
深堆是指对象的保留集中所有的对象的浅堆大小之和。
注意:浅堆指对象本身占用的内存,不包括其内部引用对象的大小。一个对象的深堆指只能通过该对象访问到的(直接或间接)所有对象的浅堆之和,即对象被回收后,可以释放的真实空间。
3.4.3、补充:对象实际大小团
另外一个常用的概念是对象的实际大小。这里,对象的实际大小定义为一个对象所能触及的所有对象的浅堆大小之和,也就是通常意义上我们说的对象大小。与深堆相比,似乎这个在日常开发中更为直观和被人接受,但实际上,这个概念和垃圾回收无关。
下图显示了一个简单的对象引用关系图,对象A引用了C和D,对象B引用了C和E。那么对象A的浅堆大小只是A本身,不含C和D,而A的实际大小为A、C、D三者之和。而A的深堆大小为A与D之和,由于对象C还可以通过对象B访问到,因此不在对象A的深堆范围内。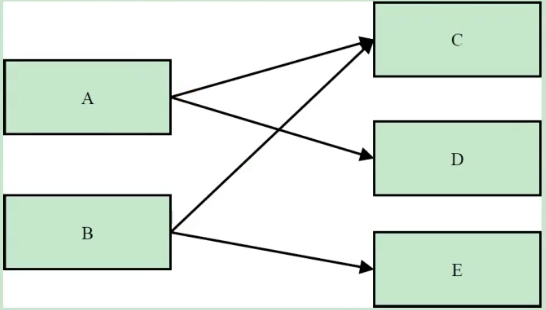
3.4.4、练习
看图理解Retained Size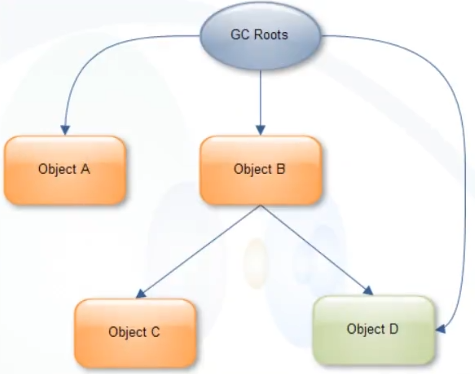
上图中,GC Roots直接引用了A和B两个对象。
A对象的Retained Size=A对象的Shallow Size
B对象的Retained Size=B对象的Shallow size + C对象的Shallow size
这里不包括D对象,因为D对象被GC Roots直接引用。
如果GC Roots不引用D对象呢?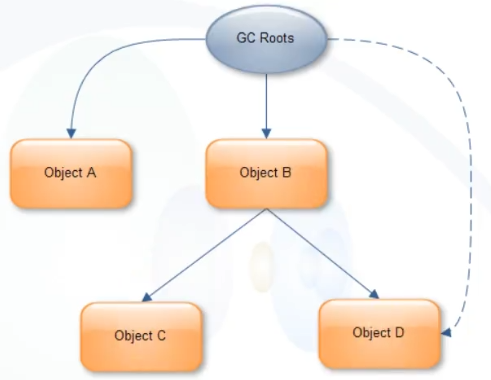
此时的B对象的Retained Size=B对象的Shallow size + C对象的Shallow size + D对象的Shallow size
3.4.5、案例分析: StudentTrace
代码:
package studies.jvm.mat;import java.util.ArrayList;import java.util.List;/*** @author: wuchang* @Date: 2021/5/17* @Time: 8:03* @BelongsProject base* @BelongsPackage studies.jvm.mat* 有一个学生浏览网页的记录程序,它将记录每个学生访问过的网站地址。* 它由三个部分组成: Student、webPage和StudentTrace三个类* 获取dump文件的参数* -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=F:\home\dump\student.hprof*/public class StudentTrace {static List<WebPage> webPages = new ArrayList<>();public static void createWebPages(){for (int i = 0; i < 100; i++){WebPage wp = new WebPage();wp.setUrl("http://www."+Integer.toString(i)+".com");wp.setContent(Integer.toString(i));webPages.add(wp);}}public static void main(String[] args) {//创建了100个网页createWebPages();//创建3个学生对象Student st3 = new Student(3, "Tom");Student st5 = new Student(5, "Jerry");Student st7 = new Student(7, "Lily");for (int i = 0; i < webPages.size(); i++){if (i % st3.getId() == 0){st3.visit(webPages.get(i));}if (i % st5.getId() == 0){st5.visit(webPages.get(i));}if (i % st7.getId() == 0){st7.visit(webPages.get(i));}}webPages.clear();System.gc();}}class Student{private int id;private String name;private List<WebPage> history = new ArrayList<>();public Student(int id, String name) {super();this.id = id;this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public List<WebPage> getHistory() {return history;}public void setHistory(List<WebPage> history) {this.history = history;}public void visit(WebPage wp){if (wp != null){history.add(wp);}}}class WebPage{private String url;private String content;public String getUrl() {return url;}public void setUrl(String url) {this.url = url;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}}
生成的dump文件
在线程中可以看到创建的3个学生对象
Shallow Heap的计算方式,首先Student对象中,id、name、history都是占4个字节,对象头占8个字节,加起来是20,但要进行8对其,所以是24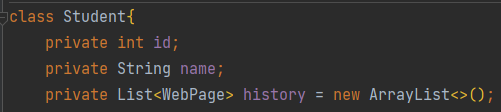
如果Tom要被回收就会回收掉8672个字节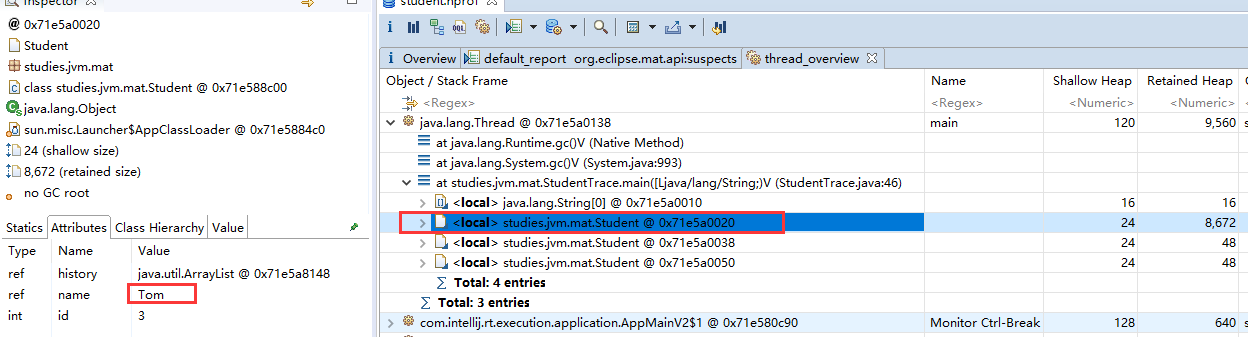
针对lily对象进行分析

lily下的history对象中数组为0的位置的对象被Tom、Jerry、Lily引用这,所以很难被回收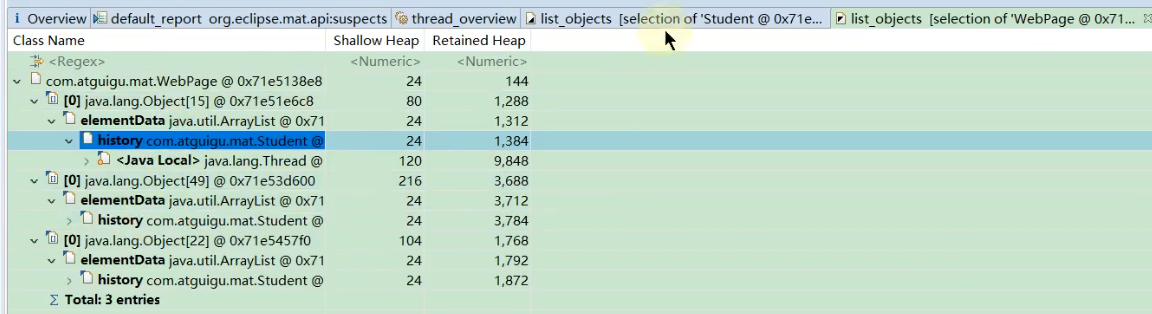
深堆浅堆那里优点问题:示例中的Lily深堆是1312,正确的算法应该如下所示:
深堆1312 = 集合深堆(1288=集合浅堆(80)+ 集合元素深堆1208(7个152,一个144(元素7的深堆是144),))+ 自身浅堆(Lily对象浅堆24)。
根据上面的推算得出结论:一个对象的深堆应该是此对象保留集中能直接访问的对象的深堆之和+自身的浅堆
3.5、支配树
支配树( Dominator Tree)支配树的概念源自图论。
MAT提供了一个称为支配树(Dominator Tree)的对象图。支配树体现了对象实例间的支配关系。在对象引用图中,所有指向对象B的路径都经过对象A,则认为对象A支配对象B。如果对象A是离对象B最近的一个支配对象,则认为对象A为对象B的直接支配者。支配树是基于对象间的引用图所建立的,它有以下基本性质:
- 对象A的子树(所有被对象A支配的对象集合)表示对象A的保留集(retained set),即深堆。
- 如果对象A支配对象B,那么对象A的直接支配者也支配对象B。
- 支配树的边与对象引用图的边不直接对应。
如下图所示:左图表示对象引用图,右图表示左图所对应的支配树。对象A和B由根对象直接支配,由于在到对象c的路径中,可以经过A,也可以经过B,因此对象c的直接支配者也是根对象。对象F与对象D相互引用,因为到对象F的所有路径必然经过对象D,因此,对象D是对象F的直接支配者。而到对象D的所有路径中,必然经过对象c,即使是从对象F到对象D的引用,从根节点出发,也是经过对象C的,所以,对象D的直接支配者为对象C。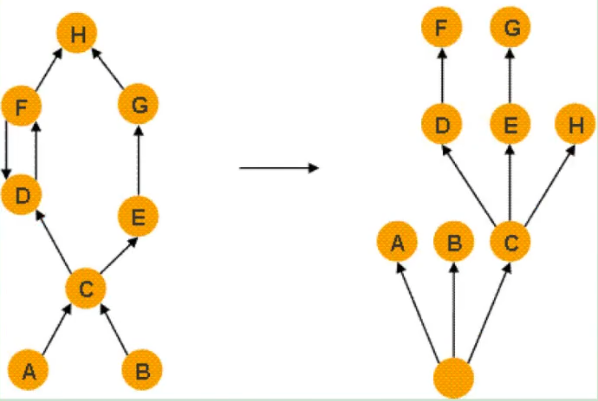
同理,对象E支配对象6。到达对象H的可以通过对象D,也可以通过对象E,因此对象D和E都不能支配对象H,而经过对象C既可以到达D也可以到达E,因此对象c为对象H的直接支配者。
在MAT中,单击工具栏上的对象支配树按钮,可以打开对象支配树视图。
下图显示了对象支配树视图的一部分。该截图显示部分Lily学生的history队列的直接支配对象。即当Lily对象被回收,也会一并回收的所有对象。显然能被3或者5整除的网页不会出现在该列表中,因为它们同时被另外两名学生对象引用。
下面是支配树图,回收Lily就只能回收它下面的15个对象,跟线程图不一样,线程图有几十个对象,但webPages数组中只有15个对象只被Lily对象直接引用。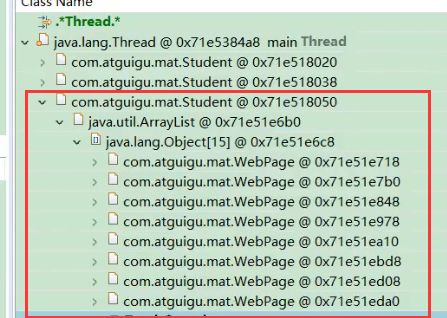
四、案例:Tomcat堆溢出分析
4.1、说明
Tomcat是最常用的Java Servlet容器之一,同时也可以当做单独的web服务器使用。Tomcat本身使用Java实现,并运行于Java虚拟机之上。在大规模请求时,Tomcat有可能会因为无法承受压力而发生内存溢出错误。这里根据一个被压垮的Tomcat的堆快照文件,来分析Tomcat在崩溃时的内部情况。
4.2、分析过程
图一:
Size:是堆空间的大小
Classes:是类的个数,这li是三千两百个
Object:是对象个数,这里是八十三万三千八百个
Class Loader:类的加载器,这里是三十三个
Retained Size:大对象的大小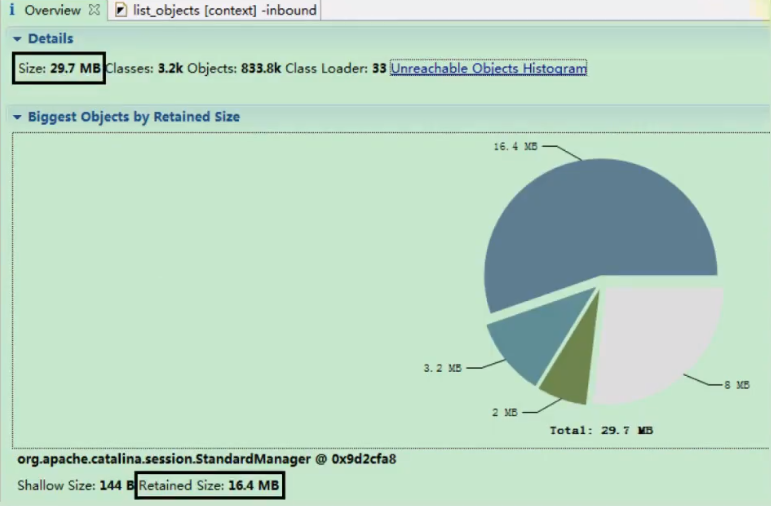
图2
查看大对象都引用了那些对象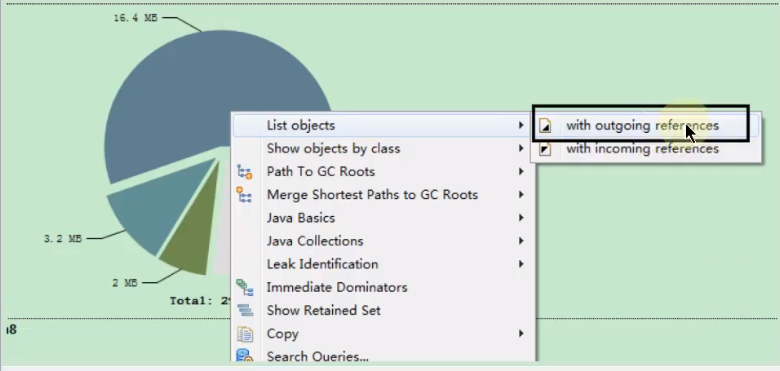
图3: sessions对象,它占用了约17MB空间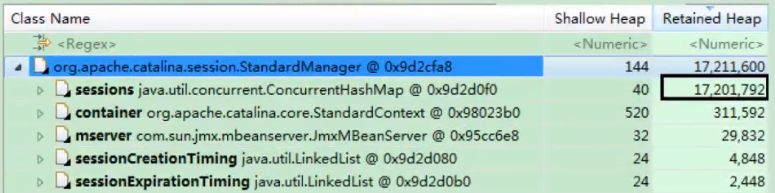
图4:可以看到sessions对象为ConcurrentHashMap,其内部分为16个Segment。从深堆大小看,每个Segment都比较平均,大约为1MB,合计17MB。
图5:
图6:当前堆中含有9941个session,并且每一个session的深堆为1592字节,合计约15NB,达到当前堆大小的50%。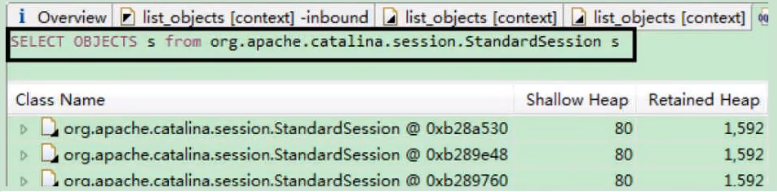
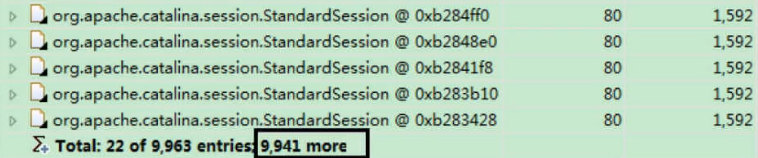
图7: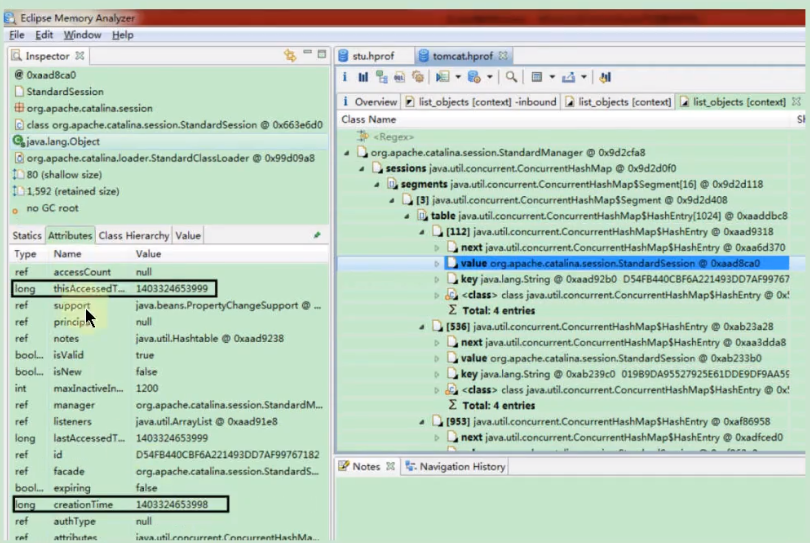
图8: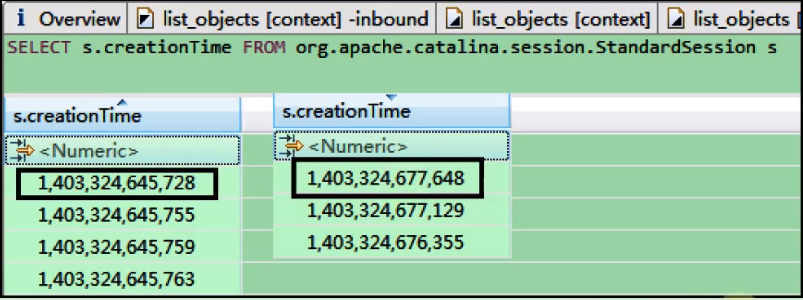
根据当前的session总数,可以计算每秒的平均压力为: 9941/(1403324677648-1403324645728)*1000=311次/秒。
由此推断,在发生Tomcat堆溢出时,Tomcat在连续3o秒的时间内,平均每秒接收了约311次不同客户端的请求,创建了合计9941个session。
五、支持使用OQL语言查询对象信息

若有收获,就点个赞吧
0 人点赞
