BI概论

(不用背概念,注重理解)
商务智能概念的核心包括:数据,信息,知识,决策
商务智能系统的组成包括:
1. 数据管理(数据仓库)
2. 数据分析(数据挖掘)
3. 数据展现(可视化)
4. 业务处理(OLTP/OLAP)
OLAP和数据仓库
理解-事务型数据(库)与分析型数据(库),P37
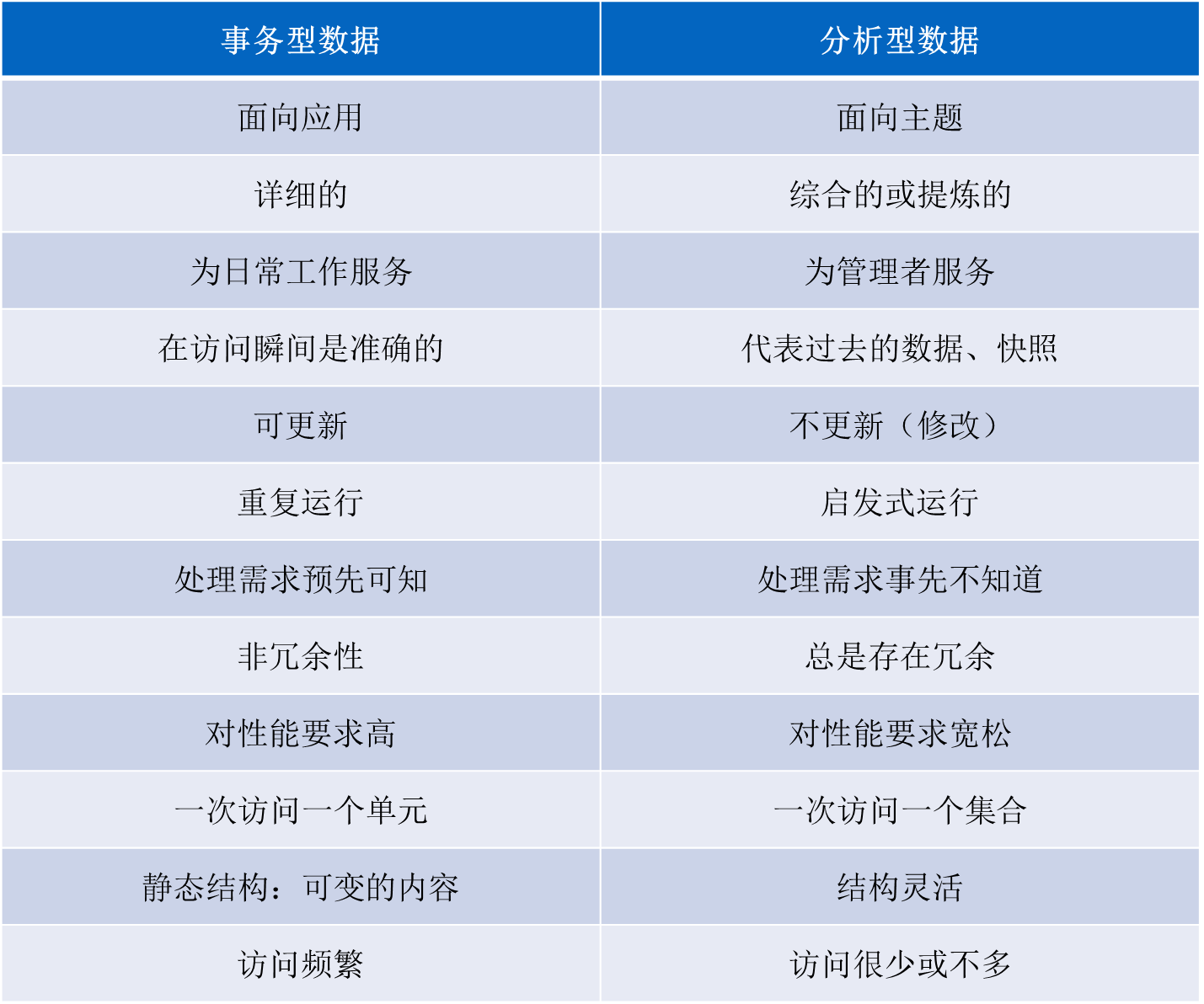
分析型数据的主要使用者:管理人员,分析人员
分析型数中有冗余是因为:提高查询效率,减少计算量
将不同数据源中的数据进行数据集成时,常常遇到哪些问题:
1. 数据类型不一致
2. 字段同名异义
3. 字段异名同义
4. 数据非结构化
在数据库设计时使用范式约减的目的是为了:防止出现数据的更新、查找、 删除异常,同时减少数据的冗余。(防止异常,减少冗余)
针对历史数据
①业务数据库是采用覆盖方式;
②分析数据库是采用用时间字段进行标记,追加的方式进行处理。
建立数据仓库主要是为了进行信息的快速查找,为决策支持提供服务,这和业务数据库是不同的。
理解-数据仓库的4个特点
面向主题 / 对应企业决策
2. 集成性 / ETL—>一致性
3. 稳定性 / 数据不常改变
4. 时变性 / 数据随时间变化⭐辨析-数据仓库与业务型数据库的区别,P45
OLTP和OLAP区别

联机事务处理OLTP(on-line transaction processing):OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
联机分析处理OLAP(On-Line Analytical Processing):OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。数据挖掘
概念理解:数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的数据中提取正确的、有⽤的、未知的、综合的以及⽤户感兴趣的知识并⽤于决策⽀持的过程。(数据中提取知识并用于决策)
数据清理处理内容:
- 格式标准化
- 异常数据清除
- 错误纠正
- 重复数据的清除
属于数据挖掘核心任务(分析方法)的是:分类,聚类,关联规则
分类和预测(监督学习)

训练样本:已经被分好类的数据
测试样本:未知类别的数据
特征:输入变量,即简单线性回归中的 x 变量
目标变量:进行分的类别
KNN(k-近邻法)
l k-最近邻算法采⽤测量不同特征值之间的距离⽅法进⾏分类
K表示:计算距离后取前k个最相似样本
关于数据空缺值的处理,做法可行的是
1. 丢弃整个属性
2. 丢弃整条记录
3. 想办法猜测空缺值
习题
对在手机卖场购买手机的客户进行调查,得到如下调查表。请使用 kNN 算法(k=3,曼哈顿距离)预测用户 K 会购买的手机品牌,写出计算过程。
找和K最近的3个点,取其目标变量
决策树

主要针对类别型特征划分,如果遇到连续型特征,需要对其进行“分裂”处理
信息增益
l 划分数据集的大原则:将无序的数据变得有序
l 在划分数据之前与之后信息所发⽣的变化称为信息增益(information gain)。
l 知道如何计算信息增益,就可以计算每个特征值划分数据集获得的信息增益,并选取信息增益最⾼的那个特征。
l 集合信息的度量⽅式称为熵(entropy), 代表数据集的无序程度
熵

H公式
计算信息增益
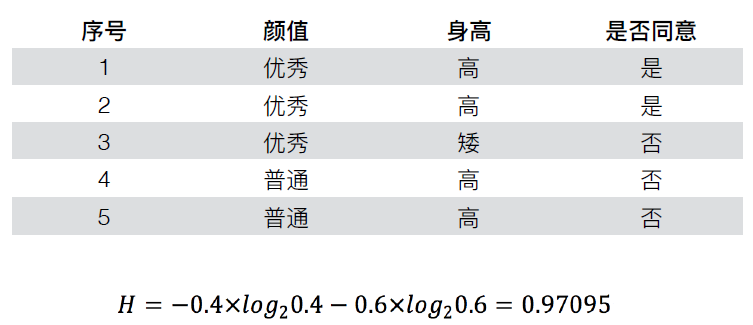
计算信息增益——按颜值划分
优秀组 普通组
H优秀组=3/5(-2/3log2(2/3)-1/3log2(1/3))
H普通组=2/5(0log20-log2(1))
H1= H优秀组 + H普通组
ΔH=H-H1
*计算信息增益——按身法划分
高个子组 矮个子组
log2(1)=0
习题
根据下列医疗诊断数据构造决策树,写出计算过程。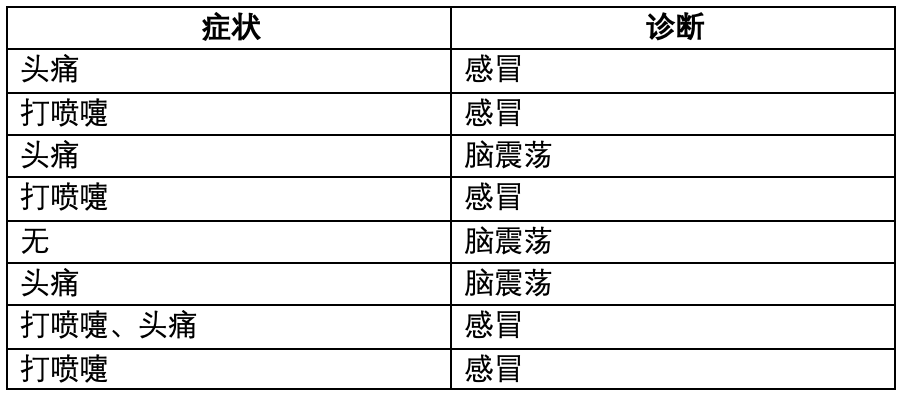
先判断目标变量:症状or诊断?
1. 进行预处理,将症状特征进行划分;
| 是否头疼 | 是否打喷嚏 | 诊断 |
|---|---|---|
| 1 | 0 | 感冒 |
| 0 | 1 | 感冒 |
| 1 | 0 | 脑震荡 |
| 0 | 1 | 感冒 |
| 0 | 0 | 脑震荡 |
| 1 | 0 | 脑震荡 |
| 1 | 1 | 感冒 |
| 0 | 1 | 感冒 |
2.分别计算划分前后的熵;
划分前:H划分前=
按头痛划分; H按头痛划分=
按打喷嚏划分:H按打喷嚏划分=

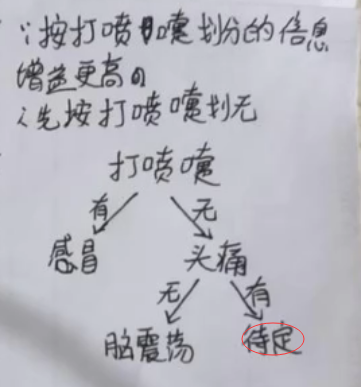
待定错误:2个脑震荡,1个感冒(选脑震荡)
聚类(非监督学习)
聚类就是把整个数据分成不同的组,并使组与组之间的差距尽可⼤,组内数据的差异尽可能小。(外部距离最大化,内部距离最小化)
- 聚类中心:簇的中心点
- 类大小:簇中数据数
- 类密度:簇面积内部点的密度
- 簇(Cluster):一个数据对象的集合
聚类分析
n 把一个给定的数据对象集合分成不同的簇;
l 聚类是一种无监督分类法: 没有预先指定的类别;
l 典型的应用
n 作为一个独立的分析工具,用于了解数据的分布;
n 作为其它算法的⼀个数据预处理步骤;
好的聚类——高质量的簇
l ⾼的簇内相似性
l 低的簇间相似性
计算距离


标称变量的距离——Jaccard

相似度:1/9(交集/并集)
距离:1-1/9=8/9
相似度与距离负相关
K-means聚类算法
k-means算法是常⻅的基于划分的聚类⽅法,其中相异度基于对象与类中⼼(簇中⼼)的距离计算,与簇中⼼距离最近的对象可以划为⼀个簇。 此算法⽬标是每个对象与簇中⼼距离的平⽅和最⼩。
K-means过程
KNN和K-means的K区别:
1. KNN:最近的K个值
2. K-means: 分成几类
K-Means聚类算法的局限:
l 非球形簇无法找到聚类簇
l 受初始值的影响大
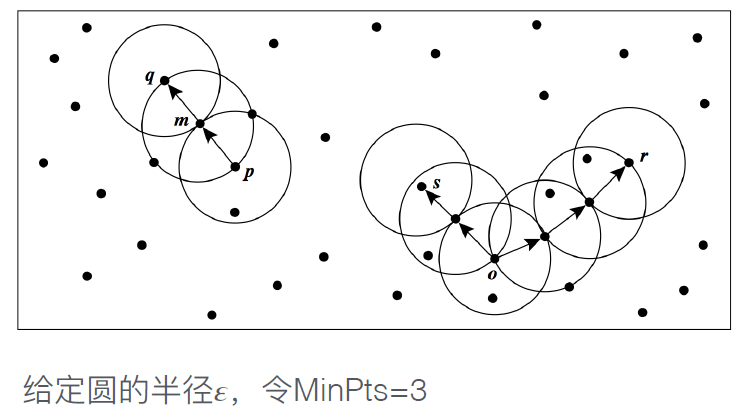
DBSCAN
是⼀种基于密度的空间聚类算法
将具有⾜够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
𝜀-邻域:给定对象o半径𝜀内的区域称为该对象的𝜀-邻 域。
核⼼对象:如果给定对象的𝜀-邻域内的样本点数⼤于等于MinPts,则称该对象为核⼼对象。
直接密度可达:给定⼀个对象集合D,如果p在q的𝜀-邻 域内,且q是⼀个核⼼对象,则我们说对象p从对象q出 发是直接密度可达的。显然,对象p是从另⼀个对象q 直接密度可达的,当且仅当q是核⼼对象,并且p在q的 𝜀-邻域中。
⭐聚类与分类的区别
l 与分类不同,在开始聚集之前⽤户并不知道要把数据分成几组,也不知分组的具体标准,聚类分析时数据集合的特征是未知的。
l 聚类根据⼀定的聚类规则,将具有某种相同特征的数据聚在⼀起也称为⽆监督学习。分类用户则知道数据可分为几类,将要处理的数据按照分类分入不同的类别,也称为有监督学习。
关联分析(非监督学习)
频繁模式:频繁地出现在数据集中的模式 (如项集、⼦序列或⼦结构)
关联规则挖掘可发现大型数据项集之间有趣的关联和关系。
规则显示项集在事务中发生的频率。
典型的例子是市场分析。
关联规则

Support Count 支持计数 ( ) –项集出现的次数
) –项集出现的次数

⭐支持度,置信度


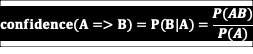

- 项的集合称为项集。
- 包含k个项的项集称为k项集。
- 项集的出现频度:包含项集的事务数。简称项集的频度、⽀持度计数或计数。
频繁项集:如果项集I的⽀持度满足预定义的最小支持度阈值,则I是频繁项集。
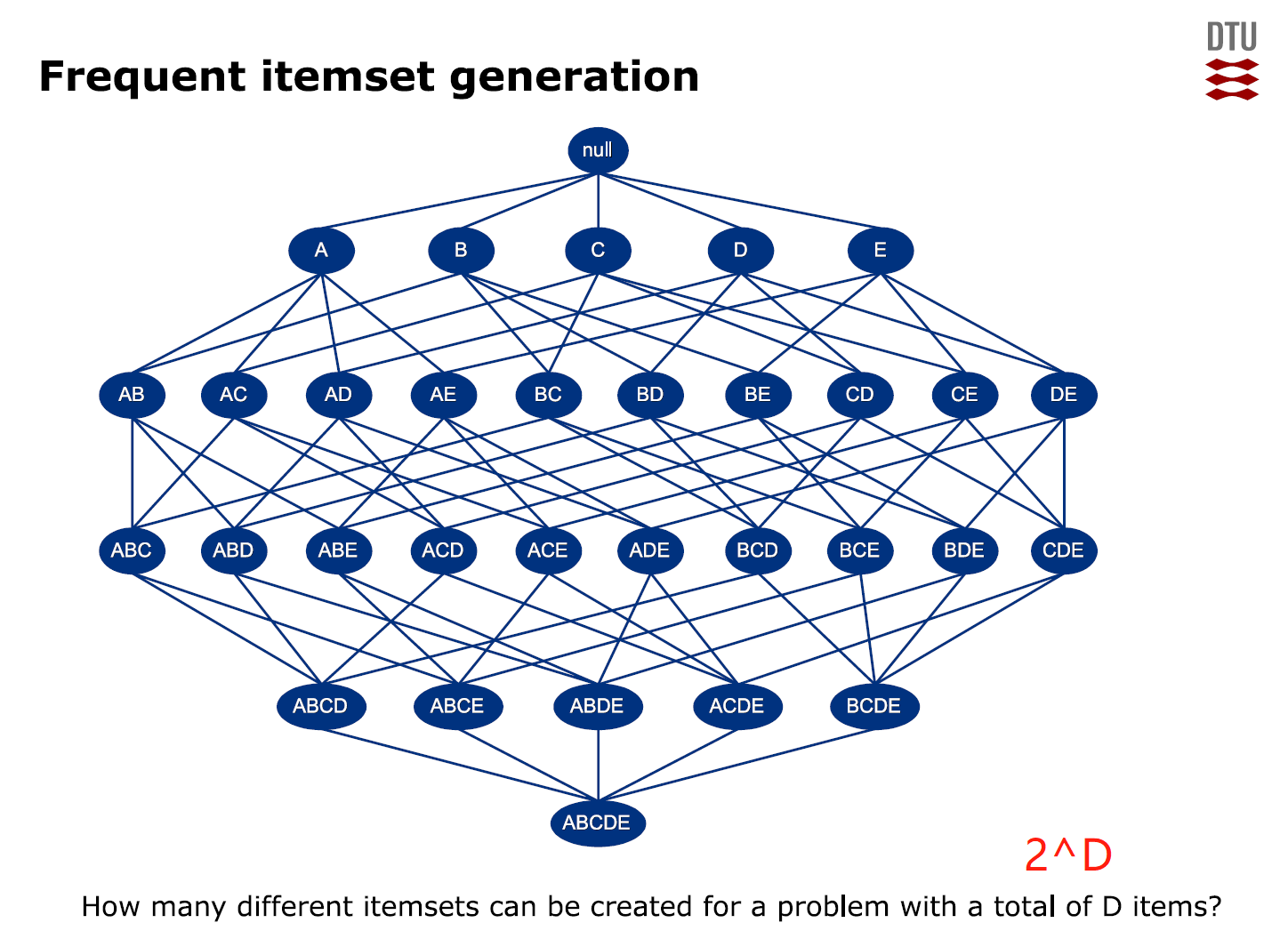
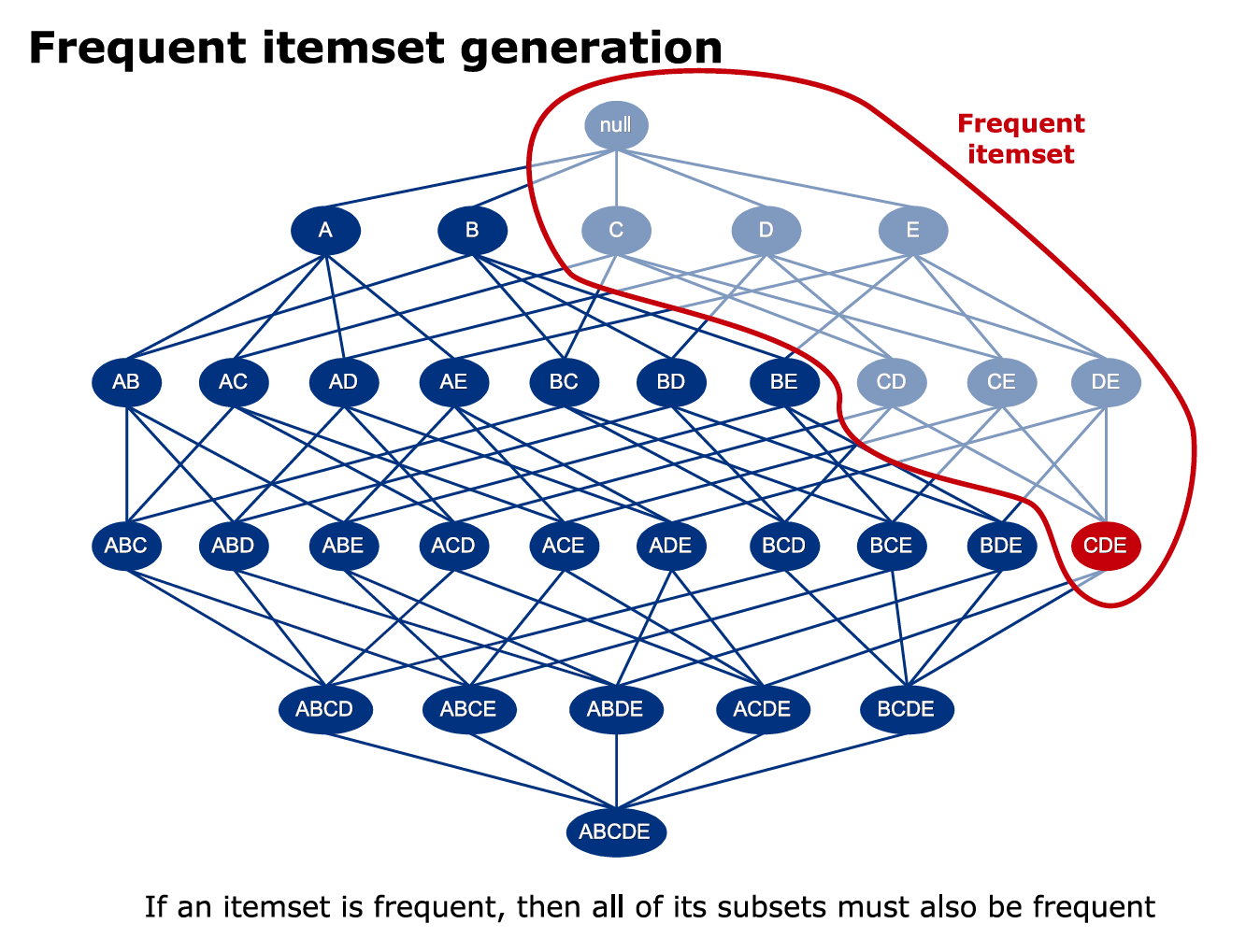
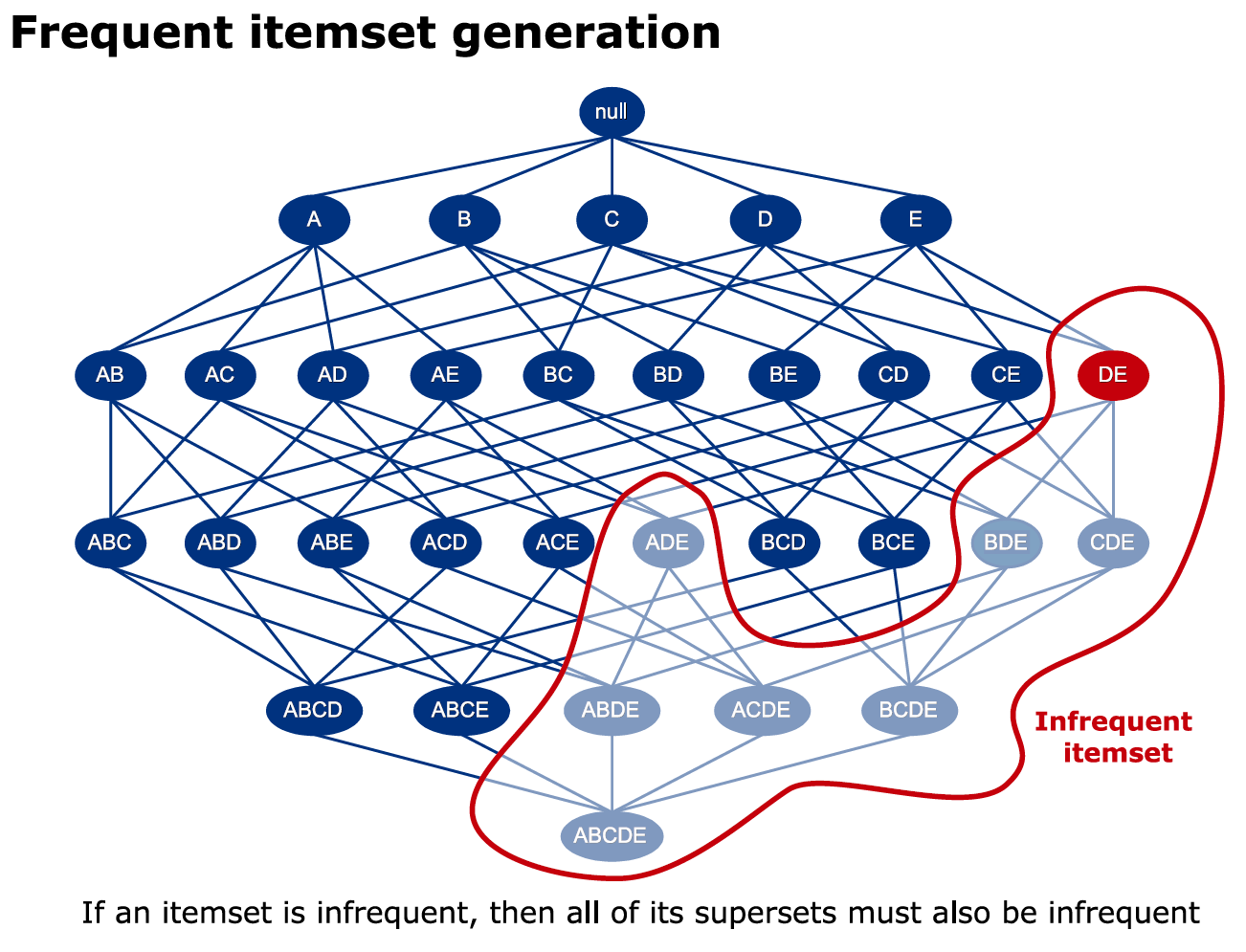
⭐Apriori算法
Apriori算法的主要思想为:首先找出所有频繁性至少和预定义的最小支持度一样的频繁项集,由频繁项集产生满足最小支持度和最小可信度的强关联规则,然后使用频繁项集产生期望的规则,产生只包含集合的项的所有规则,每一条规则的右部只有一项。一旦这些规则生成,那么只有那些大于用户给定的最小可信度的规则才被保留。
Apriori算法使⽤⼀种先验性质:频繁项集的所有⾮空⼦集也⼀定是频繁的。
换⾔之,⾮频繁项集的超集⼀定是⾮频繁的。

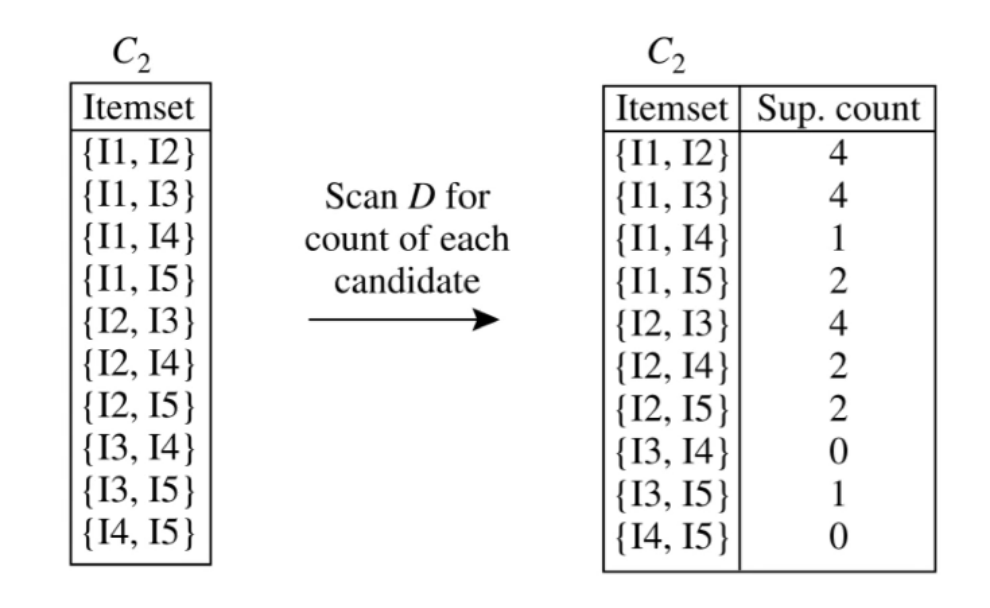
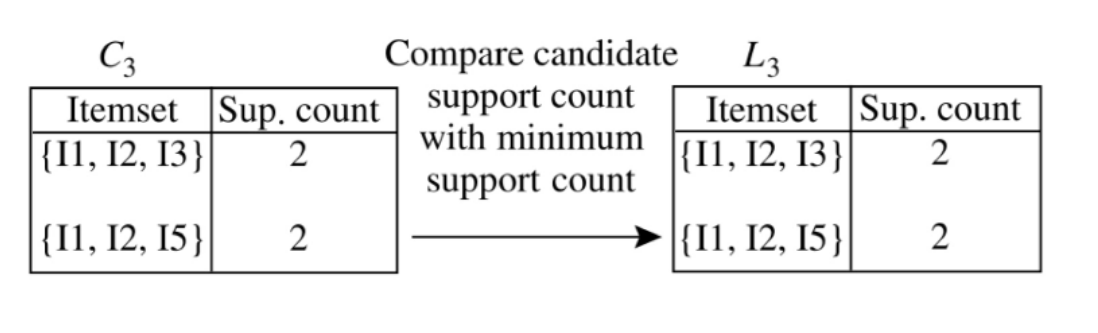
找到符合min_sup = 2(最小支持度)的C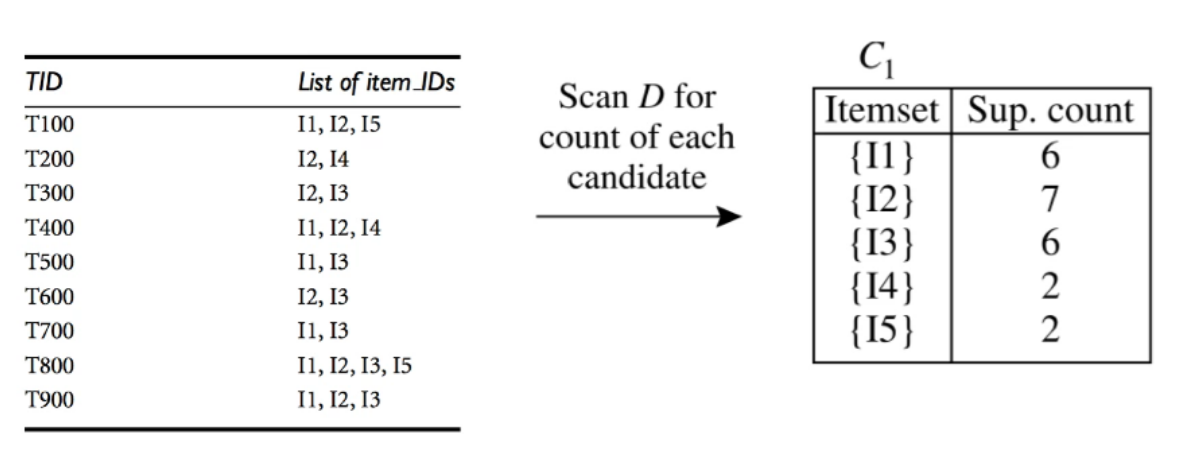
检验筛选


可视化
为什么要可视化?——有效抓住注意力,快速传达信息
各类图的使用场景:
柱状图
l 柱状图采用长方形的形状和颜色编码数据的属性。
l 柱状图每根直柱内部也可单独使用另外的数据属性进行编码,称为堆叠图(Stacked Graph)
饼图
l 用扇形角度呈现各个分量在整体中的比例
直方图
l 直方图是对数据集的某个属性的频率统计,取值范围映射到横轴,并分割为多个子区间。每个子区间用一个直立的长方块表示,高度正比于属于该属性子区间的数据点的个数。
l 直方图可以呈现数据的分布、离群值和数据分布的模态
折线图
散点图
l 表达二维数据的标准方法。
l 通常在散点图中绘制参考线表达分布趋势。
地图
箱形图
1. 在所有视觉元素中,人眼对颜色最为敏感×
2. 全班同学的期末考试成绩属于有序型数据×
3. 电话号码属于数值型数据×
4. 可视化是商务智能的最终目标×
推荐系统
协同过滤Collaborative Filtering-CF
协同过滤分析⽤户兴趣,在⽤户群中找到指定⽤户的相似(兴趣)⽤户,综合这些相似⽤户对某⼀信息的评价,形成系统对该指定⽤户对此信息的喜好程度预测。
核心思想:借鉴和你相似人群的观点来进⾏推荐。
协同:基于其他⽤户进⾏推荐
协同过滤利用用户社区的⼒量来帮助进⾏推荐,存在⼀些问题
1. 数据稀疏(对于大多数推荐系统,⽤户和商品很多,但是用户评级的平均商品数⽬很少)
2. 扩展性(如果有100万个用户,每次推荐都要计算近100万次距离,每秒需要多次推荐的话,计算量⾮常巨大(延迟性差)
3. 冷启动问题:协同过滤倾向于推荐流行事物。如果一个物品是新发布的,从没被人评过分,那么它永远不会被推荐。
协同过滤分类

User-based CF
方法1:基于距离判断相似性
l 曼哈顿距离
公式:|x1-x2|+|y1-y2|
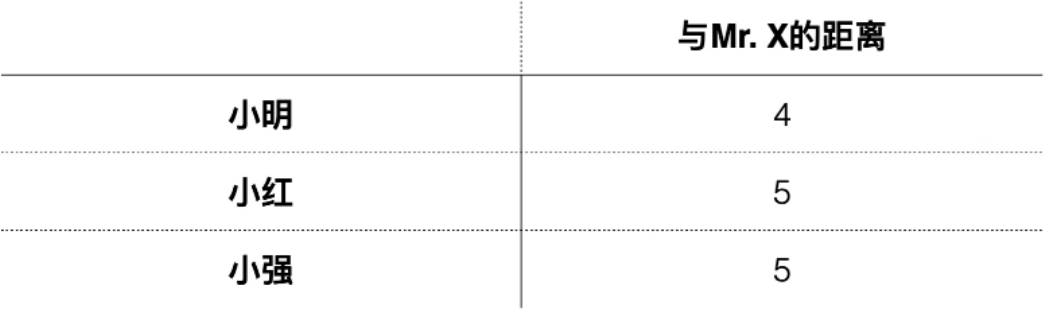
l 欧式距离
公式: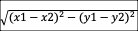
距离法问题
1.曼哈顿与欧式距离的一致性(不同算法的结果一致性不一)
2.__缺失值(不好操作)
3.用户评价的行为差异(不同用户使用不同评分范围,极端、中庸情况)
4.用户的“怪癖”行为——偏差
方法2:皮尔逊系数
l 数据⼀致性可⽤⽪尔逊相关系数表达。(上述问题3的解决)
l ⽪尔逊相关系数是⽤于度量两个变量相关性的指标
l 取值区间为[-1, 1]
l 计算公式如下: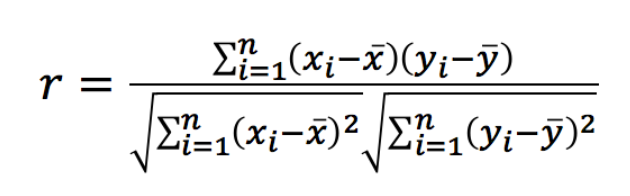

方法3:余弦相似度
稀疏数据的解决:余弦相似度
余弦相似度会忽略数据集中的0-0匹配
取值范围为[-1, 1],1表示完全相似,-1表示完全不相似,定义如下: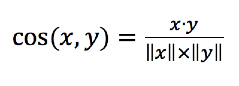
其中·表示内积计算,||x||表示向量⻓度,定义为 :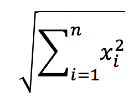
方法4:K近邻
解决用户“怪癖”行为
方法选择建议:
l 如果数据稠密(⼏乎所有属性都没有缺失值)且属性值⼤⼩⼗分重要,那么使⽤距离法;
l 如果数据受到评分虚⾼(即不同⽤户使⽤不同的评分范围)的影响,则使⽤⽪尔逊相关系数;
l 如果数据稀疏,考虑使⽤余弦相似度;
Item-based CF
l 基于物品的过滤:找到最相似的两件物品:Item1 和Item2,如果某个⽤户对Item1评价较⾼,那么把 Item2推荐给该⽤户。
l User-based FC也称为基于内存的FC,因为必须要保存所有的评级结果来进⾏推荐。
l Item-based FC也称为基于模型的FC,因为不需要保存所有的评级结果,仅需构建⼀个模型来表示物品间的相似程度。
基于改进余弦相似度的过滤(不⽤背公式)
为抵消⽤户夸大评级的效果,改进余弦相似度将从 每个评级结果中减去平均的评级结果


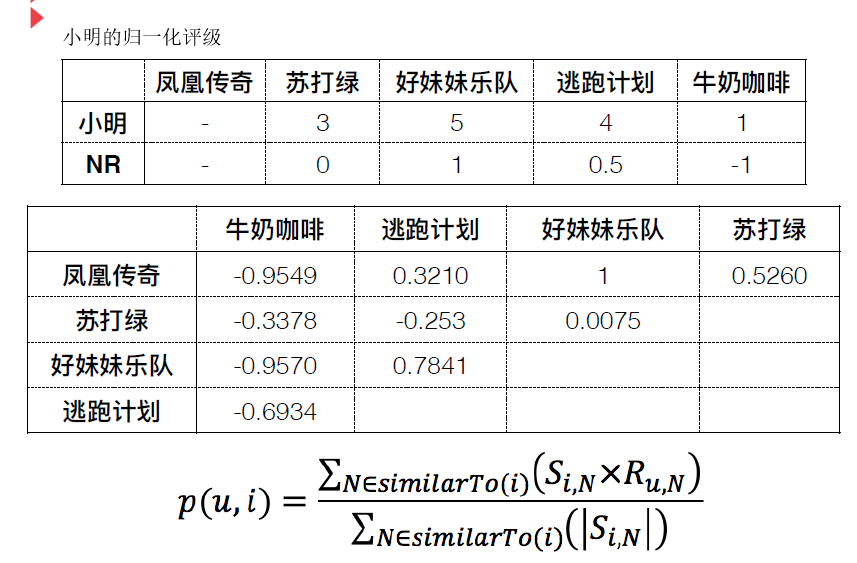
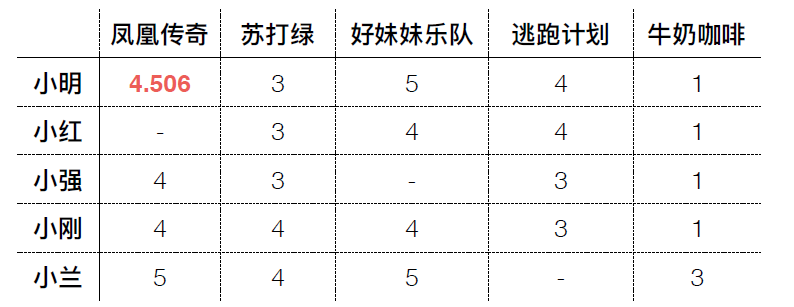
User-based CF问题
问题:不公平——距离计算,编号时产生亲疏远近
网络——社交网络
图——基本概念
l 边:⽤两个顶点来表达,如(_v_1,_v_2)
l 度的分布: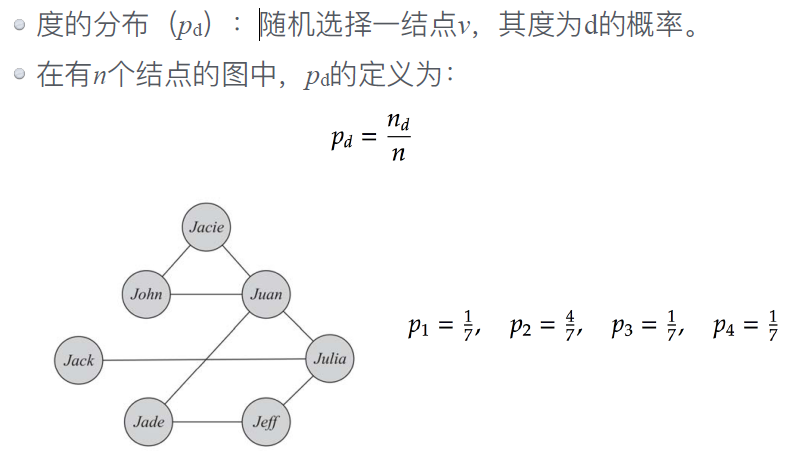
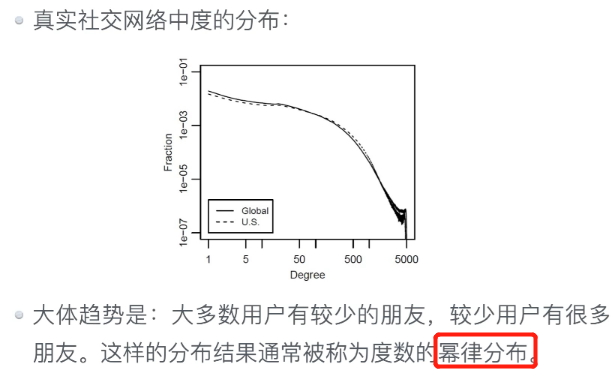
长尾定律
★ 图的表达
l 邻接矩阵
l 邻接列表
l 边列表
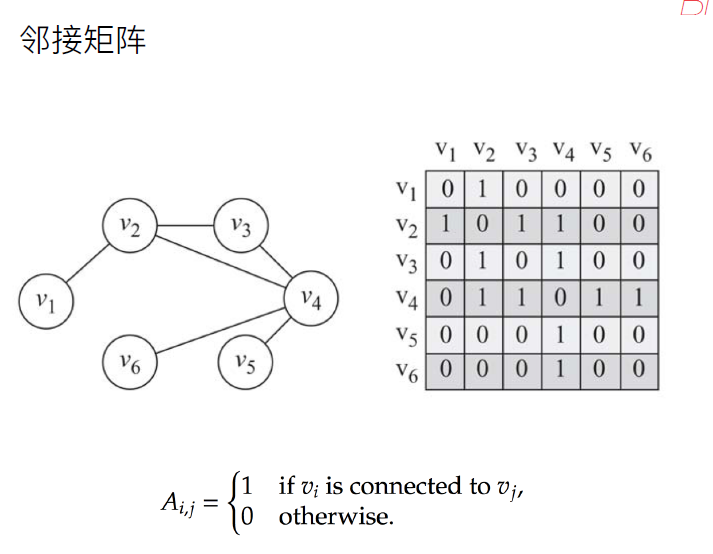
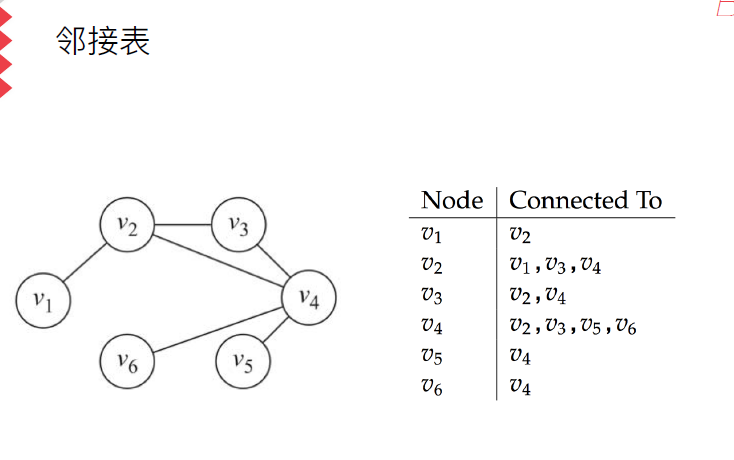
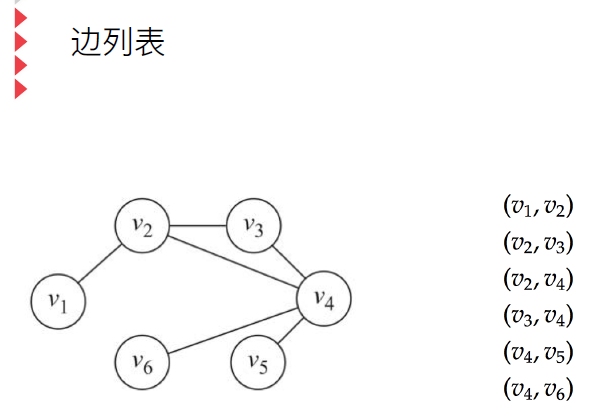
图的连通性


网络

中心性



传递性
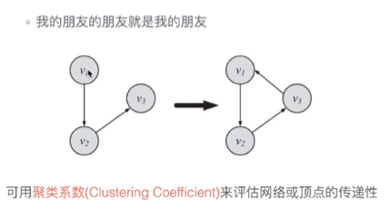
三角关系
全局聚类系数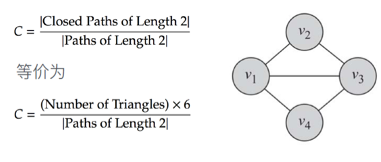
C=26/26+2+2=0.75(三角形包含的L2边数+v2,1,4-v4,1,2andv2,3,4-v4,3,2)
局部聚类系数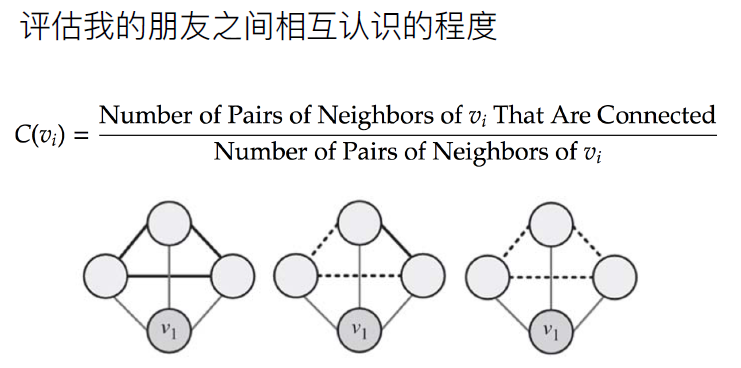
★聚类系数真题

l 全局聚类系数
1*6/(6+2+2+2+2)=3/7
v1,3,4-v4,3,1 and v2,3,4-v4,3,2 and v4,5,2-v2-5-4 and v5,4,3-v3,5,4
l 平局局部聚类系数
v1=1/1, v2=1/3, v3=1/3, v4=0/2, v5=0/2
(1+1/3+1/3)/5=1/3
有几个邻居(分母),邻居间有几对好友关系(分子)
平均即局部聚类系数相加再除以节点数
相似性
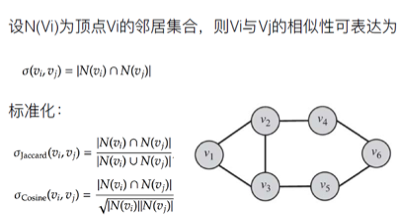
网络模型
如何评价模型模拟的准确性?
三个定量化指标:
l Degree Distribution(度的分布):描述顶点的度在网络中如何分布
l clustering coefficient(聚类系数):描述网络的传递性
l average path length(平均路径长度):描述网络顶点之间的平均距离
★真实世界的⽹络
l 幂律分布(二八分布,马太效应)
l 聚类系数高
l 平均路径长度短
★理解三个模型各⾃的特点
l 随机图模型(random graph model)
l ⼩世界模型(small world model)
l 优先连接模型(preferential attachment model)
随机图的度满⾜泊松分布(不满⾜幂律分布)
小世界模型更类似于泊松分布,⽽不是幂律分布
当新的结点加入网络时,它们更倾向于连接那些与网络中较多结点连接的结点 新结点与已有结点的连接概率与已有结点的度成正比。换言之,富者更富。
随机-小世界-优先
12,1,2
考察网络的度的分布
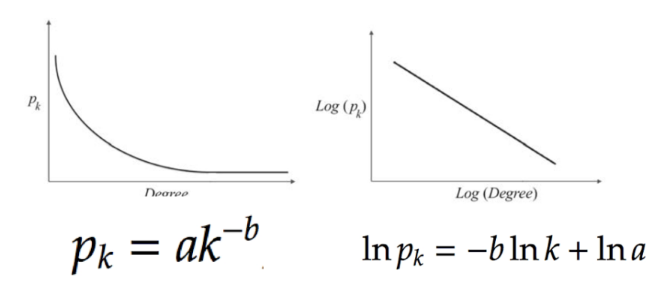

随机图模型(random graph model)



基于随机图的真实世界网络建模
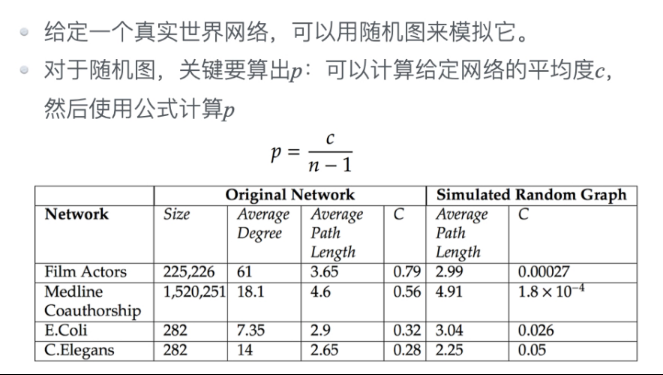
film actiors: 61/225,226=0.00027
社区分析
★显式社区与隐式社区

社区发现的⽬的:挖掘出隐式社区
我们对两种社区感兴趣:
l 社区中有特殊成员(基于成员的社区发现);
l 社区本身有特殊形式(基于群组的社区发现)。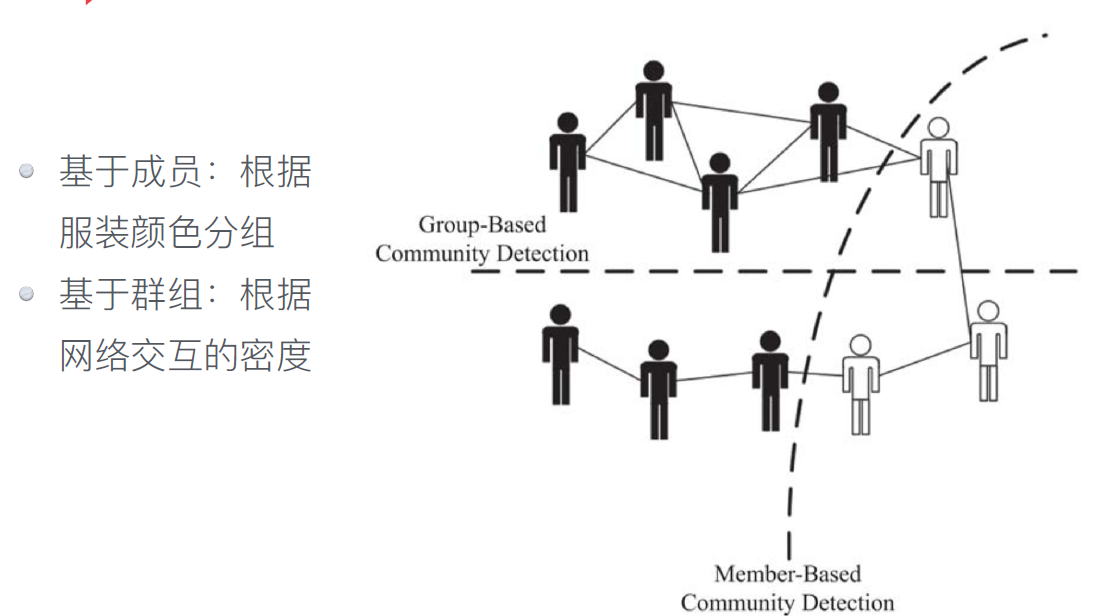
(延伸内容:结点度可在网络分析文档P69查看)
基于成员的社区发现
l 具有相同特征的成员更有可能在同⼀个社区。
l 有三个结点特征经常被使⽤于搜索⼦图并构成社区:结点相似度、结点度、结点可达性
结点度
l 基于结点度这个特征,在⽹络中最常搜索的⼦图是团(clique)
l 团是⼀个最⼤完全⼦图,⼦图中所有结点对都是互相连接的。
l ⼤⼩为k的团是由k个结点组成的⼦图,其中所有结点的度为k-1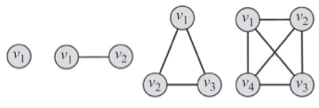
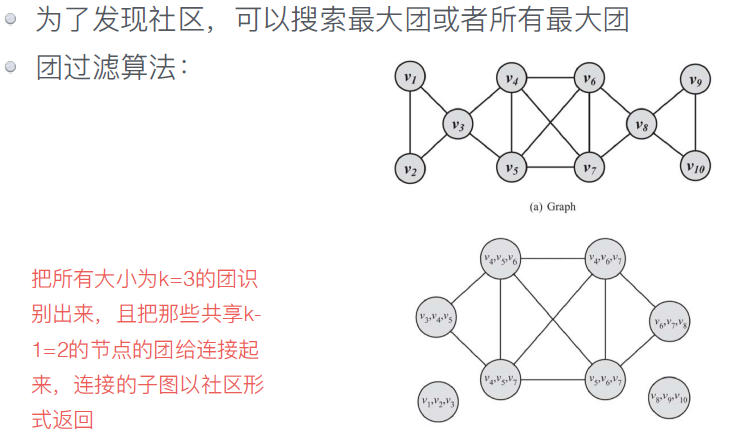
★社区演变
l 大规模的社交⽹络通常是⾼度动态的,结点和边会随着时间出现或消失
l 演变⽹络中常⻅的模式:分裂、致密化、缩径
网络分裂
在演变的⽹络中,⼤规模的⽹络随时间变化分解为三个部分:
l 巨大结构:当⽹络连接趋于静⽌时,会形成⼀个巨⼤的结点集,通常包含很⼤⼀部分结点和边
l 星状结构:⽹络中孤⽴的部分构成星状结构,是带有⼀个内部结点和n个叶⼦结点的树形结构
l 单元素:与⽹络中其他结点不相连的孤⽴结点
★致密化

网络收缩
Web挖掘
web内容挖掘(文本,多媒体)、web结构挖掘(URL,内外部结构)、web使用挖掘(两种模式追踪)
Web挖掘的过程主要分为以下步骤:
l 数据获取
l 数据预处理
l 模式识别
l 模式分析
l 可视化
web内容挖掘
主要包括 ⽂本挖掘 和 多媒体 挖掘两类,其挖掘对象包括⽂本、图像、 ⾳频、视频和其他各种类型的数据。
Web⽂本挖掘
针对包括Web⻚⾯内容、⻚⾯结构和⽤户访问信息等在内的各种Web数据,应⽤数据挖掘⽅法发现有⽤的知识帮助⼈们从⼤量Web⽂档集中发现隐藏的模式。
l ⽂本概括:从⽂本(集)中抽取关键信息,⽤简洁的形式总结⽂本(集)的主题内容。例如搜索引擎在向⽤户返回查询结果时,通常需要给出⽂本摘要。
l ⽂本分类:把⼀些被标记的⽂本作为训练集,找到⽂本属性和⽂本类别之间的关系模型,然后利⽤这种关系模型判断新⽂本的类别。
l ⽂本聚类:根据⽂本的不同特征划分为不同的类。
l 从⼤量⽂档中发现⼀对词语出现模式的关联分析以及特定数据在未来的情况预测。




实验题
关联分析
l 置信度conf: 有百分之多少的…
l 提升度-相关性系数Lift : P(A,B)/(P(A)P(B)) Lift=1时表示A和B独立。这个数越大(>1),越表明A和B存在于一个购物篮中不是偶然现象,有较强的关联度.
l 杠杆效应-影响力Leverage : P(A,B)-P(A)P(B),Leverage=0时A和B独立,Leverage越大A和B的关系越密切
l 确信度Conviction : P(A)P(!B)/P(A,!B),用来衡量A和B的独立性,这个值越大,A和B越关联

若有收获,就点个赞吧
0 人点赞
