引用的作用是关联对象。通常我们使用 new 关键字来创建对象。new 关键字表达的意思是 “我要一个这种类型的对象”。所以在之前的例子中,你可以这样编写代码:
String s = new String("asdf");
这一行代码不仅代表了“创建一个新的字符串”,同时也告诉我们如何通过一组字符来创建 String 对象。
除了 String 以外,Java 还提供了大量的预置类型可供选择。此外,你还可以创建新类型。实际上,创建新类型是 Java 编程的一项基础操作,你将在本书的后续章节中学习相关内容。
3.2.1 数据保存在哪里
当程序运行时,能够可视化其内容的排布方式是十分有帮助的,对于内存管理来说尤其如此。下面列举了 5 种数据存储方式。
- 寄存器(register)。这是速度最快的数据存储方式,因为它保存数据的位置不同于其他方式:数据会直接保存在中央处理器(central processing unit, CPU)里2。然而寄存器的数量是有限的,所以只能按需分配。此外,你不能直接控制寄存器的分配,甚至你在程序中都找不到寄存器存在过的证据( C 和 C++ 是例外,它们允许你向编译器申请分配寄存器)。
- 栈(stack)。数据存储在随机存取存储器(random-access memory, RAM)里,处理器可以通过栈指针(stack pointer)直接操作该数据。具体来说,栈指针向下移动将申请一块新的内存,向上移动则会释放这块内存。这是一种极其迅速和高效的内存分配方式,其效率仅次于寄存器。只不过 Java 系统在创建应用程序时就必须明确栈上所有对象的生命周期。这种限制约束了程序的灵活性,因此虽然有一些数据会保存在栈上(尤其是对象引用),对象本身却并非如此。
- 堆(heap)。这是一个通用的内存池(使用的也是RAM空间),用于存放所有 Java 对象。与栈不同的是,编译器并不关心位于堆上的对象需要存在多久。因此,堆的使用是非常灵活的。比如,当你需要一个对象时,可以随时使用new来创建这个对象,那么当这段代码被执行时,Java 会在堆上为该对象分配内存空间。然而这种灵活性是有代价的:分配和清理堆存储要比栈存储花费更多的时间(如果你可以像 C++ 那样在栈上创建对象的话)。好消息是,随着时间的推移,Java 的堆内存分配机制已经变得非常高效了,所以你并不需要太过关注此类问题。
- 常量存储(constant storage)。常量通常会直接保存在程序代码中,因为它们的值不会改变,所以这样做是安全的。有时候常量会与其他代码隔离开来,于是在某些嵌入系统里,这些常量就可以保存在只读存储器(read-only memory, ROM)中3。
- 非 RAM 存储(non-RAM storage)。如果一段数据没有保存在应用程序里,那么该数据的生命周期既不依赖于应用程序是否运行,也不受应用程序的管制。其中最典型的例子之一是 “序列化对象”(serialized object),它指的是转换为字节流(叫作“序列化”)并可以发送至其他机器的对象。另一个例子则是 “持久化对象”(persistent object),它指的是保存在磁盘上的对象,而这些对象即便在程序结束运行之后也依然能够保持其状态。这些数据存储类型的特点在于,它们会将对象转换成其他形式以保存于其他媒介中,然后在需要的时候重新转换回常规的 RAM 对象。Java 支持轻量级的持久化对象存储,而 JDBC 以及 Hibernate 等库则提供了更为成熟的解决方案,即支持使用数据库存取对象信息。
2大多数微处理器芯片有额外的缓存内存,只不过缓存内存使用的是传统的内存管理方式,而非寄存器。
3一个例子是字符串资源池。所有的字符串和字符串常量都会被自动放置到这个特殊的存储空间中。
3.2.2 特殊情况:基本类型
有一些你经常使用的类型享受特殊待遇,你可以将它们称为 “基本类型”(primitive type)。它们之所以享受特别待遇,是因为 new 关键字是在堆上创建对象,这就意味着哪怕是创建一些简单的变量也不会很高效。对于基本类型,Java 使用了与 C 以及 C++ 相同的实现机制,这意味着我们无须使用 new 来创建基本类型的变量,而是直接创建一个 “自动变量”(automatic variable),注意不是引用。也就是说,该变量会直接在栈上保存它的值4,因此运行效率也较高。
4简单来说:基本数据类型存储的位置取决于变量的声明位置,而不是它的类型,局部变量存储在栈中,实例变量和静态变量存储在堆中。虚拟机栈是主要作用就是执行类定义的方法,方法体的代码执行完基本数据类型也会被清理掉。而实例变量是存在堆中,如果对象被回收,实例变量也会跟着被回收
Java 定义了每一种基本类型所占用的空间大小(见表3-1)。即便是在不同的机器上,这些类型所占用的空间也是保持一致的。而这种一致性也是 Java 程序比其他语言程序移植性更好的原因之一。
表3-1
| 基本类型 | 大小 | 最小值 | 最大值 | 包装类 |
|---|---|---|---|---|
| boolean | — | — | — | Boolean |
| char | 16 位 | Unicode 0 \u0000 | 65 535 \uffff | Character |
| byte | 8 位 | -128 | +127 | Byte |
| short | 16 位 | -32 768 | +32 767 | Short |
| int | 32 位 | -231 | +231-1 | Integer |
| long | 64 位 | -263 | +263-1 | Long |
| float | 32 位 | IEEE754 | IEEE754 | Float |
| double | 64 位 | IEEE754 | IEEE754 | Double |
| void | — | — | — | Void |
表3-1 中的所有数值类型都是有符号的,所以不用在表格中查找无符号类型了。
boolean 类型的空间大小没有明确标出,其对象只能被赋值为 true 或 false。
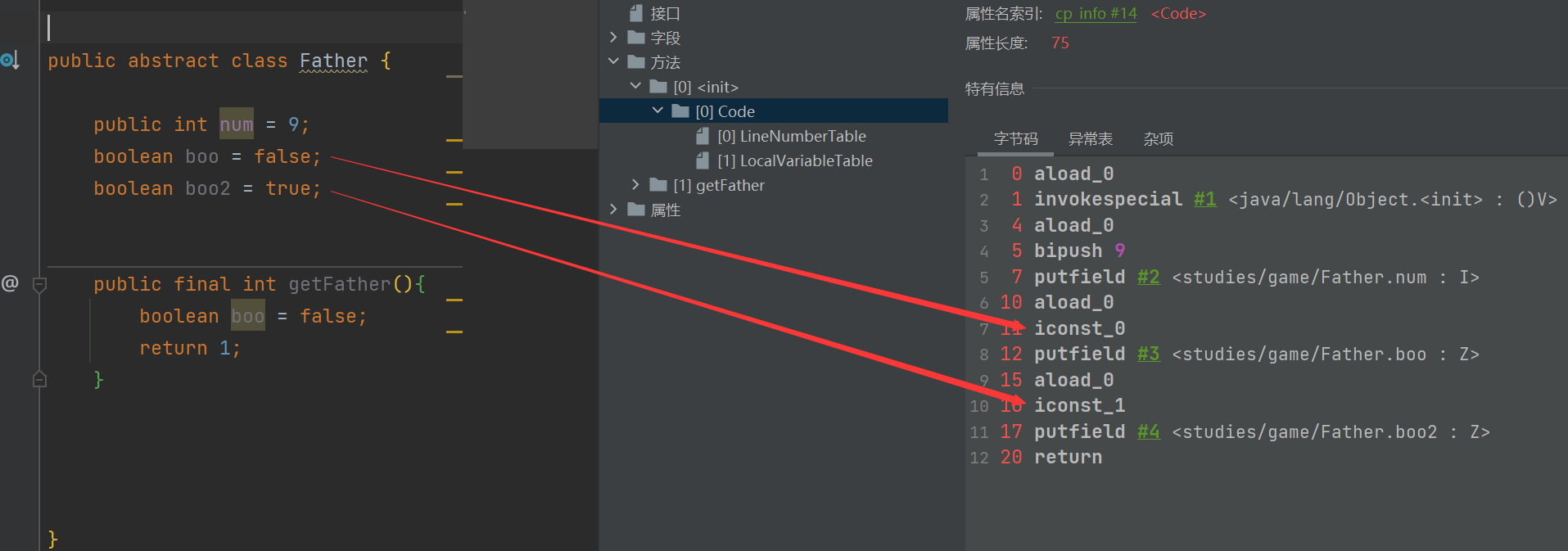
注意:其实查看 boolean 字节码的时候,boolean 其实是大小是 1 bit,最大值就是 1,最小值就是 0
此外,Java 还为基本类型提供了对应的 “包装类”(wrapper class),通过包装类可以将基本类型呈现为位于堆上的非原始对象。例如:
char c = 'x';
Character ch = new Character(c);
也可以这样表示:
Character ch = new Character('x');
而 “自动装箱”(autoboxing)机制能够将基本类型对象自动转换为包装类对象,例如:
Character ch = 'x';
也可以再转换回来,例如:
char c = ch;
高精度数字
Java 提供了两个支持高精度计算的类,分别是 BigInteger 和 BigDecimal。虽然这两个类也大致可以被归为包装类,但是它们其实并没有对应的基本类型。
这两个类都提供了一些方法来模拟基本类型的各种操作。也就是说,你能对 int 和 float 做什么,就能对 BigInteger 和 BigDecimal 做什么,区别只是你用方法代替了运算符而已。此外,由于涉及更多的计算量,导致的结果就是相关操作的效率有所降低。所谓“速度换精度”即是如此。
BigInteger 可以支持任意精度的整数。也就是说,在运算时你可以表示任意精度的整数值,而不用担心丢失精度。
BigDecimal 可用于任意精度的定点数(fixed-point number)。例如,你可以将其用于货币计算。
如果你想了解这两个类的更多细节,请参考 JDK 文档的相关描述。
3.2.3 Java 中的数组
许多编程语言都支持数组。然而在 C 和 C++ 里,因为数组的本质是内存块,所以使用数组是十分危险的。也就是说,如果 C++ 程序访问了数组边界之外的内存,或者在内存被初始化之前就对其进行操作(这个问题非常普遍),那么结果如何就难以预料了。
Java 的一个核心设计目的是安全,于是许多折磨 C 和 C++ 程序员的问题在 Java 里已经不复存在了。例如,Java 的数组一定会被初始化,并且无法访问数组边界之外的元素。这种边界检查的代价是需要消耗少许内存,以及运行时需要少量时间来验证索引的正确性。其背后的假设是,安全性以及生产力的改善完全可以抵消这些代价(同时 Java 也会优化这些操作)。
当你创建一个用于放置对象的数组时,实际上数组里包含的是引用,而这些引用会被自动初始化为一个特殊的值:null。Java 会认为一个值为 null 的引用没有指向任何对象,所以当你操作引用之前,需要确保将其指向了某个对象。如果你试图操作一个值为 null 的引用,系统会返回一个运行时报错。因此,Java 通过以上手段规避了那些常见的数组问题。
此外,你也可以创建一个放置基本类型的数组。编译器会确保对该数据进行初始化,并将数组元素的值设置为 0。
本书后续(尤其在第21章中)会对数组进行更为详细的介绍。

若有收获,就点个赞吧
0 人点赞
