Four Foundamental Algorithms

Training and Testing Data
Training and Testing Data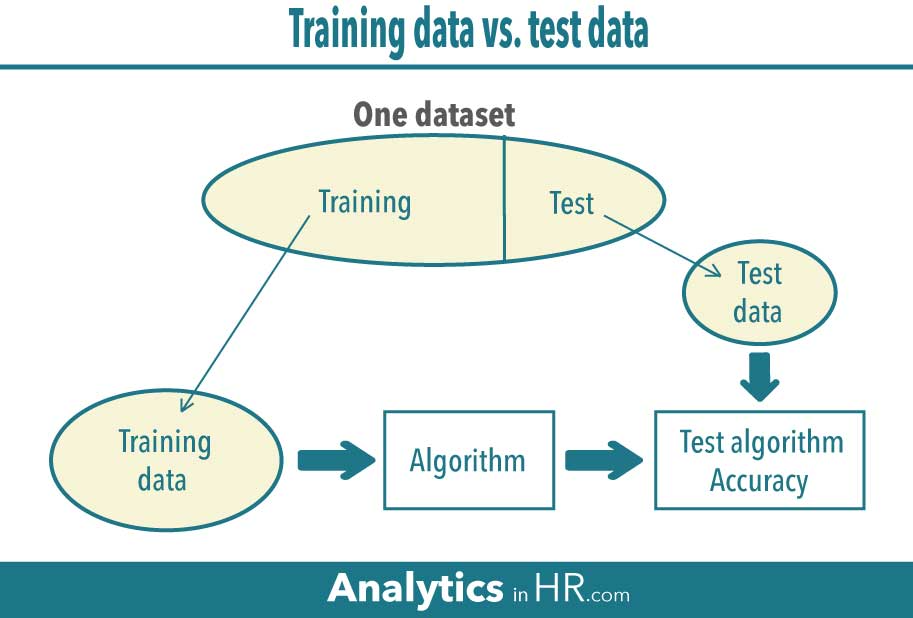
The Training Process
Training Process
ram
batches
epochs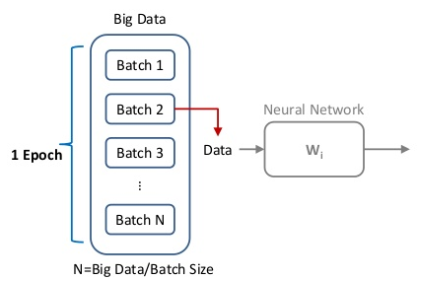
深度学习中的batch、epoch、iteration的含义
Input function
Tensorflow中的数据对象Dataset
https://www.w3cschool.cn/tensorflow_python/tensorflow_python-63xs2s6r.html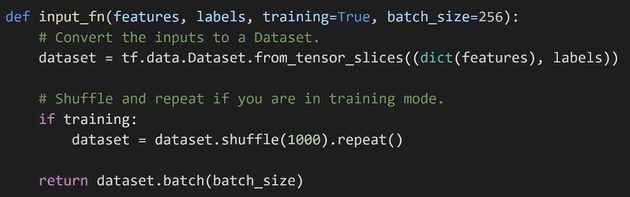
Classification
Building the Model

1.为什么要用lambda函数?
- 用lambda函数首先减少了代码的冗余,
- 其次,用lambda函数,不用费神地去命名一个函数的名字,可以快速的实现某项功能,
- 最后,lambda函数使代码的可读性更强,程序看起来更加简洁。
lambda [arg1 [,arg2,.....argn]]:expression
Clustering 聚类

k-means算法是常⻅的基于划分的聚类⽅法,其中相异度基于对象与类中⼼(簇中⼼)的距离计算,与簇中⼼距离最近的对象可以划为⼀个簇。 此算法⽬标是每个对象与簇中⼼距离的平⽅和最⼩。
K-means过程
KNN和K-means的K区别:
1. KNN:最近的K个值
2. K-means: 分成几类
K-Means聚类算法的局限:
- 非球形簇无法找到聚类簇
- 受初始值的影响大
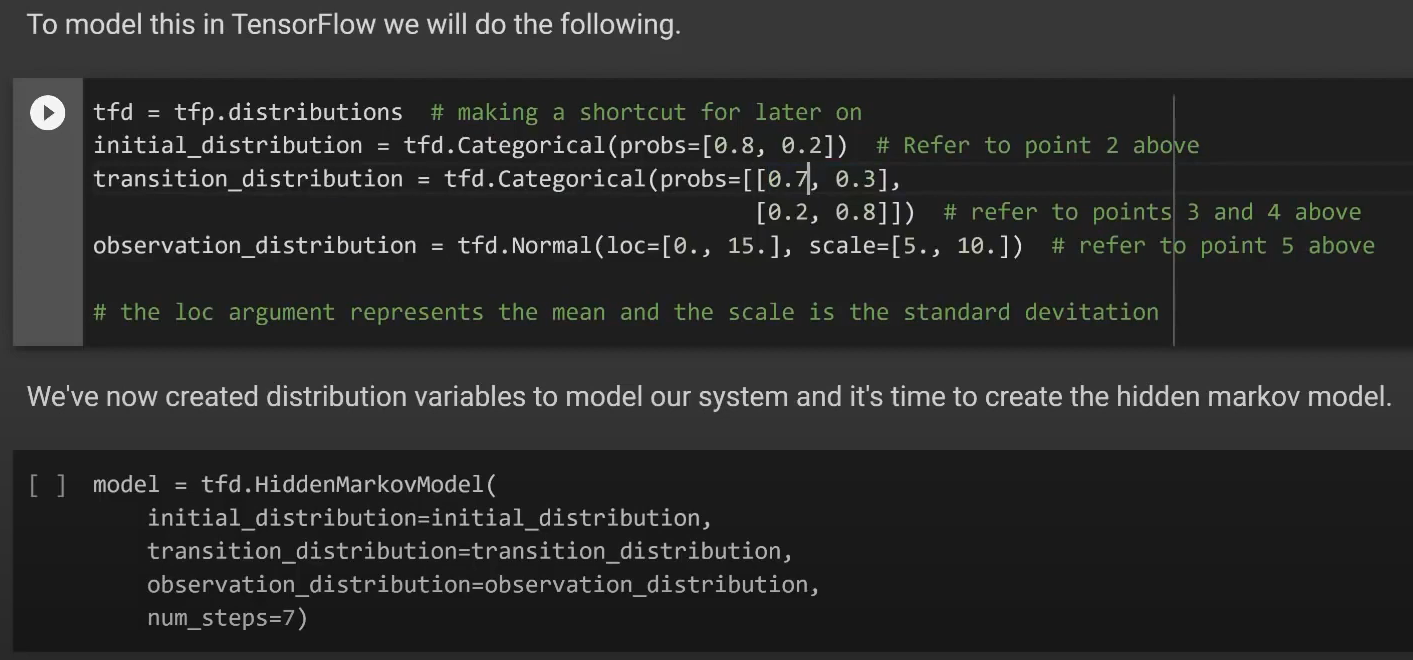
Hidden Markov Models 隐马尔可夫模型

马尔可夫性:现在决定未来

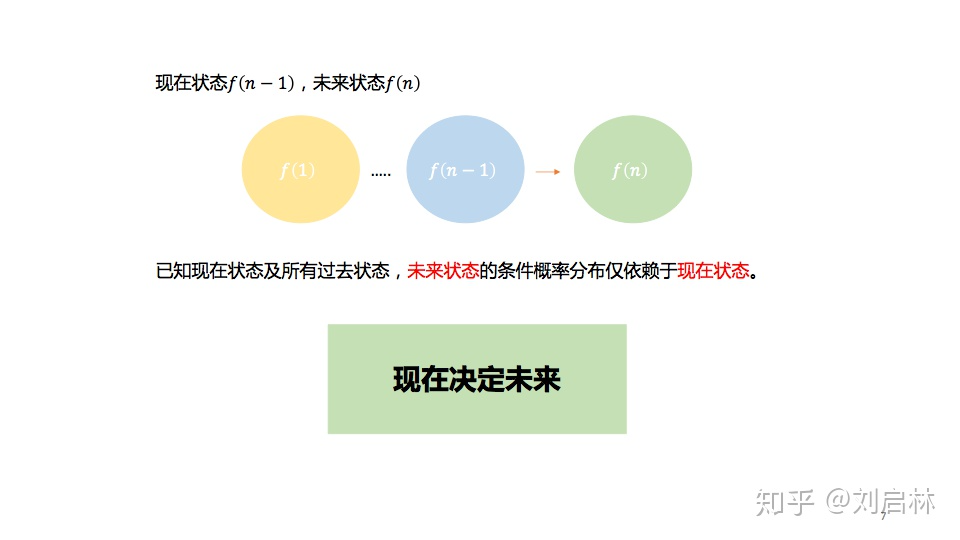
马尔科夫链

马尔科夫链计算

n次移动后,球的(状态)概率分布:
隐马尔可夫模型

与线性回归不同的是:It uses probability distributions to predict future events or states.
举例
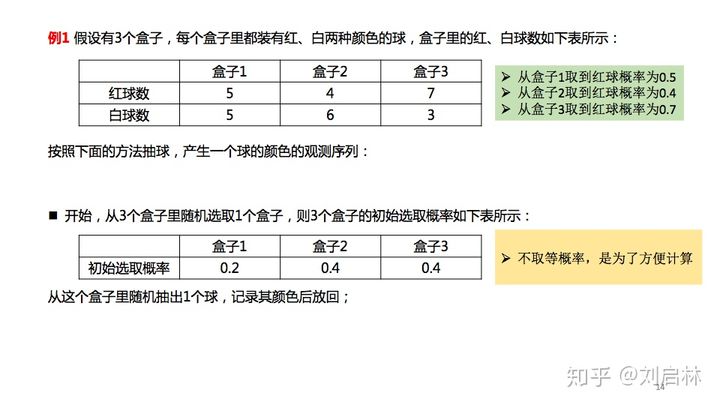

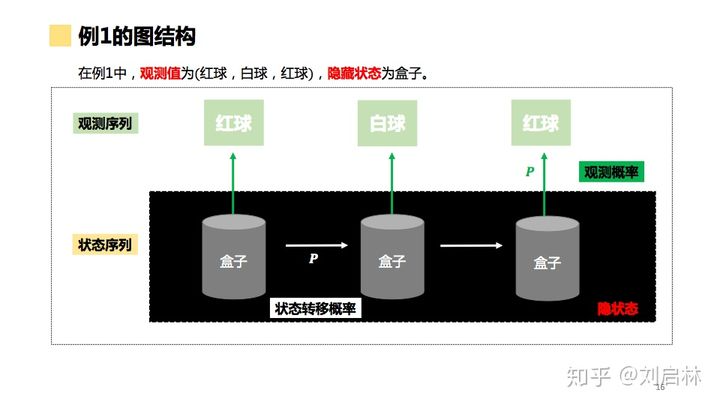
假设

图结构
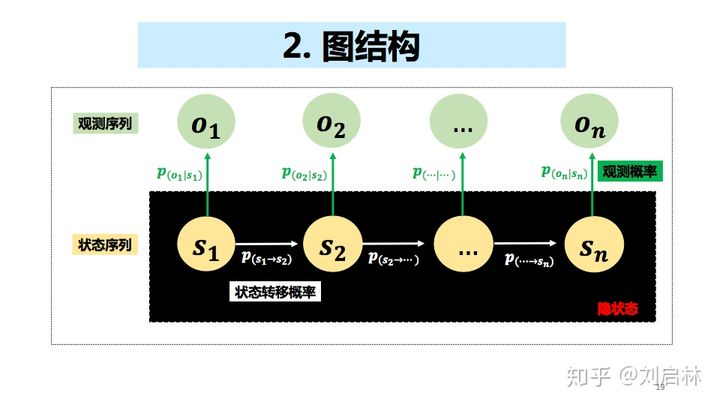
状态转移概率

观测概率

初始状态概率

联合概率分布

定义

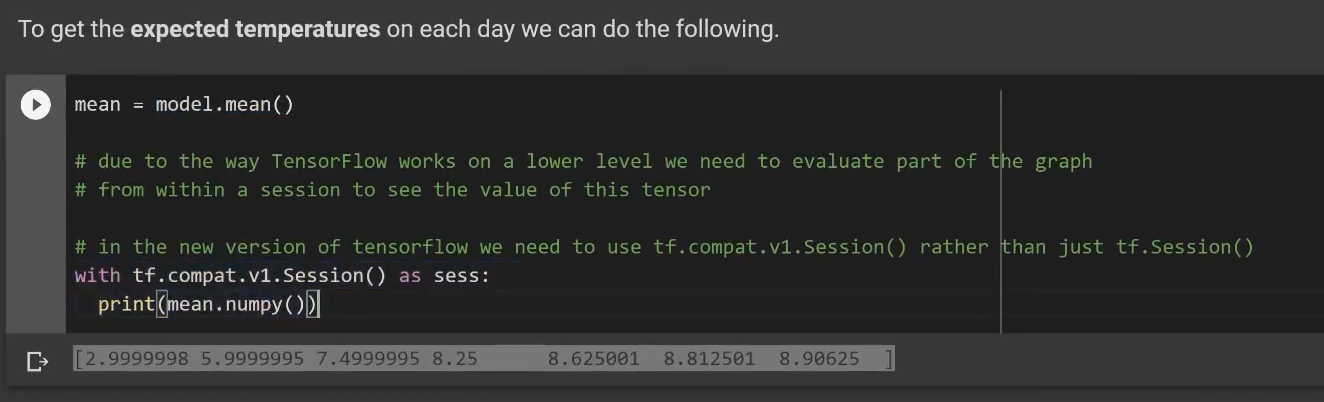
Using Probabilities to make Predictions



若有收获,就点个赞吧
0 人点赞
